




- @weixin_42764932
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章目录两阶段(2-stage)检测模型R-CNN:非极大值抑制(NMS)Fast R-CNN: 共享卷积运算RoI PoolingFaster R-CNN关键在RPN网络1、2、anchor分配3、 softmax判定positive与negative4、bounding box regression5、Proposal Layer单次目标检测器YOLOSSDFPNcenter net指标Two
半监督学习Mean teachers网络整体的架构包括两个部分student model和teacher model:student model的网络参数通过学习,梯度下降获得。teacher model的网络参数通过student model的网络参数的moving average得到。student model的网络参数更新方法:通过损失函数的梯度下降更新参数得到。其中损失函数包括两个部分:第
深度学习-优化器基本框架非自适应学习率SGDMomentumNesterov自适应学习率AdagradAdadeltaAdamAdamaxNadam小结这里是引用https://blog.csdn.net/u012759136/article/details/52302426/?ops_request_misc=&request_id=&biz_id=102&utm_ter
ROS 是一个适用于机器人的开源操作系统。它提供了操作系统应有的服务,包括硬件抽象、底层设备控制、常用函数实现、进程间消息传递和包管理。它也提供用于获取、编译、编写和跨计算机运行代码所需的工具和库函数。ROS11. ROS工作空间2. ROS 文件系统2.1 rospack 获取有关包的信息2.2 roscd 和 rosls3. 创建 ROS 包3.1创建3.2 构建一个 catkin 工作区并获
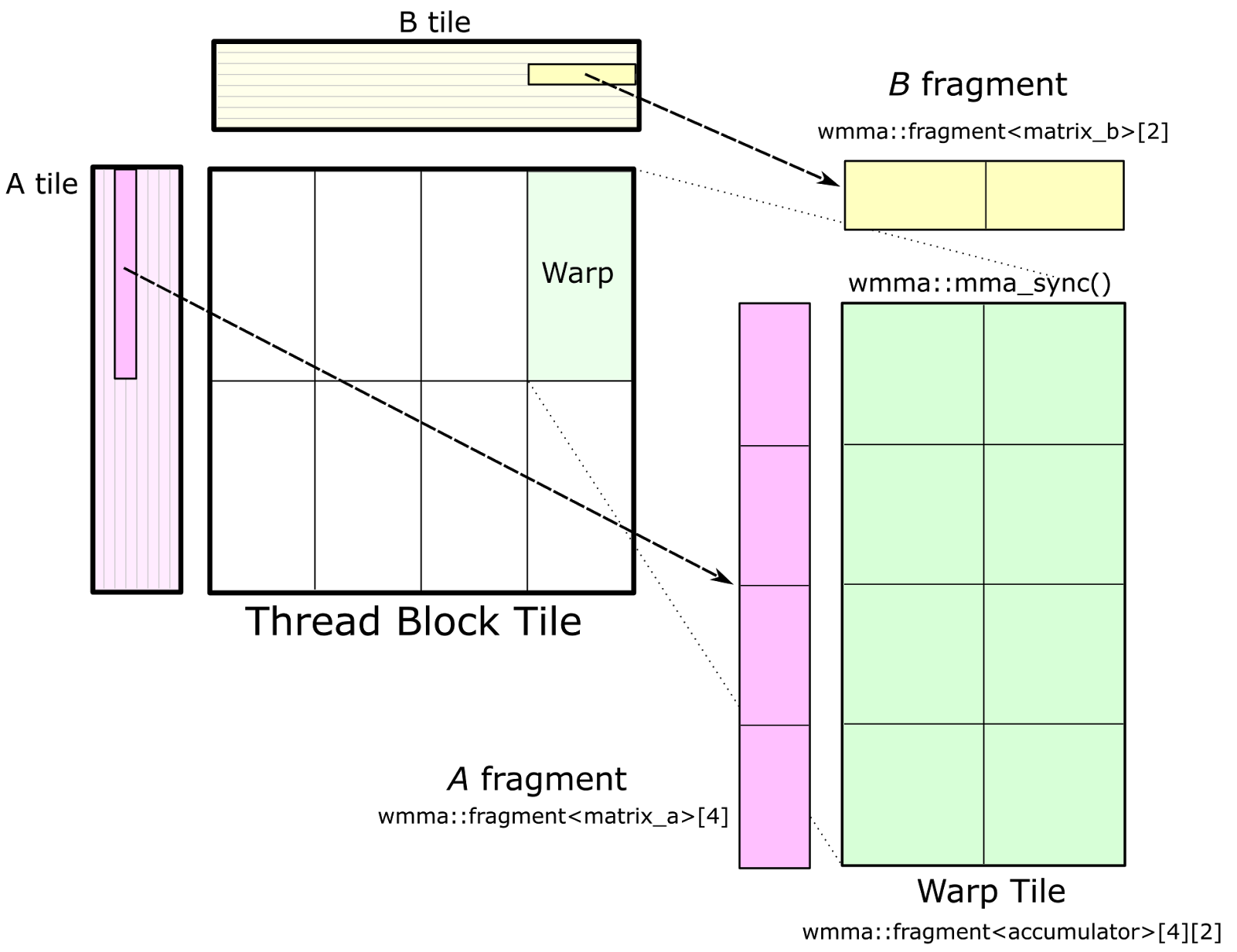
使用cutlass实现多种精度的GEMM,附有完整代码与cmakelist
1. 下载model库下载https://github.com/osrf/gazebo_models,解压重命名为models。移动到~/.gazebo文件夹中2. world模型https://github.com/KalanaRatnayake/Multi-robot-mapping/tree/c7dfc4e2d8d809e49038b3792b7c045429c039e03. rossour
安装ros noetic安装kobuki双目相机建图安装ros noeticsudo sh -c '. /etc/lsb-release && echo "deb http://mirrors.tuna.tsinghua.edu.cn/ros/ubuntu/ $DISTRIB_CODENAME main" > /etc/apt/sources.list.d/ros-lates
虽然non-matmul FLOPs仅占总FLOPs的一小部分,但它们的执行时间较长,这是因为GPU有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的16倍。这个过程使用更多的flop,由于减少HBM访问,重新计算也加快了反向传播的速度。,为了减少对HBM的读写,FlashAttention将参与计算的矩阵进行分块送进SRAM,减少了HBM访存,来提高整体读写速度。,将QK划分成块后,只能计

torch.multiprocessing是具有额外功能的multiprocessing,其 API 与multiprocessing完全兼容,因此我们可以将其用作直接替代品。multiprocessing支持 3 种进程启动方法:fork(Unix 上默认)、spawn(Windows 和 MacOS 上默认)和forkserver。要在子进程中使用 CUDA,必须使用forkserver或sp