




- @weixin_47187147
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
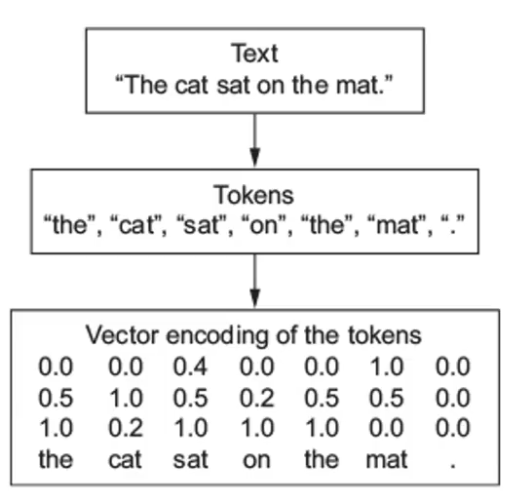
监督学习(supervised learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。映射函数本身仅仅是一种映射关系,并没有增加维度的特性,不过可以利用核函数的特性,构造可以增加维度的核函数,这通常

见微知著,睹始知终。见到细微的苗头就能预知事物的发展方向,能透过微小的现象看到事物的本质,推断结论或者结果。概率模型为机器学习打开了一扇新的大门,将学习的任务转变为计算变量的概率分布。实际情况中,各个变量间存在显式或隐式的相互依赖,如朴素贝叶斯方法直接基于训练数据去求解变量的联合概率分布在时间复杂度还是空间复杂度均是不可行、不划算的。直接基于训练数据求解变量联合概率分布困难。Probabilist
卷积神经网络的思想主要是通过卷积层对图像进行特征提取,从而达到降低计算复杂度的目的,利用的是空间特征信息;循环神级网络主要是对序列数据进行建模,利用的是时间维度的信息。而第三种 注意力机制 网络,关注的是数据中重要性的维度,研究怎么充分关注更加重要的信息,从而提高计算的准确度和效率。
定义编码器self.embedding = nn.Embedding(vocab_size, ebd_size, padding_idx=3) # 将token表示为embedding# encoder_inputs从(batch_size, seq_len)变成(batch_size, seq_len, emb_size)再调整为(seq_len, batch_size, emb_size)

当前系统的状态,可能依赖很长时间之前系统状态。
若要拟合sinx,泰勒认为仿造一条曲线,首先要保证在原点重合,之后在保证在这个点处的倒数相同,导数的倒数相同。这使得L2正则,相对而言,是鼓励产生小而分散的权重,考虑更多的特征,而不仅仅是依赖某几个特征,因此可以增强模型泛化能力。总的来说,正则项相当于给最小化增加了空间的约束,限制了模型的复杂度,因而可以很好解决过拟合问题。等值线与圆的任何部分相交的概率都是相同的,所以交点会尽量靠近坐标轴中间的位
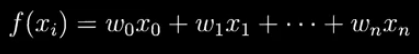
监督学习(supervised learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。映射函数本身仅仅是一种映射关系,并没有增加维度的特性,不过可以利用核函数的特性,构造可以增加维度的核函数,这通常
根据提示是 /usr/lib/x86_64-linux-gnu/ 路径下的 libstdc++.so.6 缺少版本 GLIBCXX_3.4.29。结果显示,里面确实有同类型的文件,我们直接选择一个查看是否有我们需要的版本。输出的结果如下,可以发现里面有我们需要的版本。可以发现输出的结果里确实缺少了我们需要的版本。

卷积神经网络的思想主要是通过卷积层对图像进行特征提取,从而达到降低计算复杂度的目的,利用的是空间特征信息;循环神级网络主要是对序列数据进行建模,利用的是时间维度的信息。而第三种 注意力机制 网络,关注的是数据中重要性的维度,研究怎么充分关注更加重要的信息,从而提高计算的准确度和效率。
定义编码器self.embedding = nn.Embedding(vocab_size, ebd_size, padding_idx=3) # 将token表示为embedding# encoder_inputs从(batch_size, seq_len)变成(batch_size, seq_len, emb_size)再调整为(seq_len, batch_size, emb_size)