




- @weixin_45755332
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我是Ubuntu系统,NVIDIA 3070 8G显存 16G运行内存,全用cpu也行,运行内存要大一些。第一次进入会让你注册,注册一个即可。点击models即可进入模型列表,比如我们选择deepseek-r1。这里除了deepseek,其他模型也都是在ollama官网下载的。即可安装,安装失败的话就创建个虚拟环境,再pip装。在设置里,这样选择,记得修改你的ip,端口不用改。可以选择不同的模型,
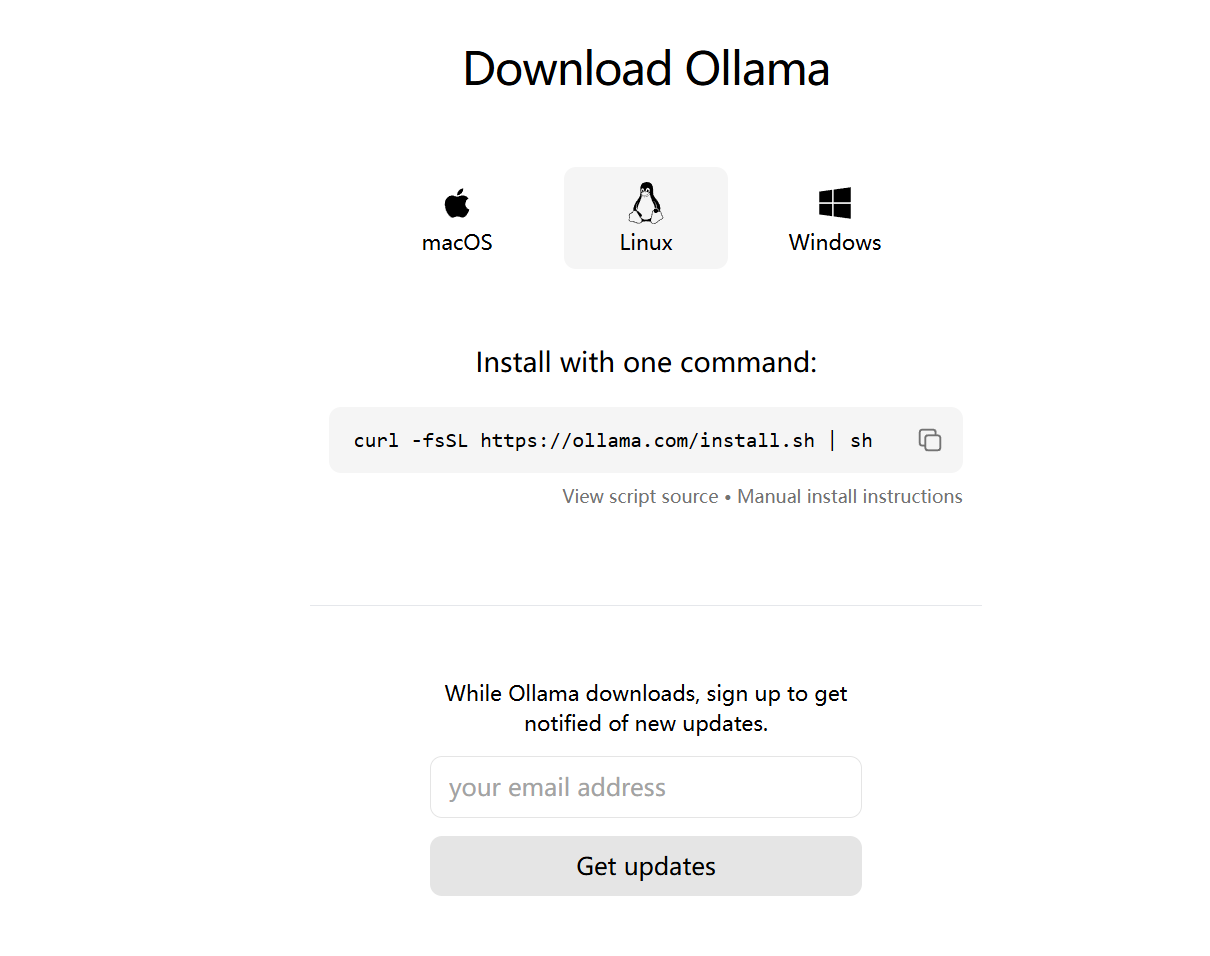
香橙派Aipro提供的案例完美的执行成功了,学习起来很适合企业开发者用户。往外继续延伸,如果单纯的使用香橙派Aipro做模型的测试也是很可以的,可惜了我这边内存不太够,没办法做太多太消耗内存的东西。需要自己扩展下存储空间就很完美了,运行大模型肯定也不在话下。跑这个yolov8模型时,从拉下来代码,到搭建环境,再到运行结果,都比较顺利。延迟感觉还是稍慢满打满算一张图需要800ms。不知道跑上多路流然

Milvus 创建于 2019 年,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的海量嵌入向量。作为专门设计用于处理对输入向量的查询的数据库,它能够对一万亿级的向量进行索引。与现有的关系数据库主要按照预定义的模式处理结构化数据不同,Milvus 是自下而上设计的,用于处理从非结构化数据转换而来的嵌入向量。向量相似性搜索是将向量与数据库进行比较以查找与查询向量最相

孪生神经网络(Siamese network)主要用途是比较两图片的相似程度,其核心思想就是权值共享。卷积神将网络是通过卷积运算提取图像的特征进行训练的,如果想比较两个图像的相似程度,也要对两个图像分别进行特征提取,只判断特征的相似度就可以了。然而不同的卷积核运算后得到的特征很有可能不在一个域中,所以要使用同一个网络进行特征提取。孪生神经网络的优点:对于类别不平衡问题鲁棒性更强,更易于做集成学习,
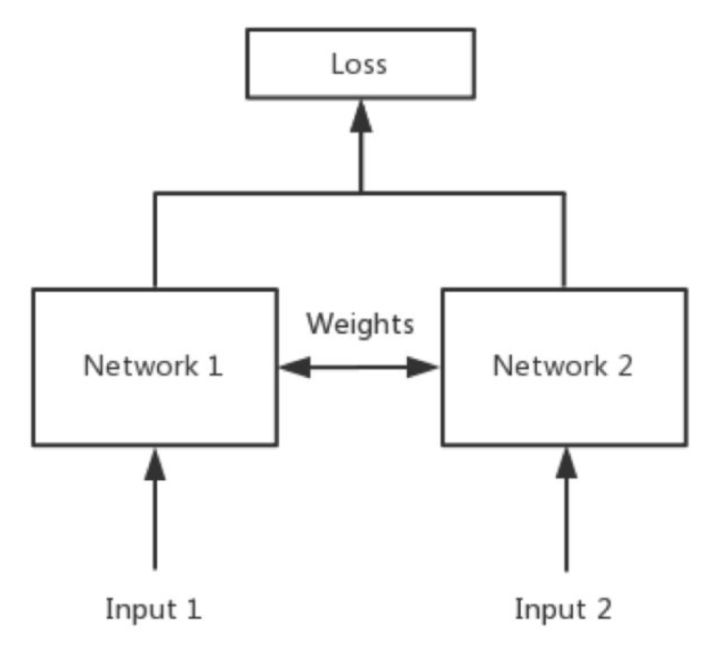
从小白的视角来看卷积神经网络笔记比较详细,但肯定也有很多地方写的不清楚或者不正确,还望指正如果你和我一样是小白,希望对你有所帮助
- **主要教材为西瓜书,结合南瓜书,统计学习方法,B站视频整理~**- **人群定位:学过高数会求偏导、线代会矩阵运算、概率论知道啥是概率**- **原理讲解,公式推导,课后习题,实践代码应有尽有,欢迎订阅**
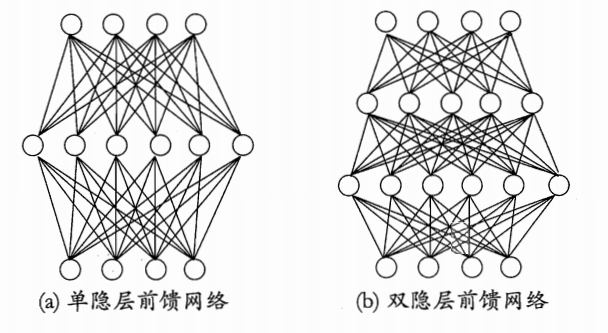
本系列文章是自己学了一段时间深度学习并且做出一定东西后再回头打数学理论基础而写,旨在巩固自己的基础,帮助小白快速入门。这都是自己弄懂之后才写的,完全弄懂那些数学公式也是比较难的,希望看这篇文章的小伙伴一定要看懂下面的代码。有不懂得可以直接提出,若有错误,当立即改正,若不有侵权,当立即删除。
简介CRNN 全称为 Convolutional Recurrent Neural Network,是一种卷积循环神经网络结构,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。CRNN(Convolutional Recurrent Neural Network)是目前较为流行的图文识别模型,可识别较长的文本
人体姿态估计是一个对人体关节进行识别和分类的方法。本质上,这是一种捕获描述人类的关键点的每个关节(arm,head、torso,etc...)的方法。

1.CRAPS又称花旗骰,是美国拉斯维加斯非常受欢迎的一种的桌上赌博游戏。该游戏使用两粒骰子,玩家通过摇两粒骰子获得点数进行游戏。简单的规则是:玩家第一次摇骰子如果摇出了7点或11点,玩家胜;玩家第一次如果摇出2点、3点或12点,庄家胜;其他点数玩家继续摇骰子,如果玩家摇出了7点,庄家胜;如果玩家摇出了第一次摇的点数,玩家胜;其他点数,玩家继续要骰子,直到分出胜负。"""Craps赌博游戏我们设定