- @xiangxueerfei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
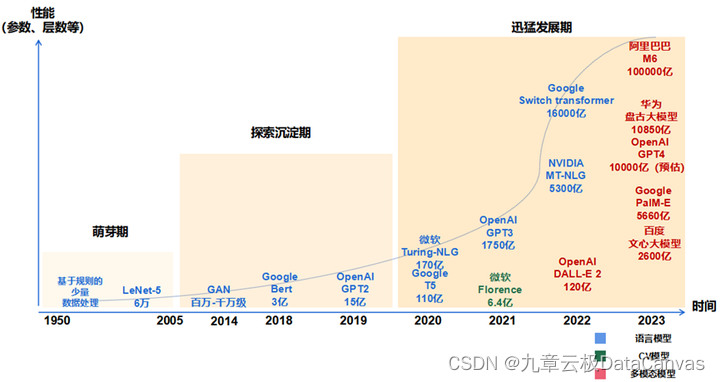
本文简要介绍下基于LLaMA-Factory的llama3 8B模型的微调过程。

上一篇文章我们介绍了如何利用 Ollama+AnythingLLM 来实践 RAG ,在本地部署一个知识库。借助大模型和 RAG 技术让我可以与本地私有的知识库文件实现自然语言的交互。前排提示,文末有大模型AGI-CSDN独家资料包哦!本文我们介绍另一种实现方式:利用 Ollama+RagFlow 来实现,其中 Ollama 中使用的模型仍然是Qwen2我们再来回顾一下 RAG 常见的应用架构。
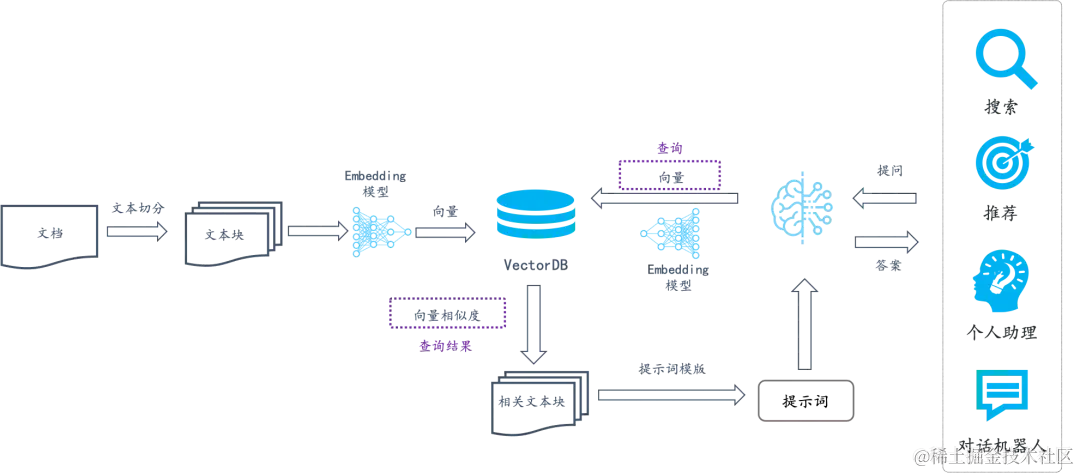
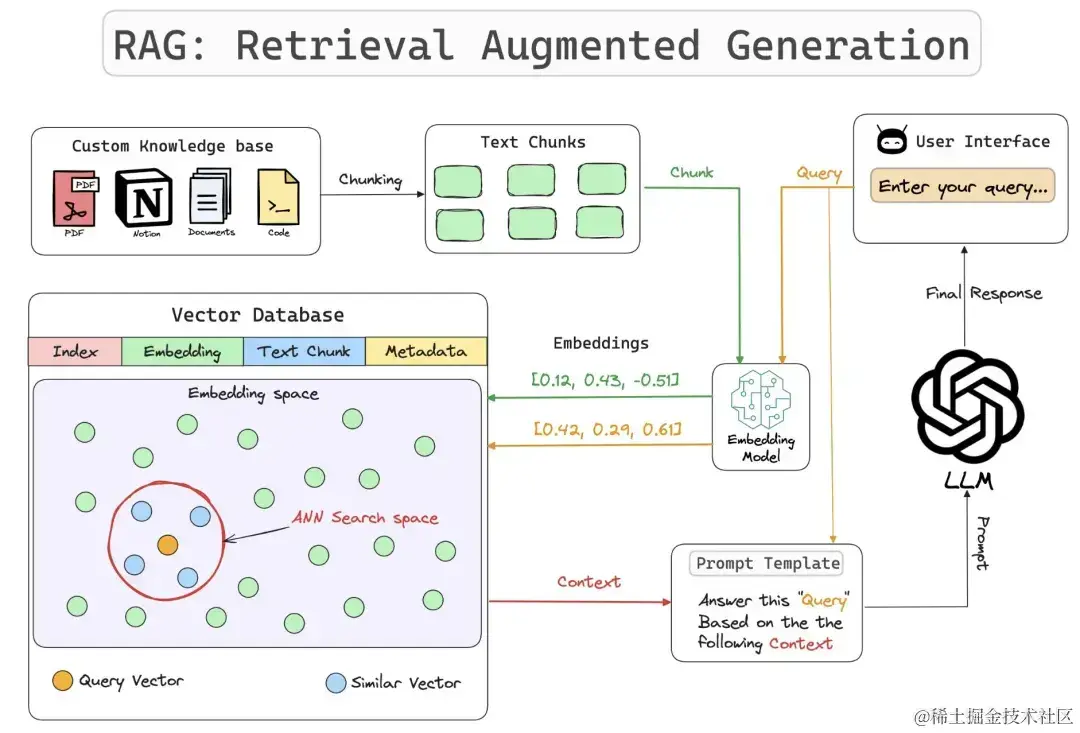
RAG,即检索增强生成(Retrieval-Augmented Generation),是一种先进的自然语言处理技术架构,它旨在克服传统大型语言模型(LLMs)在处理开放域问题时的信息容量限制和时效性不足。RAG的核心机制融合了信息检索系统的精确性和语言模型的强大生成能力,为基于自然语言的任务提供了更为灵活和精准的解决方案。前排提示,文末有大模型AGI-CSDN独家资料包哦!
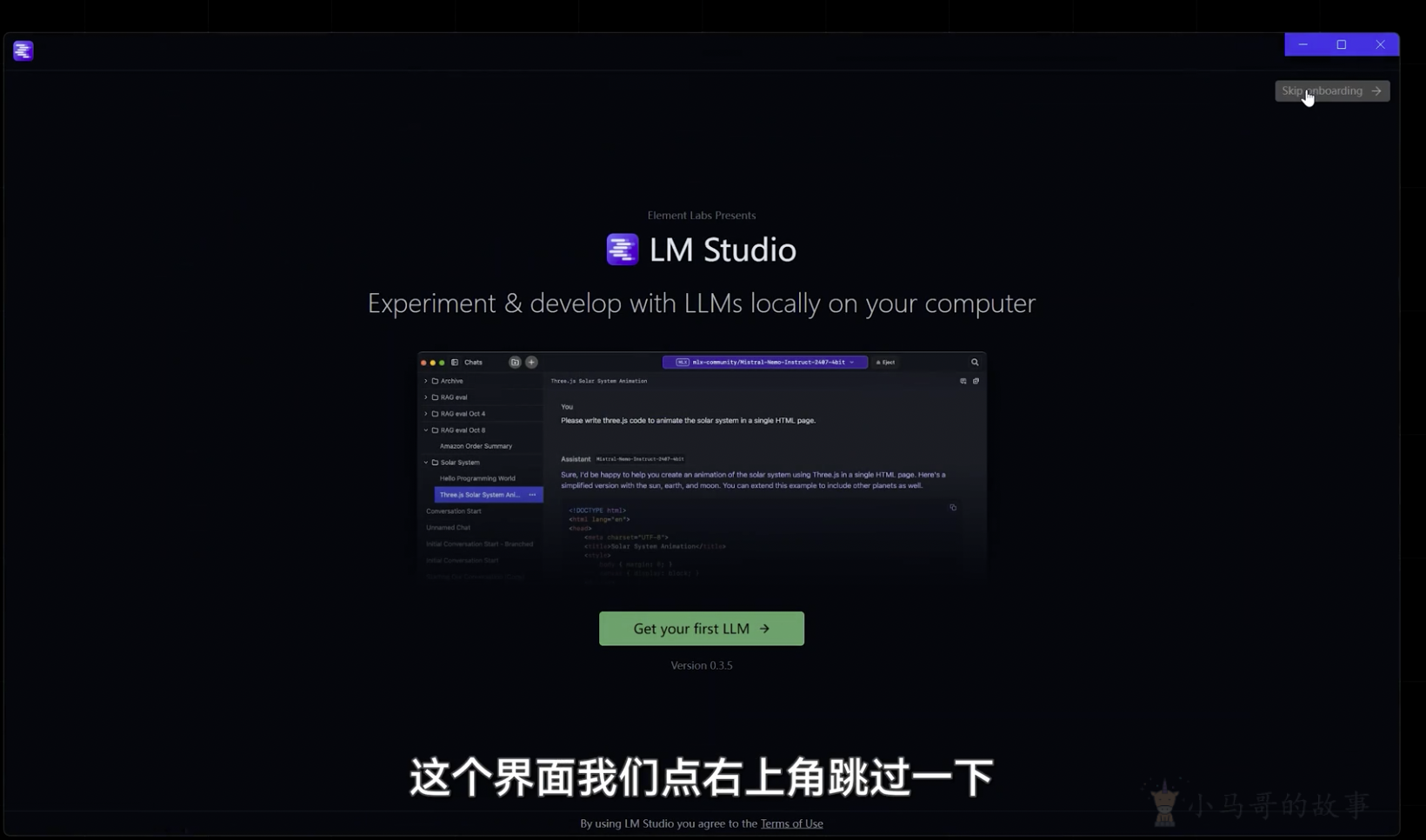
LM Studio 是一款用于在您的电脑上开发和实验LLMs的桌面应用程序。前排提示,文末有大模型AGI-CSDN独家资料包哦!关键功能桌面应用程序,用于运行本地 LLMs一个熟悉的聊天界面搜索和下载功能(通过 Hugging Face 🤗)一个可以监听类似 OpenAI 端点的本地服务器本地模型和配置管理系统。
微调模型涉及调整预训练或基础模型的参数,使其能够用于特定任务或数据集,从而提升其性能和准确性。这个过程包括为模型提供新的数据,并修改其权重、偏差和某些参数以最小化损失和成本。通过这样做,这个新模型可以在任何新任务或数据集上表现良好,而无需从头开始,从而节省时间和资源。通常,当一个新的大型语言模型(LLM)创建时,它会在一个大型文本数据语料库上进行训练,其中可能包含潜在有害或不良内容。在预训练或初始
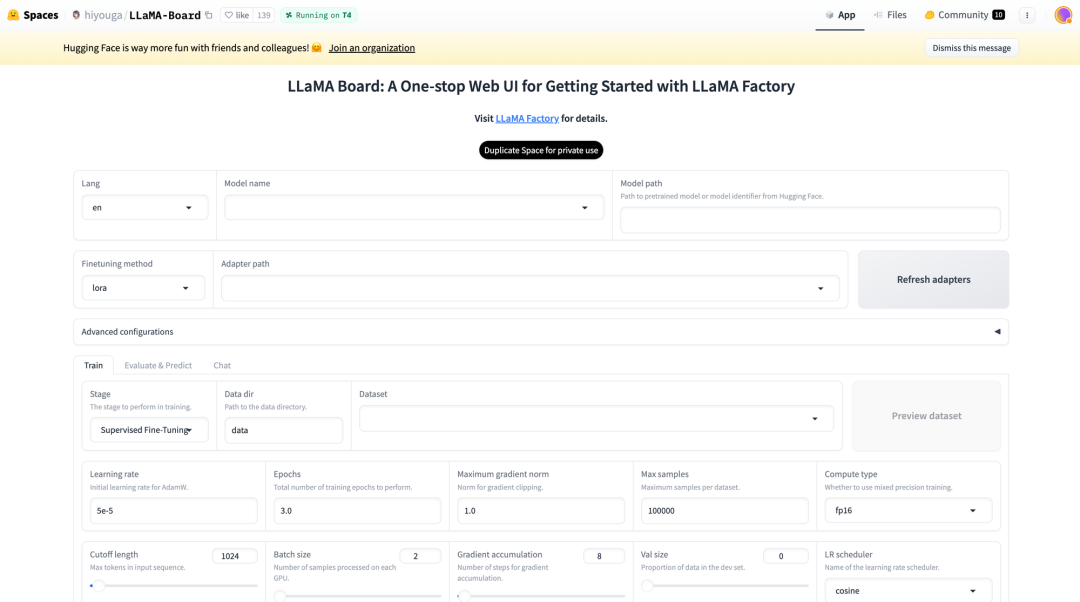
在这个信息爆炸的时代,人工智能技术正以前所未有的速度渗透到我们生活的方方面面。从智能手机上的语音助手到自动驾驶汽车,AI的应用无处不在。而在这些令人惊叹的技术背后,大语言模型(LLM)扮演着至关重要的角色。它们不仅能够理解和生成自然语言,还能在多种场景下提供智能决策支持。然而,对于许多对AI感兴趣的新手来说,大语言模型的训练和应用似乎是一件高不可攀的事情。复杂的技术术语、晦涩的理论知识,以及高昂的
大模型泛指能够理解、生成自然语言的大规模语言模型,借助深度学习技术,通过对大规模的文本乃至多模态数据进行预训练与微调,获得语言的理解与生成能力。GPT是目前最广为人知的大模型之一,能够处理以前难以解决的复杂语言任务,美国开放人工智能研究中心(OpenAI)于2022年推出了ChatGPT(Chat Generative Pre-trained Transformer),其一经发布就很快受到广大用户
总的来说,这篇文章主要是为了对主流机器学习算法进行扫盲,下一步我还会对三类应用场景的算法,进行一一拆解,你们希望了解哪些算法知识,可以分享到评论区,欢迎共创共赢。希望带给你一点启发,加油。
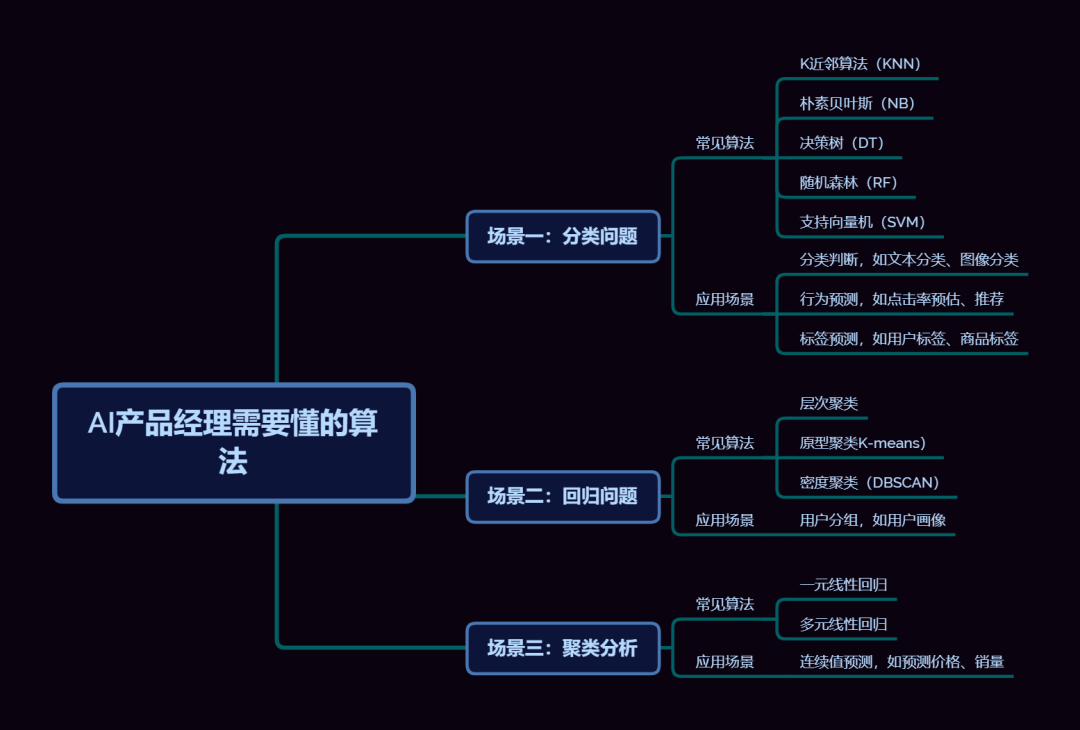
虽然对于大多数人来讲,由于我们的电脑配置等原因,部署本地大模型并且达到很好的效果是很奢侈的一件事情。但是这并不妨碍我们对其中的流程和原理进行详细的了解读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用如果你是零基础小白,想快速入门大模型是可以考虑的。一方面是学习时间相对较短,学习内容更全面更集中。二方面是可以根据这些资料规划好学习计划和方向。包括:大模型学习线路汇总、学习阶段,大模型
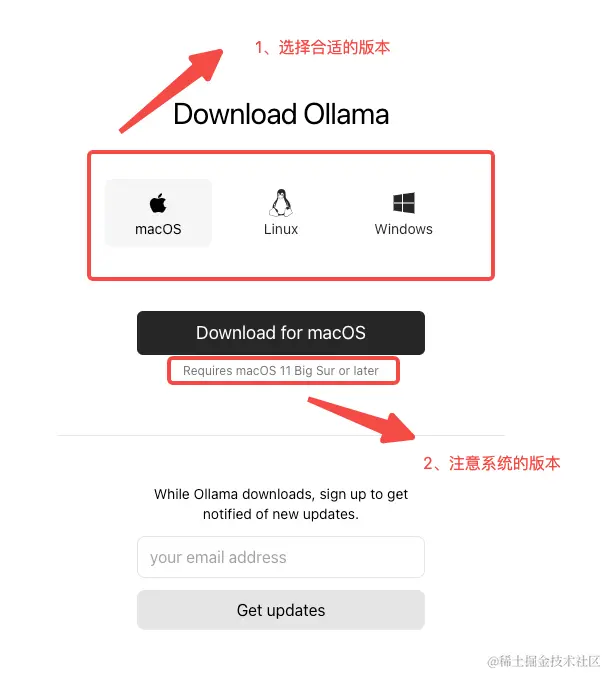
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。