- @weixin_70758133
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
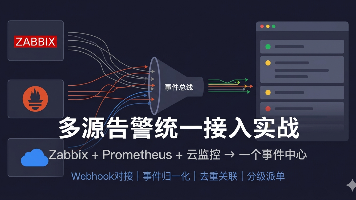
Zabbix管着网络设备和服务器、Prometheus管着容器和中间件、阿里云/腾讯云监控管着云上ECS——3套工具各发各的告警,值班人要同时盯3个渠道,重复告警没人去重,跨系统的关联故障没人能串起来。本文从一个真实的"3套监控并存"环境出发,完整实现多源告警统一接入:Zabbix Webhook配置、Prometheus Alertmanager对接、云API告警回调,统一写入事件总线做归一化处
ELK开源免费,但两年半下来我们算了一笔账:服务器、存储、人力——加上3次凌晨紧急处理和1次静默丢数,总成本超40万。我们把ELK自建、阿里云SLS和冠服云EMS三套方案放在同一条"日志→告警→工单→闭环"链路上实测,结论是:日志管理的真正成本不在采集和存储,而在出问题时能多快从日志里找到答案。本文不是ELK劝退文,但如果你排查故障要在多个系统间切来切去,这篇文章可能帮你省下一年的加班。

K8s环境下的可观测性选型,Prometheus免费但告警→工单链路靠自建,Datadog全但账单按容器数算一跑就爆,EMS一体化但深度日志分析弱于ES。本文把三套方案放在同一套K8s集群(50节点/300Pod)里实测:指标采集、日志关联、告警→工单闭环、月度成本四个维度逐项对比。不堆功能清单,只讲跑完一个月后真正影响决策的4个差距。适合正在选型K8s可观测性方案的运维/DevOps团队参考。

告警来了,人还在切系统查日志、凭经验猜根因——这个过程吃掉MTTR的60%。本文复盘我们上线AI智能告警的完整路径:多源数据聚合→LLM根因推断(支持ChatGPT/Claude/DeepSeek/Ollama)→L1全自动/L2确认/L3审批三级分级执行。不堆功能清单,只讲落地中真正有用的三个设计决策和两个踩坑。适合正在评估AIOps的运维团队参考。
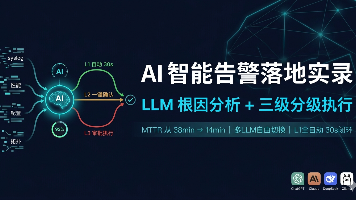
告警来了,人还在切系统查日志、凭经验猜根因——这个过程吃掉MTTR的60%。本文复盘我们上线AI智能告警的完整路径:多源数据聚合→LLM根因推断(支持ChatGPT/Claude/DeepSeek/Ollama)→L1全自动/L2确认/L3审批三级分级执行。不堆功能清单,只讲落地中真正有用的三个设计决策和两个踩坑。适合正在评估AIOps的运维团队参考。
用Excel+MySQL搭CMDB做了三年,资产表47张、字段破千、更新靠人肉。一次审计发现:32%的服务器IP已变更但CMDB未同步,18%的资产找不到负责人,最老的一条记录是2019年的——设备早报废了。三套方案放同一链条实测:iTop学习成本高、自建维护成本失控,平台化CMDB的关键差异不是"能存多少字段"——是数据能不能自己活下去。本文附最小CMDB数据模型+审计清单,适合正在评估CMDB

大多数团队评估日志方案时第一反应是"ELK开源免费",但两年半下来我们算了一笔账:服务器、存储、人力——以及3次凌晨紧急处理、1次静默丢数和一次ES集群升级回滚。我们把ELK自建、阿里云SLS和冠服云EMS日志模块三套方案放在同一条"日志→告警→排查→工单→闭环"链路上实测,结论是:日志管理的真正成本不在采集和存储,而在"出问题时你能多快从日志里找到答案"。本文不是ELK劝退文——如果你的团队有能
大多数团队评估日志方案时第一反应是"ELK开源免费",但两年半下来我们算了一笔账:服务器、存储、人力——以及3次凌晨紧急处理、1次静默丢数和一次ES集群升级回滚。我们把ELK自建、阿里云SLS和冠服云EMS日志模块三套方案放在同一条"日志→告警→排查→工单→闭环"链路上实测,结论是:日志管理的真正成本不在采集和存储,而在"出问题时你能多快从日志里找到答案"。本文不是ELK劝退文——如果你的团队有能
Zabbix Webhook + Flask脚本 + Alertmanager + 企业微信机器人——这套告警归集方案跑了18个月,处理了超过4万条告警。但随着客户环境从30台设备增长到200+、告警源从3个变成7个、值班团队从2人变成6人轮转,脚本维护的隐性成本开始超过当初省下的钱。本文记录了我们从开源拼装方案迁移到冠服云EMS平台ITOM模块的完整过程:为什么要迁、怎么评估平台方案、迁移步骤、

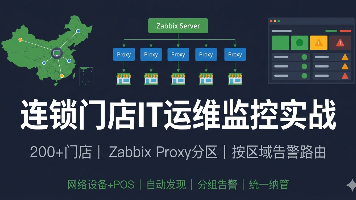
连锁门店的IT运维最大的问题不是技术难度,是规模乘以分散——200家门店,每家门店一台路由器、一台交换机、2-3台POS机、1台收银服务器,加起来就是1000+设备散布在不同城市,网络质量参差不齐,出了问题店员只会说"网断了"。本文给出我们实际跑通的方案:Zabbix Proxy分区域部署+门店设备自动发现+按区域/门店分组告警路由,附完整配置文件和自动化注册脚本。