- @wyg_031113
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
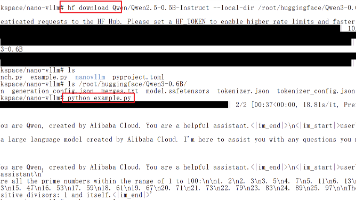
本文介绍了在优云智算GPU云平台上部署nano-vllm模型的完整流程。首先需选择适配cuda12、torch2.4和python3.10的镜像环境,重点通过清华镜像源安装系统依赖(git、ninja-build等)和Python包(transformers、nvitop等)。特别提示flash_attn应直接下载预编译的whl文件而非源码编译以节省时间。接着使用huggingface-cli下载
另外,提到的Adam优化算法虽然主要讲优化方法,但可以结合MLE和MAP的目标函数进行参数更新,例如在训练中结合正则化项(如权重衰减)时,实际是在进行MAP估计。好的,我现在需要回答关于最大似然估计(MLE)和最大后验估计(MAP)的问题,同时说明它们在深度学习中的应用并举例。总结结构:定义MLE和MAP,区别与联系(频率vs贝叶斯,先验的作用),在深度学习中的应用(损失函数对应MLE,正则化对应

通过以上实例可以看出,条件概率和贝叶斯定理在实际问题中具有广泛的应用价值。医学诊断:根据患者的症状和检测结果,计算患病的可能性。自然语言处理:根据文本特征和语料库,预测文本的主题或情感。机器学习:朴素贝叶斯分类器利用贝叶斯定理进行分类预测。学习这些概念时,建议结合具体问题进行练习,并逐步深入理解其背后的数学原理和应用场景。希望这个入门级教程能帮助你更好地掌握条件概率与贝叶斯定理!
目前已经学完深度学习的数学基础,开始学习各种 模型和网络阶段,给出一个从简单到入门的,层层递进的学习路线。并给出学习每种模型需要的前置知识。增加注意力机制,bert, 大模型,gpt, transformer, MOE等流行的模型。另外,前置知识详细一点,加上需要前置学习的模型。并分析每种模型的使用场景,优缺点。

从入门到精通卷积神经网络(CNN),着重介绍的目标函数,损失函数,梯度下降 标量和矩阵形式的数学推导,pytorch真实能跑的代码案例以及模型,数据,预测结果的可视化展示, 模型应用场景和优缺点,及如何改进解决及改进方法数据推导。

DeepSeek V3和R1分别代表了通用大模型与专用推理模型的技术巅峰。V3通过MoE架构和FP8训练实现高效多任务处理,而R1以强化学习突破复杂推理瓶颈。两者结合,既满足大规模商业应用需求,又为高难度学术问题提供解决方案,标志着AI模型从“规模竞赛”向“效率与能力并重”的转型。未来,其开源策略和低成本优势或进一步加速AI技术的普及与创新。

OpenAI Codex 功能开关状态概览 该文档详细分类了 OpenAI Codex 的各项功能状态,分为四个主要类别: 稳定版功能(🟢):包含15个成熟可用的核心功能,如跨应用操作(apps)、浏览器控制(browser_use)、高性能模式(fast_mode)等,适合生产环境使用。 开发中功能(🟡):列出18个正在开发的功能,如灵活补丁应用(apply_patch_freeform)、
导数:衡量单变量函数变化率。偏导数与梯度:多变量函数的局部变化率与全局方向。链式法则:反向传播的数学基础,逐层计算梯度。梯度下降法:利用负梯度方向更新参数,最小化损失函数。通过理解这些概念并实践代码示例,可掌握深度学习优化算法的数学本质。
激活函数输出范围梯度特性计算成本适用场景Sigmoid(0,1)最大0.25高二分类输出层Tanh(-1,1)最大1.0高RNN隐藏层ReLU[0, +∞)0或1低通用隐藏层Leaky ReLU(-∞, +∞)0.01或1低避免神经元死亡Softmax[0,1] (概率)依赖输入分布高多分类输出层。
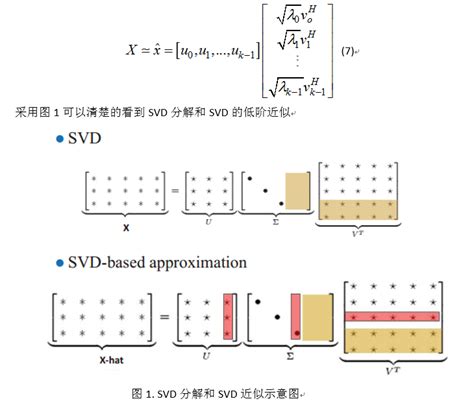
奇异值分解(SVD)是一种强大的线性代数工具,不仅在理论上有重要意义,还在实际应用中展现了广泛的应用价值。通过学习SVD,可以更好地理解矩阵的性质及其在深度学习中的作用。希望以上内容能帮助你掌握SVD的基础知识,并理解其在深度学习中的重要性。SVD(奇异值分解)是一种重要的降维技术,广泛应用于多个领域,包括推荐系统、图像处理、文本挖掘等。SVD作为一种经典的降维技术,因其简单性和高效性,在多个领域