




- @weixin_42529756
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2.1 库的安装学习目标目标搭建好机器学习基础阶段的环境应用无整个机器学习基础阶段会用到Matplotlib、Numpy、Pandas等库,为了统一版本号在环境中使用,将所有的库及其版本放到了文件requirements.txt当中,然后统一安装新建一个用于人工智能环境的虚拟环境mkvirtualenv -p aimatplotlib==2.2.2numpy==1.14.2pandas==0.20
bert预训练语言模型论文及实现
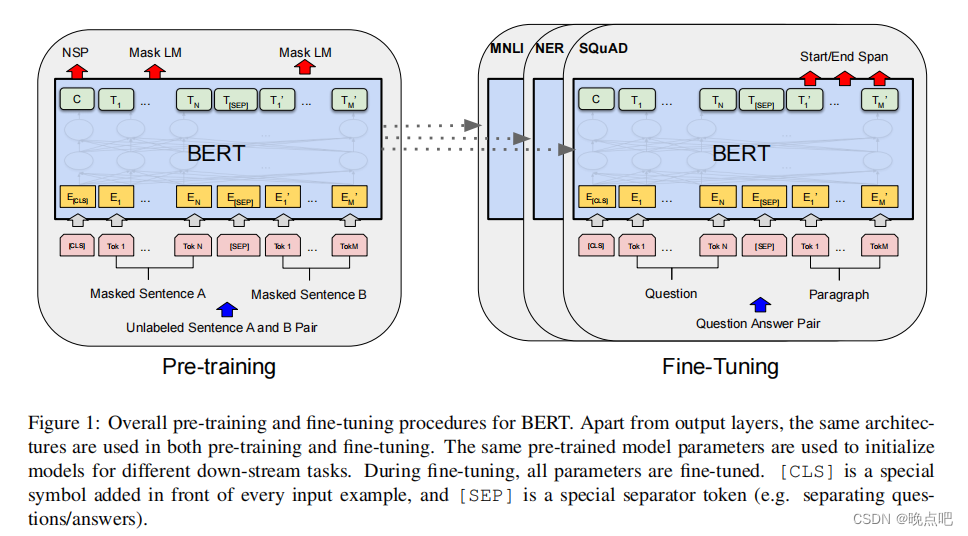
bert源码解读,,代码及数据分享

循环神经网络实现文本情感分类目标知道LSTM和GRU的使用方法及输入输出的格式能够应用LSTM和GRU实现文本情感分类1. Pytorch中LSTM和GRU模块使用1.1 LSTM介绍LSTM和GRU都是由torch.nn提供通过观察文档,可知LSMT的参数,torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bi
使用tensorflow2 加载预训练的bert模型进行tfserving 部署。分类模型。
问答机器人介绍目标知道问答机器人是什么知道问答机器人实现的逻辑1. 问答机器人在前面的课程中,我们已经对问答机器人介绍过,这里的问答机器人是我们在分类之后,对特定问题进行回答的一种机器人。至于回答的问题的类型,取决于我们的语料。当前我们需要实现的问答机器人是一个回答编程语言(比如python是什么,python难么等)相关问题的机器人2. 问答机器人的实现逻辑主要实现逻辑:从现有的问答对中,选择出
tensorflow2 serving 模型部署服务,热部署。
1.4 机器学习工作流程学习目标目标了解机器学习的定义了解机器学习的工作流程应用无1 什么是机器学习机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。2 机器学习工作流程机器学习工作流程总结1.获取数据2.数据基本处理3.特征工程4.机器学习(模型训练)5.模型评估2.1 获取到的数据集介绍数据简介在数据集中一般:一行数据我们称为一个样本一列数据我们...
1、sparkStreaming概述1.1 SparkStreaming是什么它是一个可扩展,高吞吐具有容错性的流式计算框架吞吐量:单位时间内成功传输数据的数量之前我们接触的spark-core和spark-sql都是处理属于离线批处理任务,数据一般都是在固定位置上,通常我们写好一个脚本,每天定时去处理数据,计算,保存数据结果。这类任务通常是T+1(一天一个任务),对实时性要求不高。[外链图片转存