




- @weixin_49895216
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
11个最流行的AI智能体开发框架(非常详细),零基础入门到精通,看这一篇就够了

文章讲述了一位Java工程师如何利用自身系统架构和代码工程优势,成功转型大模型应用开发。通过三个阶段的学习和实践,他不仅找到高薪工作,还通过副业实现收入翻倍。文章详细介绍了Java技能如何应用于大模型API集成、数据处理和系统部署,分享了具体副业机会和学习资源,为Java从业者提供了转型大模型领域的实用指南。作为一名拥有 5 年 Java 开发经验的工程师,我曾以为自己的职业道路会一直围绕着 Sp

人工智能大模型时代,八种常见的“数据标注”方法
深度学习怎么学?10步快速入门深度学习
Python进行数据可视化的9种常见方法,总有一种是你要用的

人工智能最常见的52个相关岗位!超级基础的人工智能学习路线!一步入门。大家都知道人工智能是高薪领域,不同公司、不同行业、不同职级、不同工作经验会有不同的薪资报酬。我身边年龄相仿的做Al的朋友,有40万的,有80万的,也有100多万的,这和个人的努力是分不开的,今天就来给想进人工智能的宝子们带来一份很基础的学习路线,需要的赶紧码住!人工智能学习路线数学、Python、Numpy、Pandas、数据可

Claude Code是由Anthropic开发的一款智能编程工具,它以命令行工具的形式存在,能够集成到开发者的终端环境中。它基于Anthropic的Constitutional AI框架构建,可以以自然语言交互的方式帮助开发者更高效地完成编程任务。我觉得它其实就是一个Agent,还可以接入MCP工具,以及帮你操作底层系统等等,是目前最强的Agent工具了原生Claude Code启动后,大概长下
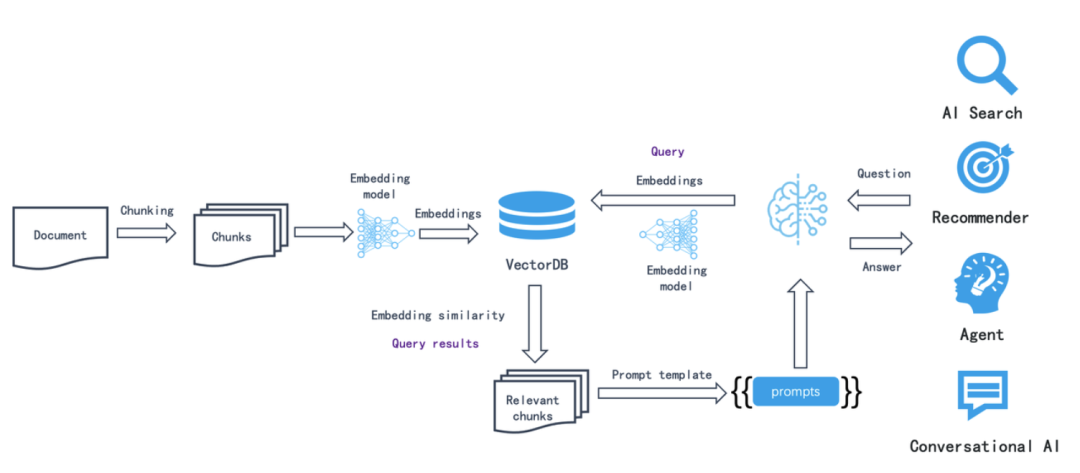
在大模型应用的蓬勃发展中,检索增强生成(Retrieval-Augmented Generation,RAG)技术占据了举足轻重的地位。它就像是大模型的智慧助手,通过从外部知识库中检索相关信息,并将其融入到大模型的回答生成过程中,有效提升了大模型回答的准确性、可靠性和时效性,在问答系统、智能客服、文档摘要等多个领域都发挥着关键作用。上图是一个常见的AI应用的数据流向图,文档分块之后向量化存储到向量
文心一言是百度基于文心大模型打造的生成式AI产品,具备跨模态、跨语言的深度语义理解与生成能力。2023年10月,文心大模型4.0版本发布,实现基础模型的全面升级,理解、生成、逻辑、记忆四大能力显著提升,综合能力可直接对标GPT-4。通义千问是阿里自研的AI大语言模型,2023年10月31日发布了2.0版本,相较于1.0版本,在复杂指令理解、文学创作、通用数学、知识记忆、幻觉抵御等能力上均有显著提升

学习人工智能需要哪些基础知识?(非常详细),零基础入门到精通,看这一篇就够了