




- @weixin_44462930
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
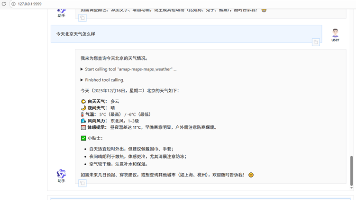
阿里云百炼大模型与MCP服务集成指南 本文介绍了如何配置阿里云百炼大模型服务平台并集成MCP服务的完整流程。首先需要完成阿里云账号注册、实名认证和API Key获取,配置Python 3.10环境后,可通过OpenAI兼容接口调用通义千问大模型。第二部分详细说明了MCP服务的安装配置,包括高德地图API申请、MCP服务器连接获取,以及如何将天气查询、地图查询等功能通过MCP集成到大模型应用中。最后
本文介绍了PaddleOCR识别模块的数据准备、环境配置和模型微调方法。数据准备部分详细说明了TXT格式的数据目录结构和标注文件要求,建议训练集与验证集比例为8:2或9:1,并提供了不同场景下的数据量建议。环境配置部分列出了Python、PaddlePaddle等依赖项的版本要求,以及CUDA环境的配置方法。模型微调部分讲解了如何修改配置文件指定数据集路径、训练参数和预训练模型路径,包括数据增强策
一文搞懂c++自定义排序规则对结构体排序

windows下gitlabrunner自动化配置
本文介绍了PaddleOCR识别模块的数据准备、环境配置和模型微调方法。数据准备部分详细说明了TXT格式的数据目录结构和标注文件要求,建议训练集与验证集比例为8:2或9:1,并提供了不同场景下的数据量建议。环境配置部分列出了Python、PaddlePaddle等依赖项的版本要求,以及CUDA环境的配置方法。模型微调部分讲解了如何修改配置文件指定数据集路径、训练参数和预训练模型路径,包括数据增强策
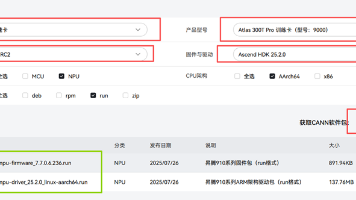
摘要:本文详细介绍了在华为昇腾平台上配置PyTorch训练环境的完整流程,包括驱动/固件安装、CANN工具包部署以及Python环境搭建。主要内容涵盖:1)从昇腾社区下载对应版本的驱动和固件;2)通过命令行安装NPU驱动、固件及CANN组件;3)配置Python3.10环境并安装torch-npu等依赖包;4)提供CPU/NPU两种模式下的语音识别性能测试代码,包含模型加载、推理执行和结果输出示例
Sane是linux下调用扫描仪的通用协议,要使用的话需要先在电脑上/usr/lib/或者/usr/local/lib/下安装libsane.so文件。其调用过程如下:1.初始化 2.查找设备 3.打开设备 4.设置参数 5.开始扫描 6.保存图像 7.取消扫描 8.关闭设备 9.释放资源。以下介绍均基于sane.h。首先对用到的sane定义的枚举数据类型进行介绍:SANE_Status:sane
本文介绍了PaddleOCR识别模块的数据准备、环境配置和模型微调方法。数据准备部分详细说明了TXT格式的数据目录结构和标注文件要求,建议训练集与验证集比例为8:2或9:1,并提供了不同场景下的数据量建议。环境配置部分列出了Python、PaddlePaddle等依赖项的版本要求,以及CUDA环境的配置方法。模型微调部分讲解了如何修改配置文件指定数据集路径、训练参数和预训练模型路径,包括数据增强策
阿里云百炼大模型与MCP服务集成指南 本文介绍了如何配置阿里云百炼大模型服务平台并集成MCP服务的完整流程。首先需要完成阿里云账号注册、实名认证和API Key获取,配置Python 3.10环境后,可通过OpenAI兼容接口调用通义千问大模型。第二部分详细说明了MCP服务的安装配置,包括高德地图API申请、MCP服务器连接获取,以及如何将天气查询、地图查询等功能通过MCP集成到大模型应用中。最后
摘要:本文详细介绍了在华为昇腾平台上配置PyTorch训练环境的完整流程,包括驱动/固件安装、CANN工具包部署以及Python环境搭建。主要内容涵盖:1)从昇腾社区下载对应版本的驱动和固件;2)通过命令行安装NPU驱动、固件及CANN组件;3)配置Python3.10环境并安装torch-npu等依赖包;4)提供CPU/NPU两种模式下的语音识别性能测试代码,包含模型加载、推理执行和结果输出示例