- @weixin_42310154
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
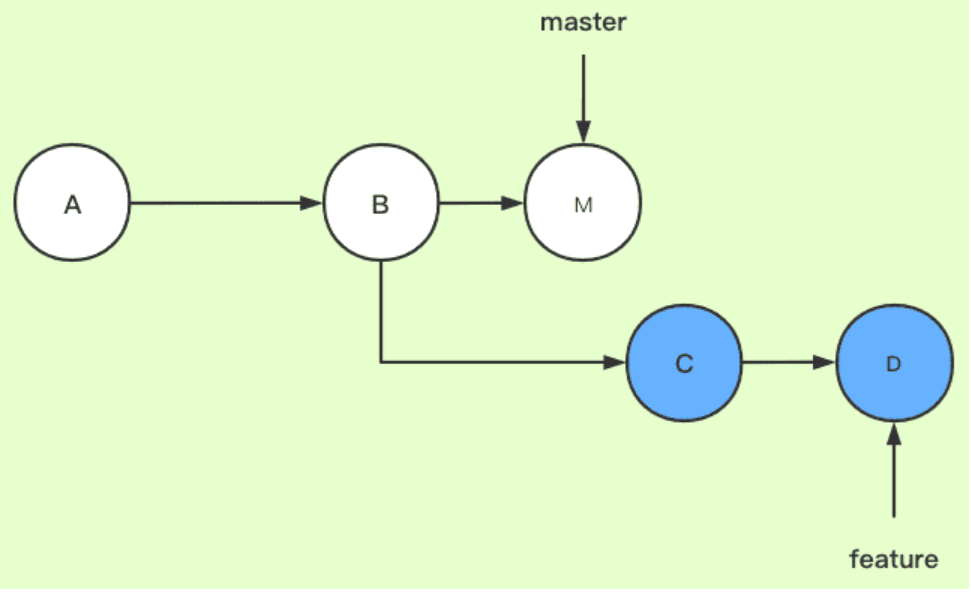
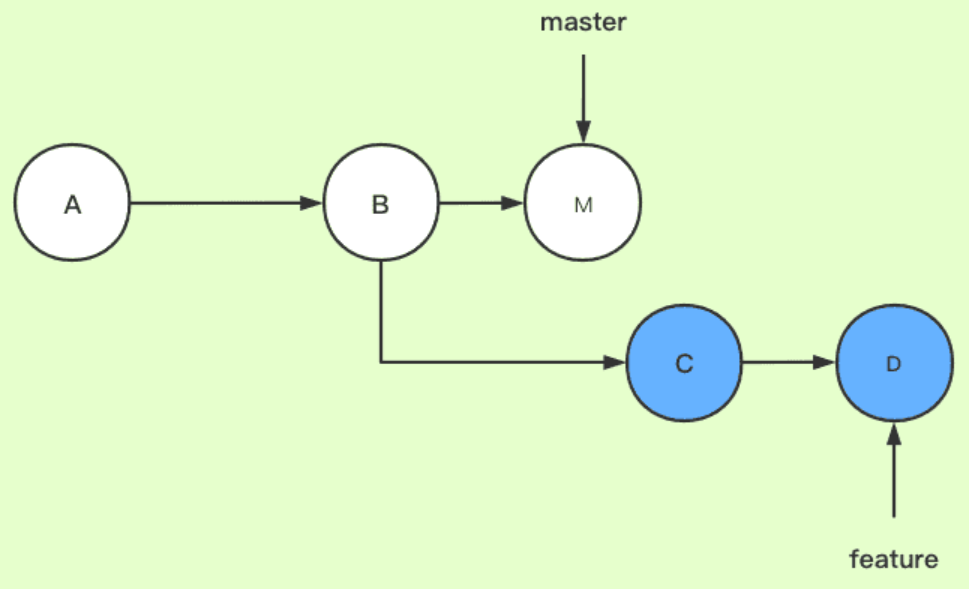
(1)fast-forward:现在有master分支,dev分支拉出来开发并commit了几次,再合并回master分支,如果master分支在dev分支拉出来以后没有任何提交了,就会使用fast-forward模式,直接把master指针指向dev的最后一个提交节点上,分支提交记录为一条直线,看起来就像这些提交是直接在master上做的,看不到任何关于dev分支的信息。 git merge命令
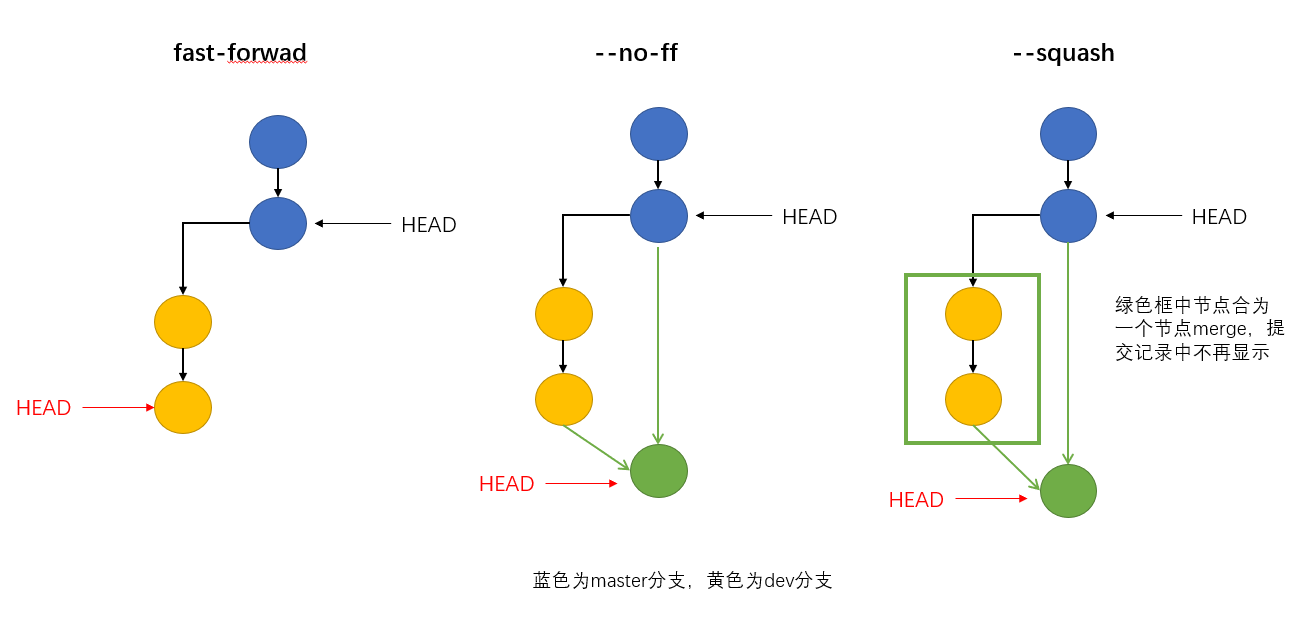
git merge命令作用是将某个分支的内容合并到另一个分支,在合并时有可能会发生冲突,这个时候需要手动解决冲突之后进行提交,才能完成合并。假设现在有两个分支,一个是master,一个是dev,在master分支上执行:git merge dev合并原则:1、取并集。意思就是master上没有而dev上有的文件会合并过来,master上有而dev上没有的文件会保留下来。2、冲突仅会发生在同名文件。
epoch、iteration、bath_size、episode在DNN中的解释:epochone forward pass and one backward pass of all the training examples, in the neural network terminology,重点就是所有的训练数据都要跑一遍。假设有6400个样本,在训练过程中,这6400个样本都跑完了才..
在拉公共分支最新代码的时候使用rebase,也就是git pull -r但往公共分支上合代码的时候,使用merge
epoch、iteration、bath_size、episode在DNN中的解释:epochone forward pass and one backward pass of all the training examples, in the neural network terminology,重点就是所有的训练数据都要跑一遍。假设有6400个样本,在训练过程中,这6400个样本都跑完了才..
在拉公共分支最新代码的时候使用rebase,也就是git pull -r但往公共分支上合代码的时候,使用merge
epoch、iteration、bath_size、episode在DNN中的解释:epochone forward pass and one backward pass of all the training examples, in the neural network terminology,重点就是所有的训练数据都要跑一遍。假设有6400个样本,在训练过程中,这6400个样本都跑完了才..
文章目录一 前言二 Faster RCNN模型详解1 测试(Test)1.1 总体架构1.2 conv layers1.3 RPN1.3.1 anchors1.3.2 cls layer——分类1.3.3 reg layer——回归2 训练三 总结一 前言Faster RCNN是two-stage目标检测模型中的典型代表,虽然已经是16年的老模型,但检测与训练过程还是比较复杂的,至少有80%以上调
在github上配置ssh key很容易,网上一大堆教程,但基本没有详细解释其原理的,为什么要配?每使用一台主机都要配?配了为啥就不用密码了?下面简单通俗地解释一下:我们在往git上push项目的时候,如果走https的方式,每次都需要输入账号密码,非常麻烦。而采用ssh的方式,就不再需要输入,只需要在github自己账号下配置一个ssh key即可。ssh key的配置是针对每台主机的,比如我在
在拉公共分支最新代码的时候使用rebase,也就是git pull -r但往公共分支上合代码的时候,使用merge