




- @weixin_55939638
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过Knife4j + OpenAPI 自动生成请求代码后端接口文档与前端请求代码的强一致性。前端开发者零手写请求函数,只需关注业务逻辑。类型安全,IDE 智能提示,减少低级错误。接口变更时,一键同步,极大提升协作效率。在 AI 辅助编程越来越普及的今天,这种自动化工具依然有着不可替代的价值——它保证了代码的确定性和可控性。当你需要快速迭代、多人协作时,这套方案能让团队如虎添翼。赶快在你的项目中试
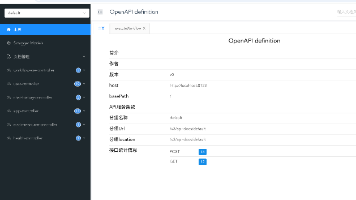
前端:vue3后端:spring 框架

时间过的真快,转眼之间一个学期即将结束,想必这个时候大家都在准备各科的课设作业,本期内容是我的数据结构课设,希望能给大家带来帮助,如果有任何不足或需要改进的地方,欢迎各位提出宝贵的意见。屏幕录制2023-12-24 13.43.01。

Hugging Face 是一个集成了大量预训练模型、数据集和其他资源的开源社区,专注于自然语言处理(NLP)。它为开发者和研究人员提供了方便的工具,可以快速使用并微调大规模预训练的 NLP 模型。通过与库的紧密集成,Hugging Face 极大地简化了 NLP 项目的开发过程,降低了门槛。Hugging Face 提供的工具和资源极大简化了 NLP 模型的使用和微调过程。通过 Hugging

我衷心希望这篇关于使用PyTorch进行线性回归模型训练的博客文章能够对您有所帮助。
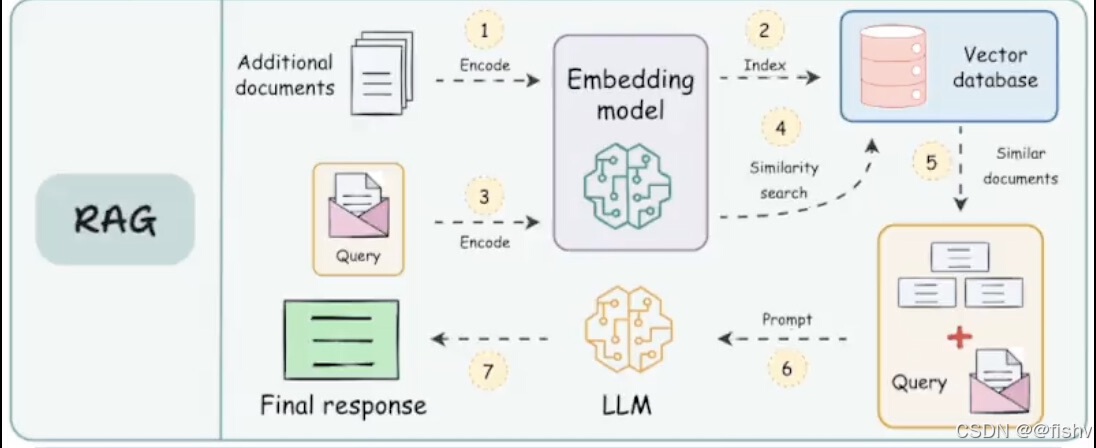
然而,这些看似无所不能的大模型,却有一个致命的弱点:它们是基于海量的公共数据训练的,对于私人领域或者某些垂直领域的回答效果并不理想,有时甚至会出现“幻觉”,也就是“已读乱回”,一本正经地胡说八道,还无法获取最新的数据。比如,如果你问大模型:“哪个大模型最好用?简单来说,RAG技术就像是给模型加了一本“参考书”,每当你提问时,模型会先去“查阅资料”,然后根据查找到的相关信息生成更准确、事实性的答案。
Hugging Face 是一个集成了大量预训练模型、数据集和其他资源的开源社区,专注于自然语言处理(NLP)。它为开发者和研究人员提供了方便的工具,可以快速使用并微调大规模预训练的 NLP 模型。通过与库的紧密集成,Hugging Face 极大地简化了 NLP 项目的开发过程,降低了门槛。Hugging Face 提供的工具和资源极大简化了 NLP 模型的使用和微调过程。通过 Hugging
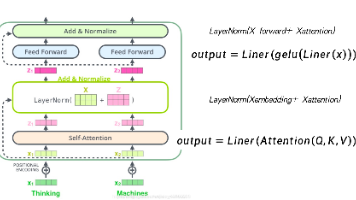
摘要: Transformer架构通过自注意力机制(Self-Attention)革新了深度学习模型设计,解决了传统RNN/CNN的长距离依赖问题。其核心包括: 自注意力:通过Q(查询)、K(键)、V(值)向量直接计算词间关联,如“天气”与“不错”的高权重匹配; 多头注意力:并行多组注意力头,分别捕捉语法、语义等不同维度信息; 残差连接与层归一化:保留原始输入并稳定数据分布,支持深层模型训练。 T
前端:vue3后端:spring 框架
神经网络的训练过程实际上是通过重复前向传播和反向传播这两个关键步骤来调整神经网络中的权重。在前向传播中,数据从输入层经过各个隐藏层逐层计算,最终得到输出结果;在反向传播中,计算损失值并反向传播回每一层,计算每个权重的梯度,最终更新权重。通过不断地迭代训练,神经网络能够从数据中学习模式和规律,提高预测精度。如果有任何疑问或建议,欢迎在评论区留言,我们一起讨论。
