- @weixin_47759174
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
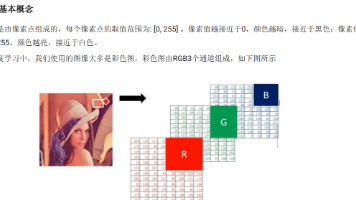
它是计算机视觉里,专门用来训练和测试图像分类模型的「公开标准图片数据集」,相当于给 AI 做 “看图认东西” 练习题的题库。项目具体内容通俗理解本质大量标注好的图片集合给 AI 做 “看图认类别” 的练习题库规模6 万张图片(5 万训练 + 1 万测试)训练用 5 万张题,考试用 1 万张题类别10 个固定类别飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车图像大小32×32×3(像素)很小的彩色图
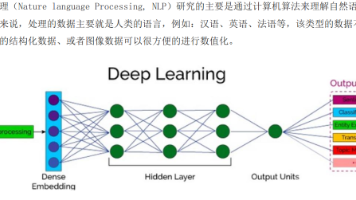
对比维度普通前馈神经网络(基础 NN)卷积神经网络(CNN)循环神经网络(RNN)核心概念最基础神经网络,由输入层、全连接隐藏层、输出层组成;层间全连接,只处理相互独立无关联的数据,无记忆、无自动特征提取能力。以卷积运算为核心的网络,新增卷积层、池化层;依靠局部连接、权值共享自动提取空间特征,专门处理图像类网格结构数据。具有记忆循环结构的神经网络,隐藏层会保存上一时刻状态;能记忆前文时序信息,专门
摘要:本课程旨在通过手写简化版SpringMVC框架来深入理解其核心原理。主要内容包括:1)实现MVC顶层设计,包含调度中心GPDispatcherServlet、请求映射GPHandlerMapping和适配器GPHandlerAdapter;2)开发业务层和控制器逻辑;3)定制模板引擎实现视图解析;4)演示完整请求生命周期。通过模拟SpringMVC的请求分发、业务处理、视图返回全流程,帮助学
Java开发者未来发展方向主要集中在四大领域:云原生与微服务、AI集成、边缘计算/IoT应用以及区块链/Web3开发。云原生方向需掌握Spring生态和容器技术,AI集成可通过Spring AI快速接入智能功能,边缘计算利用Java开发IoT网关应用,区块链领域则可运用Web3j等工具开发去中心化应用。每个方向都要求开发者结合Java基础进行技术升级,同时关注性能优化和新兴技术整合。掌握这些领域将

客户端访问代理服务器,由代理服务器转发请求给后端真实服务器,再将响应结果返回给客户端。客户端不知道真实服务器的存在。#后台项目的运行端口。没啥好说的,主要问题在于跨域,跨域,前端做了一部分,后端也做了一部分。Nginx 在网络层完成转发,不需要任何前端或后端代码参与。对后端而言,请求来源是 Nginx,不是外部客户端。maven打包上传,修改数据库账号密码,一气呵成。对浏览器而言,请求与响应始终来
3. IO 操作不占用 cpu,只是我们一般拷贝文件使用的是【阻塞 IO】,这时相当于线程虽然不用 cpu,但需要一直等待 IO 结束,没能充分利用线程。有些任务,经过精心设计,将任务拆分,并行执行,当然可以提高程序的运行效率。单核 cpu 下,线程实际还是 串行执行 的。tomcat 的异步 servlet 也是类似的目的,让用户线程处理耗时较长的操作,避免阻塞 tomcat 的工作线程。1.
本章内容查看线程线程 API线程状态。
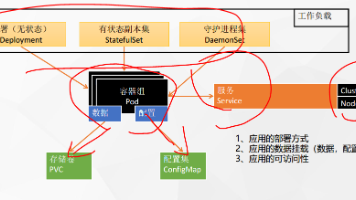
KubeSphere是一个基于Kubernetes的云原生分布式操作系统,支持多云和多集群环境下的应用统一管理。其实战指南包含中间件部署如MySQL、Redis,以及Ruoyi-Cloud和尚医通等项目的实施方案,实现即插即用的云原生应用集成与运维。
本文探讨了从传统MVC架构到Spring Boot的演进过程。首先介绍了Spring Framework的核心特性(AOP、IOC/DI)和MVC项目搭建流程,包括依赖配置、DispatcherServlet设置等。随后重点分析了Spring Boot的自动装配机制,通过@EnableXxx注解实现模块化装配,以及条件装配@Conditional的应用。文章详细解读了Spring Boot自动配置