




- @weixin_46257458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
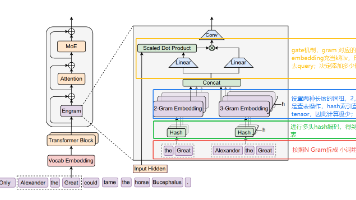
本文提出了一种名为Engram的新型记忆模块,旨在为大语言模型引入显式的记忆功能。通过结合N-Gram算法和多头哈希技术,Engram能够高效存储和检索常见短语及固定搭配,从而将记忆与计算部分解耦。实验表明,分配20-25%参数给记忆模块效果最佳。该方法还采用了压缩词表、短卷积层、张量卸载等技术优化存储效率,并使用Muon优化器节省内存。相比传统Transformer依赖参数交互隐式存储知识,En
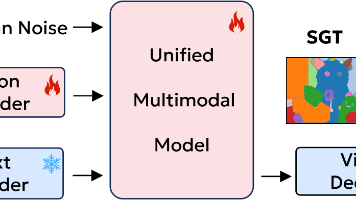
上海交通大学与腾讯ARC Lab联合发布论文《Semantic Generative Tuning for Unified Multimodal Models》,提出SGT方法解决统一多模态模型中视觉理解与生成割裂的问题。研究发现高层语义任务(如图像分割)能有效连接理解与生成,相比像素重建更关注语义结构。实验表明,SGT在BAGEL和OmniGen2模型上均显著提升性能,如CV-Bench得分提升
《World Model & VLA论文综述:机器人领域必收藏资源》介绍了一个由song2yu维护的开源项目,聚焦世界模型与视觉-语言-动作模型的前沿研究。该项目通过交互式HTML页面(支持离线浏览和中文版本)系统梳理了环境表征建模、多模态控制范式、方法分类对比等核心内容,并持续追踪2024-2026年趋势,包括自动驾驶VLA、3D感知融合等热点方向。提供GitHub仓库和在线访问两种使用
DeepSeek-V4 技术报告摘要 DeepSeek-V4 是 DeepSeek-AI 于 2026 年 4 月发布的大规模混合专家(MoE)语言模型,支持 1M token 上下文,在推理效率、架构创新和开源能力上实现突破。 核心亮点 百万级上下文:采用 CSA+HCA 混合注意力,1M token 推理效率提升 3.7 倍,KV 缓存减少 90%。 架构创新: mHC 流形约束:增强深层模型

DeepSeek-V4 技术报告摘要 DeepSeek-V4 是 DeepSeek-AI 于 2026 年 4 月发布的大规模混合专家(MoE)语言模型,支持 1M token 上下文,在推理效率、架构创新和开源能力上实现突破。 核心亮点 百万级上下文:采用 CSA+HCA 混合注意力,1M token 推理效率提升 3.7 倍,KV 缓存减少 90%。 架构创新: mHC 流形约束:增强深层模型
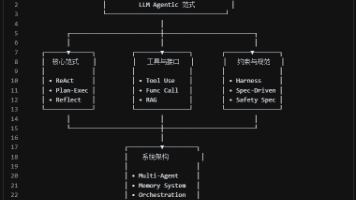
文章摘要: AI正从被动问答机向自主代理(Agentic LLM)演进,ReAct框架通过交织推理(Thought)与行动(Action)实现多步骤任务自主完成。工具调用(Tool Use)赋予模型外部能力,如搜索、计算等,而标准化函数调用(Function Calling)优化了交互流程。为确保可控性,测试框架(Harness)约束Agent行为,规范驱动(Spec-Driven)明确其边界。其
本文探索了原生多模态预训练(UMMs)的多个方面,包括视觉编码器、架构设计(MoE/Dense)、多模态数据、世界建模及其扩展规律。研究发现:1)RAE(Representation AutoEncoder)在视觉理解和生成任务中表现最优;2)视觉与文本数据具有互补性,在下游任务中展现出协同效应;3)UMMs能通过多模态预训练自然实现世界建模,并涌现出多种能力;4)MoE架构在多模态建模中高效且支

OMP_FACE——人脸识别系统该软件包实现了基于稀疏表示的面部识别方法程序相对便捷且易上手主脚本中包含具体的一个例子通常,通常遵循以下使用顺序即可实现人脸识别功能:选择训练数据的数据库途径。选择测试图像。运行“training_data”功能以创建所有训练图像的二维矩阵。运行“omp_fun ”功能以生成beta。运行“recorgnize”功能以获取训练数据库中识别图像的名...
先占个坑。。。。。。代码以及说明后补效果图如下
OMP_FACE——人脸识别系统该软件包实现了基于稀疏表示的面部识别方法程序相对便捷且易上手主脚本中包含具体的一个例子通常,通常遵循以下使用顺序即可实现人脸识别功能:选择训练数据的数据库途径。选择测试图像。运行“training_data”功能以创建所有训练图像的二维矩阵。运行“omp_fun ”功能以生成beta。运行“recorgnize”功能以获取训练数据库中识别图像的名...