




- @weixin_51367832
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
CSV格式,可用Origin或MATLAB进行导入数据,然后数据后处理,绘图。Scope菜单栏下面设置采样时间,注意:与系统采样时间保持一致!采样时间均为1ms!
详细介绍了刚体机器人动力学的不同元素、性质和方程。机器人动力学是作用在机器人上的力与机器人运动结果之间的关系。机器人动力学信息包含在一个rigidBodyTree对象中,该对象指定了刚体、附点和运动学和动力学计算的惯性参数。要使用动态对象函数,必须将rigidBodyTree对象的DataFormat属性设置为“row”或“column”。这些设置将输入和输出分别作为行向量或列向量返回,用于相关的
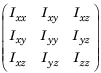
一、PWM原理1.PWM(Pulse Width Modulation)即脉冲宽度调制,在具有惯性的系统中,可以通过对一系列脉冲的宽度进行调制,来等效地获得所需要的模拟参量,常应用于电机控速、开关电源等领域2.PWM重要参数: 频率 = 1 / TS 占空比 = TON / TS 精度 = 占空比变化步距 二、源码#include <REGX52.H&g...具体地说,PWM信号是由一系列脉冲组成

根据打磨工具与工件的接触状态预测曲面法线方向,以有向进给平面与曲面切平面 的截交线作为进给导向,自适应在线预测机器人打磨系统末端执行器的位姿,使末端执行器主轴轴线实时主动跟踪曲面法线,实现对无先验模型曲面工件的机器人打磨轨迹的主动自适应在线预测!:机器人末端配备六维力传感器,实时监测接触力并动态调整姿态(如非夕、节卡方案)。例如,当接触角度变化时,机器人自动调节TCP坐标系下的作用方向,确保法向力
大语言模型(LLM,Large Language Model)是一种基于深度学习的自然语言处理技术,它使用深度神经网络来学习自然语言的统计规律,以便能够自动地生成、理解和处理自然语言。大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。训练数据集:ChatGPT的训练数据

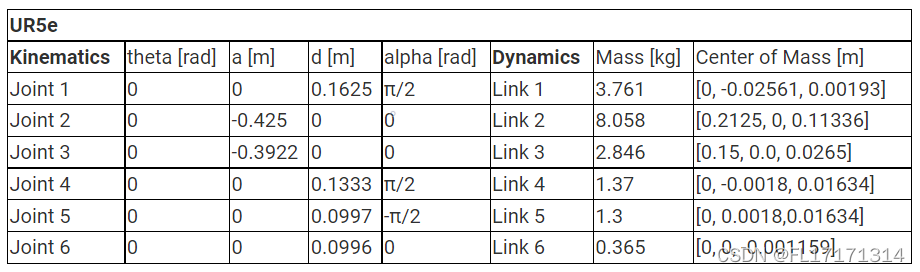
惯量参数如下:<link name="shoulder_link">:<inertia ixx="0.010267495893" ixy="0.0" ixz="0.0" iyy="0.010267495893" iyz="0.0" izz="0.00666"/><link name="upper_arm_link">:<inertia ixx="0.226
例如,机器人可以使用计算机视觉技术来识别人的动作类型,并根据不同的动作类型来采取不同的控制策略。两者之间的区别在于,计算机视觉通常指的是一种对于静态或动态图像数据的处理,包括图像处理、图像分析、图像识别等,而机器视觉则强调的是通过相机、传感器等装置来捕捉环境中的信息,并进行三维空间中的计算、定位和识别等。综上所述,计算机视觉和机器视觉技术在机器人与人之间的物理交互中都发挥着非常重要的作用,可以帮助

在机器人学习中,迁移学习可以帮助机器人在新任务上快速适应,并减少对新任务所需的数据和计算资源。然而,迁移学习的成功取决于源任务和目标任务之间的相似性,以及所迁移知识的有效性和可迁移性。模仿学习的优点是可以利用已有的示范数据来加速学习过程,并且可以避免在探索过程中可能出现的危险或不良行为。然而,模仿学习通常需要大量的高质量示范数据,并且对于与示范数据分布不一致的新任务,机器人的性能可能会受到限制。学
CSV格式,可用Origin或MATLAB进行导入数据,然后数据后处理,绘图。Scope菜单栏下面设置采样时间,注意:与系统采样时间保持一致!采样时间均为1ms!
例如,机器人可以使用计算机视觉技术来识别人的动作类型,并根据不同的动作类型来采取不同的控制策略。两者之间的区别在于,计算机视觉通常指的是一种对于静态或动态图像数据的处理,包括图像处理、图像分析、图像识别等,而机器视觉则强调的是通过相机、传感器等装置来捕捉环境中的信息,并进行三维空间中的计算、定位和识别等。综上所述,计算机视觉和机器视觉技术在机器人与人之间的物理交互中都发挥着非常重要的作用,可以帮助