




- @weixin_45751396
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
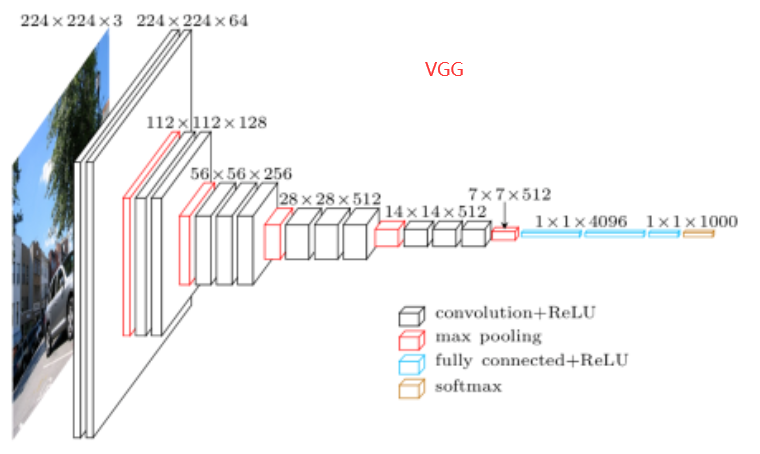
虽然深度神经网络的概念非常简单——将神经网络堆叠在一起。但由于不同的网络结构和超参数选择,这些神经网络的性能会发生很大变化。 本章介绍的神经网络是将人类直觉和相关数学见解结合后,经过大量研究试错后的结晶。 我们会按时间顺序介绍这些模型,在追寻历史的脉络的同时,帮助你培养对该领域发展的直觉。这将有助于你研究开发自己的结构。 例如,本章介绍的批量归一化(batch normalization)和残差网
本博客简单介绍BP神经网络、RBF神经网络、GRNN神经网络、决策树和随机森林的相关知识
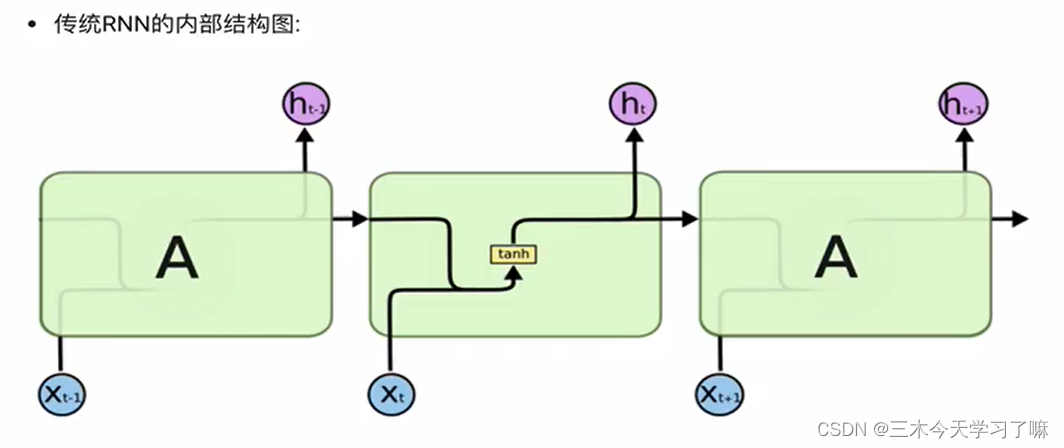
如果说卷积神经网络可以有效地处理空间信息, 那么本章的循环神经网络(recurrent neural network,RNN)则可以更好地处理序列信息。 循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
正如您在 LingBot-VA 中观察到的妙招,前沿的 WAMs 正在将视频和动作解耦,把视频预测从“决定动作的唯一前置蓝图”,降级为“辅助动作生成的条件信号”或“训练期的正则化约束”。LingBot-VA通过混合 Transformer (MoT) 架构和交织序列,让视频和动作在底层共享 KV-Cache,并在执行后用真实观测画面强制替换预测画面,打破了闭门造车的误差累积。DreamZero。
如果说卷积神经网络可以有效地处理空间信息, 那么本章的循环神经网络(recurrent neural network,RNN)则可以更好地处理序列信息。 循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
由于噪声的均值为0,所以对Q的均值求期望,就等于对x求期望。然而,Q最大值的期望却会大于等于x的最大值,且Q最小值的期望也会小于等于x的最小值。状态价值函数(State-value function),是不是任何一个策略pi,执行下一步所有可能的动作所带来的动作价值的期望。理解为,当前状态下,执行所有可能动作的带来的收益,一定程度上反映了当前状态的优劣?我是这样理解的:DQN是要学一个最优动作价值
本博客简单介绍BP神经网络、RBF神经网络、GRNN神经网络、决策树和随机森林的相关知识
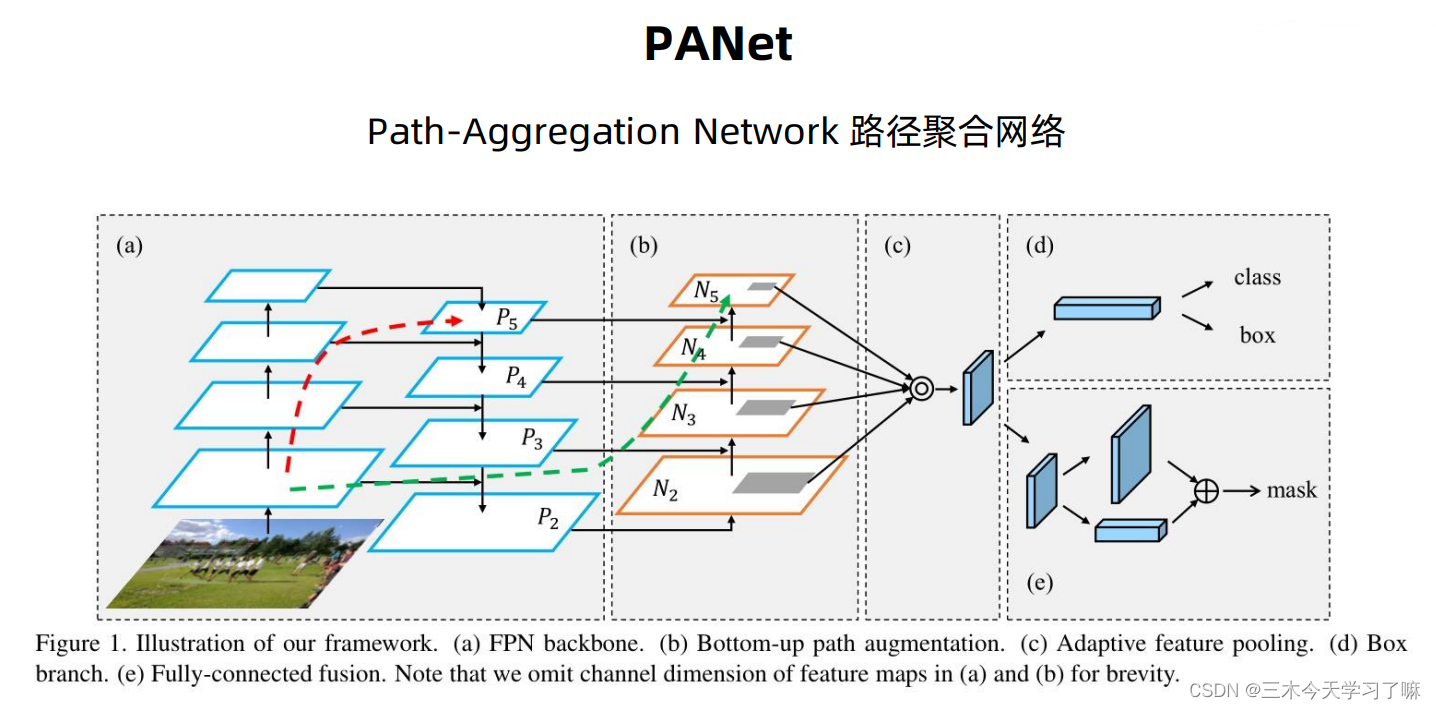
介绍了如何查看YOLOv5的网络框架,分析其中的部分组件,并对核心代码进行了阅读分析。
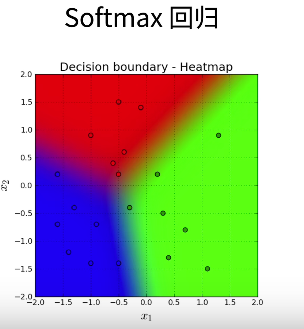
本博客介绍了线性回归和softmax回归,从数学公式到代码实现,再到高级API,更简洁地实现代码。参考书籍:《动手学深度学习V2》
如果说卷积神经网络可以有效地处理空间信息, 那么本章的循环神经网络(recurrent neural network,RNN)则可以更好地处理序列信息。 循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。