




- @weixin_44911248
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器学习分类监督学习:在有标签的基础上去预测标签半监督学习:数据有标签和没标签,根据有标签的数据训练去预测没标签数据的标签无监督学习:对于所有没标签的数据强化学习:类似人类的一种学习,不断的和环境进行交互,根据反馈去调整自己的行为监督学习首先关注的是模型本身,这个模型的输入以及对应的输出是什么损失函数Loss:模型的预测值和真实值之间的差别目标函数Objective:就是在模型训练中的尽可能的优化

一些常用的机器学习算法模型
deepseek-r1 mac端本地部署教程
本文主要对pandas库的一些常用功能函数进行总结,包括一些函数的参数以及实例和运行结果

总结了十道pandas常用方法的练习题,适合pandas库的入门以及训练基础
deepseek-r1 mac端本地部署教程
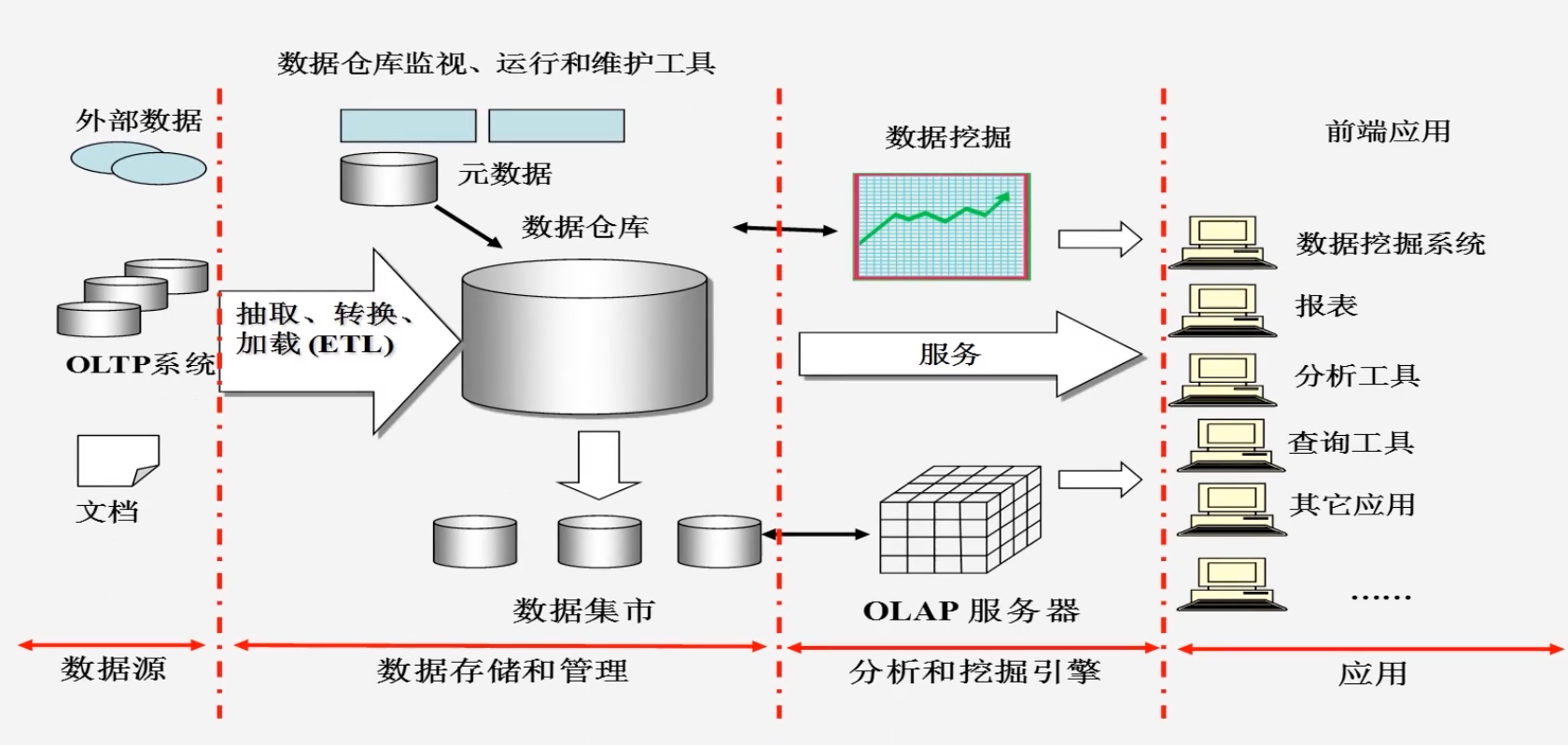
Hive特点传统的数据仓库既是数据存储产品也是数据分析产品传统的数据仓库能同时支持数据的存储和处理分析Hive本身并不支持数据存储和处理其实只是提供了一种编程语言其架构于Hadoop之上,Hadoop有支持大规模数据存储的组件HDFS,以及支持大规模数据处理的组件MapReduceHive借助于这两个组件,完成数据的存储和处理其依赖分布式文件系统HDFS存储睡依赖分布式并行计算系统MapReduc
一些常用的机器学习算法模型
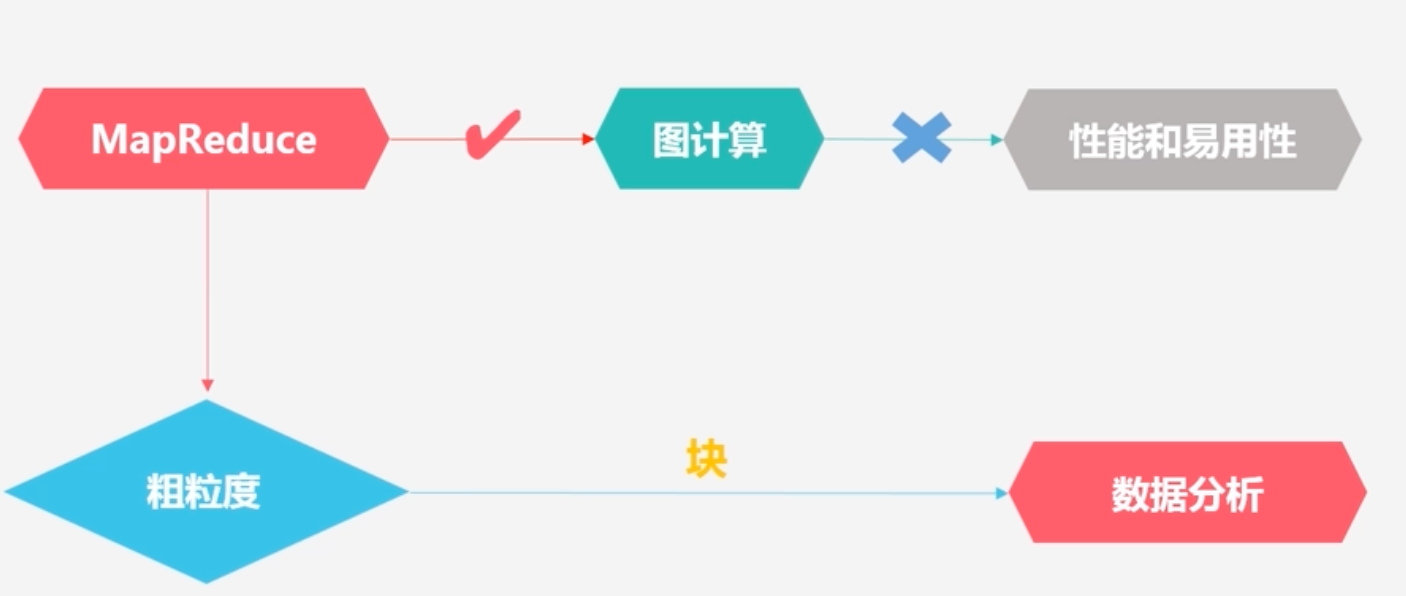
图计算是专门针对图数据结构的处理许多大数据都是以大规模图或者网络的形式出现许多非图结构的大数据,也常常会被转换为图模型后进行分析图数据结构很好地表达了数据之间的关联性关联性计算是大数据计算的核心—通过获得数据的关联性,可以从噪音很多的海量数据中抽取有用的信息图的应用实例购物者之间进行建模,可以得到兴趣比较相似的用户,为用户实时推荐商品图结构计算可以发现传播关系中的意见领袖,如热门话题讨论传统的图计
一些常用的机器学习算法模型