




- @weixin_40564352
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
FasterR-CNN 是作者在fast r-cnn后又一力作,同样采用VGG16作为backbone。推理速度能达到5fps,在2015年 ILSVRC 和coco景山获得多个项目第一名。
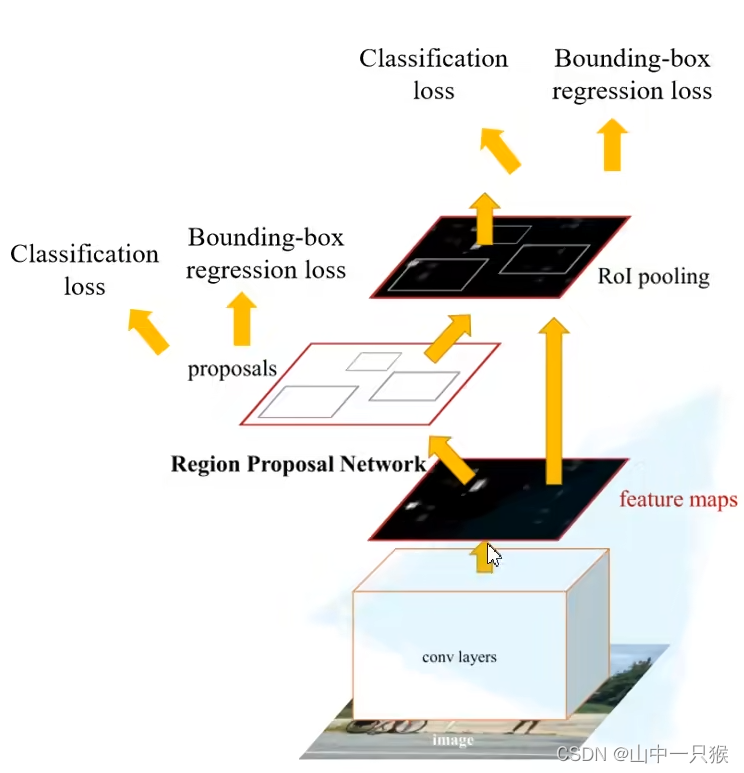
在迁移学习中或者对原有模型修改后,采用预训练模型会提高训练效率和模型精度。因为原来的模型和新模型的结构不同,是无法直接加载原来模型的权重的。我们通常只会加载我们需要的部分预训练权重,通常是加载前面的部分权重,后面的权重进行抛弃。

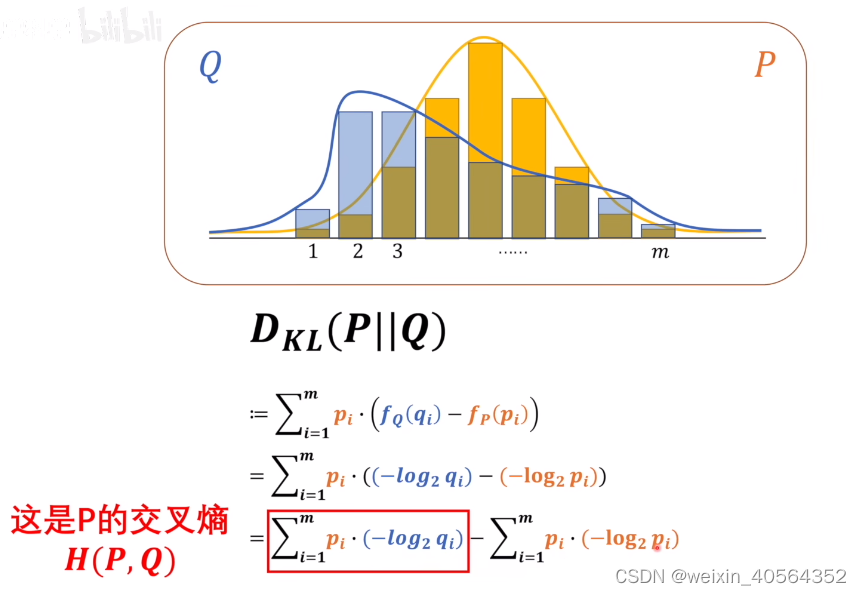
根据上面的公式,我们用KL散度看的是对原始分布中的数据概率与近似分布之间的对数差的期望。我们现在知道了如何衡量一个系统的信息量的期望,那么当我们用一个系统,去描述另一个系统的时候,如何衡量我们描述的是否正确呢?也就是,当我们对系统进行数学建模的时候,我们如何量化我们的模型的好坏。在某个不确定的系统中,由很多随机的事件,如比如由连个队伍a,b 进行比赛,a获胜的概率是0.9.两只队伍分别获胜所提供的
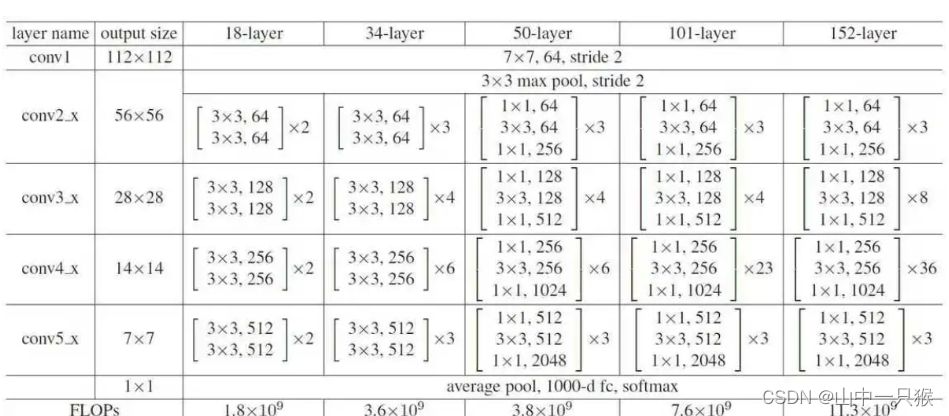
在使用pytorch进行建模时,有时候需要重新提取模型的某个特征曾,比如:在更换不同的backbone时。torchvison 提供了专门的函数create_feature_extractor()来对中间特征层进行提取,达到重构backbone的目的。
进入system 目录 :cd /etc/systemd/system。
在使用pytorch训练模型中,有时候需要从断点处继续训练,那么需要将模型、优化器、lr_scheduler,epoch和其他args进行保存,如果使用的apm混合精度,还要保存scaler。在恢复训练的时候,需要重新加载数据即可,在推理阶段,只要保存model.state_dict()就好了。
在使用pytorch训练模型中,有时候需要从断点处继续训练,那么需要将模型、优化器、lr_scheduler,epoch和其他args进行保存,如果使用的apm混合精度,还要保存scaler。在恢复训练的时候,需要重新加载数据即可,在推理阶段,只要保存model.state_dict()就好了。
链接:https://pan.baidu.com/s/17wpMzJvzSQ-a3qbaqIbmdg?

链接:https://pan.baidu.com/s/17wpMzJvzSQ-a3qbaqIbmdg?
链接:https://pan.baidu.com/s/17wpMzJvzSQ-a3qbaqIbmdg?