




- @weixin_48827824
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
edge-tts --voice zh-CN-YunyangNeural --text "大家好,欢迎关注语音之家,语音之家是一个助理AI语音开发者的社区。查询结果中的Gender为声音的性别,Name为声音的名字,如zh-CN-YunjianNeural,其中zh表示语言,CN表示国家或地区,可以根据需求选择不同的声音。它接受与 edge-tts 选项相同的参数。此外,必须使用 --rate=-
作为仅0.4B参数量的轻量模型,它在同梯队(≤0.8B)中拿下双测试集最优表现,性能全面超越 Qwen3-0.6B、FunASR-Nano-2512等更大参数量模型,甚至优于1.7B的Qwen3-1.7B,展现出极高的参数效率。宁夏、湖北、陕西、河南、山西、天津、山东等方言测试集均有明显提升。团队希望Dolphin-CN-Dialect的发布,能够补齐汉语方言语音识别的短板,让语音识别不只听懂标准

也就是说,问题可能不只出在“静态几何对齐”,而是出在。

直到2012年,Geoffrey Hinton带着他的学生Alex在李飞飞构建的ImageNet图像大数据上,用提出的Alex网络将识别性能比前一届一次性提高将近10个百分点,这才让大部分的人工智能学者真正转向深度学习,因为以之前每届用统计机器学习方法较上一届提升性能的速度估计,这次的提高需要用20多年时间。尽管从神经生理学角度来看,这个网络的记忆能对应于原型说,每个神经元可以看成是一个具有某个固

自ChatGPT-4问世以来,过去的大半年中,我们虽然没有在ChatGPT发布一周年之际等来“ChatGPT-5”,但围绕ChatGPT,仍有不少新看点。其中的一些引发我们对人工智能(AI)与人的关系进行新的思考,另一些则为AI的发展和安全带来新的争论。

作为仅0.4B参数量的轻量模型,它在同梯队(≤0.8B)中拿下双测试集最优表现,性能全面超越 Qwen3-0.6B、FunASR-Nano-2512等更大参数量模型,甚至优于1.7B的Qwen3-1.7B,展现出极高的参数效率。宁夏、湖北、陕西、河南、山西、天津、山东等方言测试集均有明显提升。团队希望Dolphin-CN-Dialect的发布,能够补齐汉语方言语音识别的短板,让语音识别不只听懂标准
在传统语音降噪方法中,都基于以下四个假设假设一、语音和噪声是统计独立的;假设二、噪声相比于语音更加平稳;假设三、时频点是统计独立的;假设四、人耳对语音相位不敏感;第一个假设是合理的,然而其他三个假设在某些条件下并不真正成立。假设二是传统语音降噪中噪声估计模块的基础,然而实际场景中非稳态噪声也是普遍存在的。对于假设三来说,语音和噪声频点之间必然存在相关性,这就导致基于统计模型的方法比不可能完全成立,

第十五届中文口语语言处理国际研讨会(ISCSLP2026)将于2026年11月14-17日在马来西亚槟城举行。作为ISCA下属旗舰会议,该会议涵盖语音识别、合成、理解等前沿方向,接受4-8页论文投稿(截止2026.6.12),采用双盲评审。会议还将举办特别专题、挑战赛和教程(提案截止2026.6.8)。槟城以其多元文化和科技氛围为参会者提供学术交流与文化体验的双重机会。详情请访问会议官网。

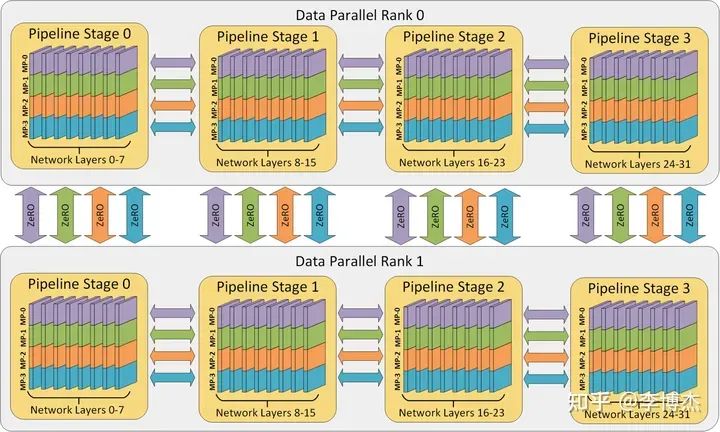
这是一个好问题。先说结论,大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能跟 H100 打个平手。事实上,H100/A100 和 4090 最大的区别就在通信和内存上,算力差距不大。H100 这个售价其实是有 10 倍以上油水的。2016 年我在 MSRA 的时候,见证了微软给每块服务器部署了 FPGA,把 FPGA 打到了沙子
也就是说,问题可能不只出在“静态几何对齐”,而是出在。