- @w15558056319
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
| 背景Thread.currentThread() 的返回值是在代码实际运行时候的线程对象,即当前线程。java中的任何一段代码都是执行在某个线程当中的,执行当前代码的线程就是当前线程本文中只围绕着Thread.currentThread().getName()所讲由上可知,getName()返回的是当前线程的名称| 代码示例★ 简单示例① 新建一个currentThread类,继承Thread
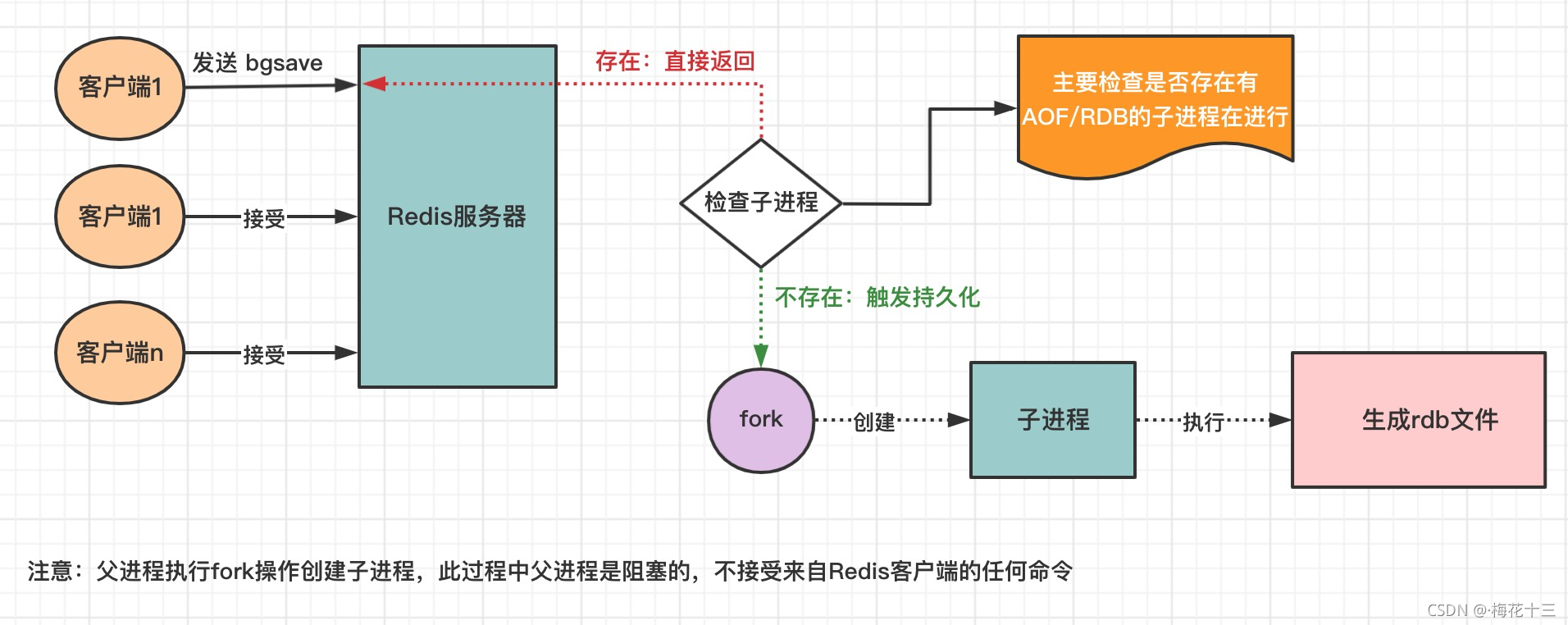
一、背景Redis作为一个内存数据库,数据是以内存为载体存储的,即所有数据都保存在内存中。一旦Redis服务器进程退出或宕机,即便重启redis服务,数据也会全部丢失。为了解决这个问题,Redis提供了持久化机制,说白了就是把数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据!★ Redis提供2种持久化方案:RDB 将在内存中的数据库记录定期生成快照存入磁盘中AOF 将Reids的操作日
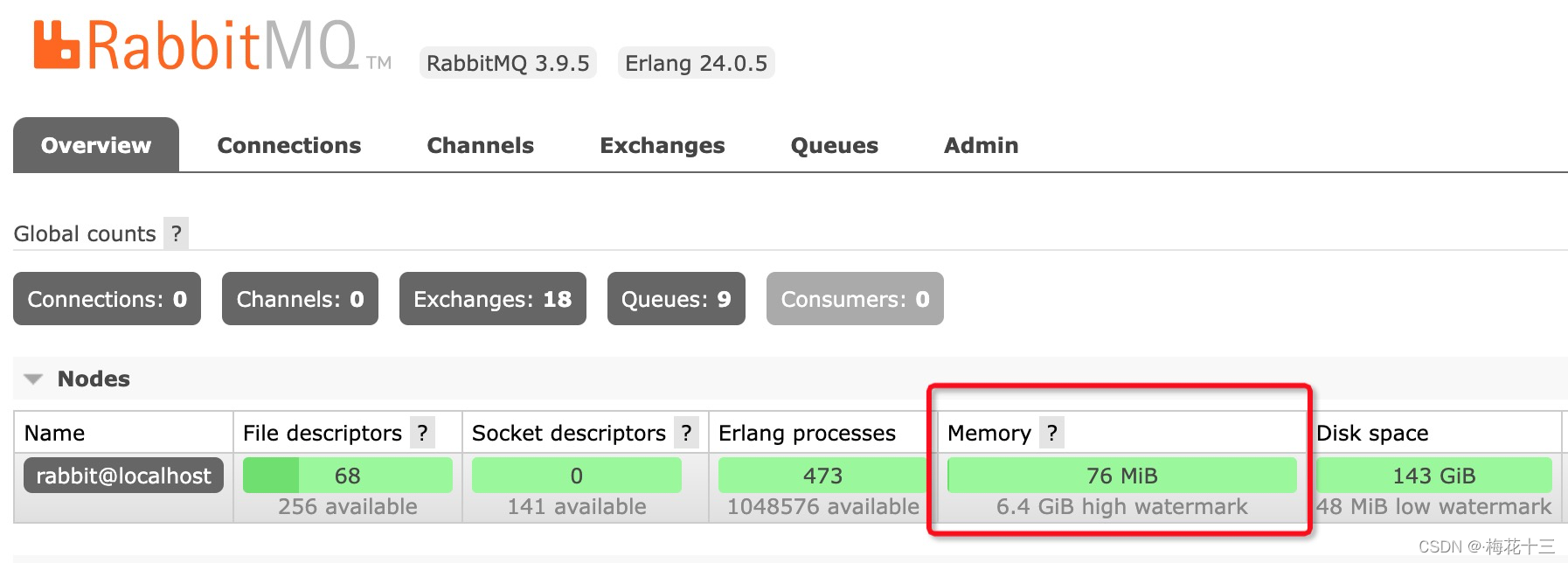
RabbitMQ作为一个异步存储消息的中间件,并不是无休止的疯狂接收消息,消息的可靠性和存储靠的是磁盘和内存,因此我们需要时刻关注服务器的内存空间和磁盘空间RabbitMQ的内存警告如下图所示,可以通过图形化界面的Memory一栏,查看RabbitMQ目前内存使用情况在Memory内存使用空间一栏中,存在2个参数,分别是:76MiB、6.4GiB high watermark76MiB:Rabbi
RabbitMQ角色分类总共分为5种角色,每个角色对应不同的权限信息1. none啥也干不了,也无法登陆到图形化界面不能访问 management plugin2. management普通管理员相当于个人中心,只查看自己的相关节点信息列出自己可以通过AMQP登陆的虚拟机查看自己的虚拟机节点virtual hosts的queues,exchange 和bindings信息查看和关闭自己的chann
二叉树的由来在 jdk1.8 之前,HashMap 的数据结构由「数组+链表」组成,数组是 HashMap 的主体,链表是为了解决 Hash 冲突引入的,正常的数据存放是直接存在数组中,但如果发生 Hash 冲突就会以链表的形式进行存储,而在 jdk1.8之后,当链表的长度超过 8 之后,将会转换成红黑树存储。清楚HashMap八股文的小伙伴应该知道,为何随着版本的迭代会引入不同的数据结构呢?数组
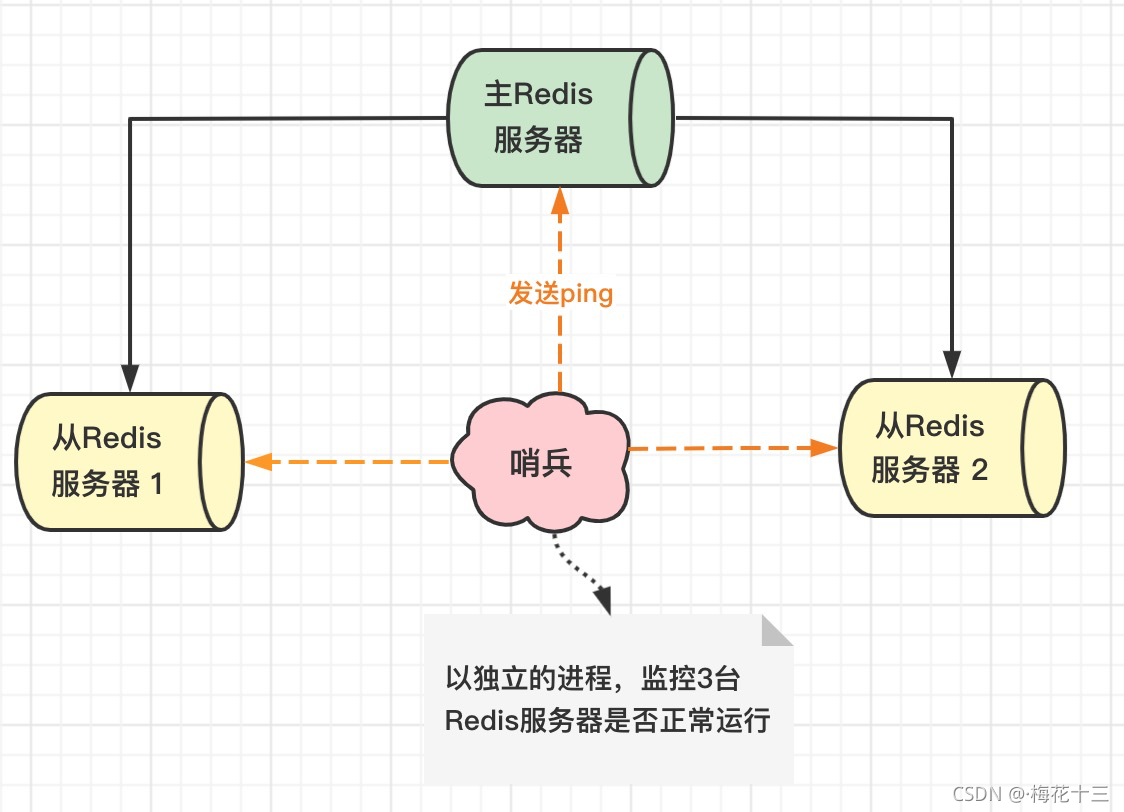
前言主从复制模式虽然能够负载均衡,减轻主机压力,但配置过程中需要注意:一旦主机挂载过多的从节点,当主机故障重启后,多个从节点同时发起复制,导致复制风暴全量复制会触发bgsave,主节点首先需要fork子进程将当前数据保存到RDB文件中,然后再将RDB文件通过网络传输到从节点,那么就会产生2个问题:fork的过程主节点是阻塞的如果主节点在fork子进程+保存RDB文件时耗时过多,可能会导致从节点长时
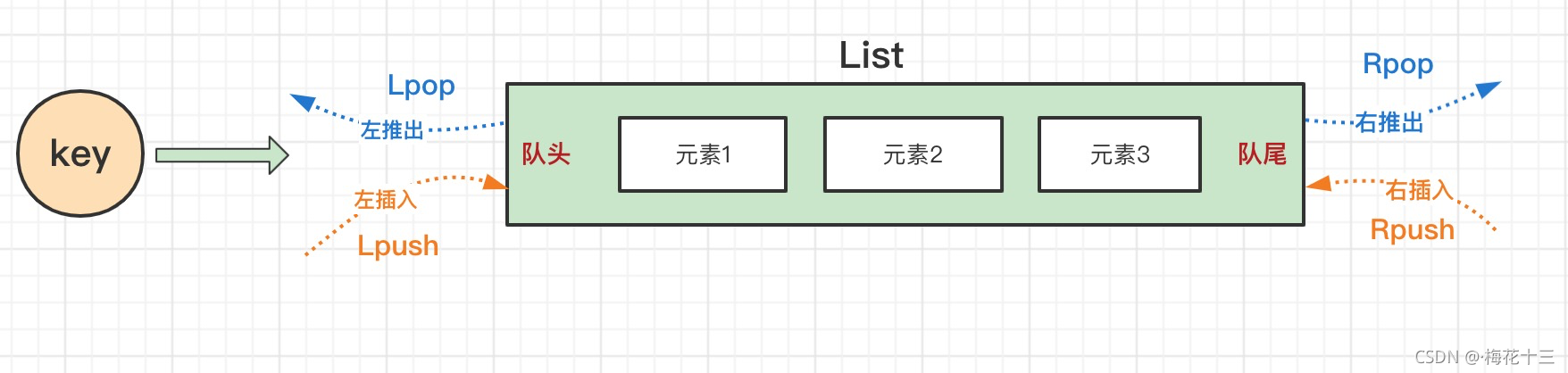
Redis五大数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)及Zset(sorted set:有序集合)。一、介绍列表(list)用于存储多个有序的字符串。可以充当栈和队列的角色一般有序会采用数组或者是双向链表,其中双向链表由于有前后指针实际上会很浪费内存。二、操作命令操作类型命令添加rpush、lpush、linsert修改lset删除lpop、rp...
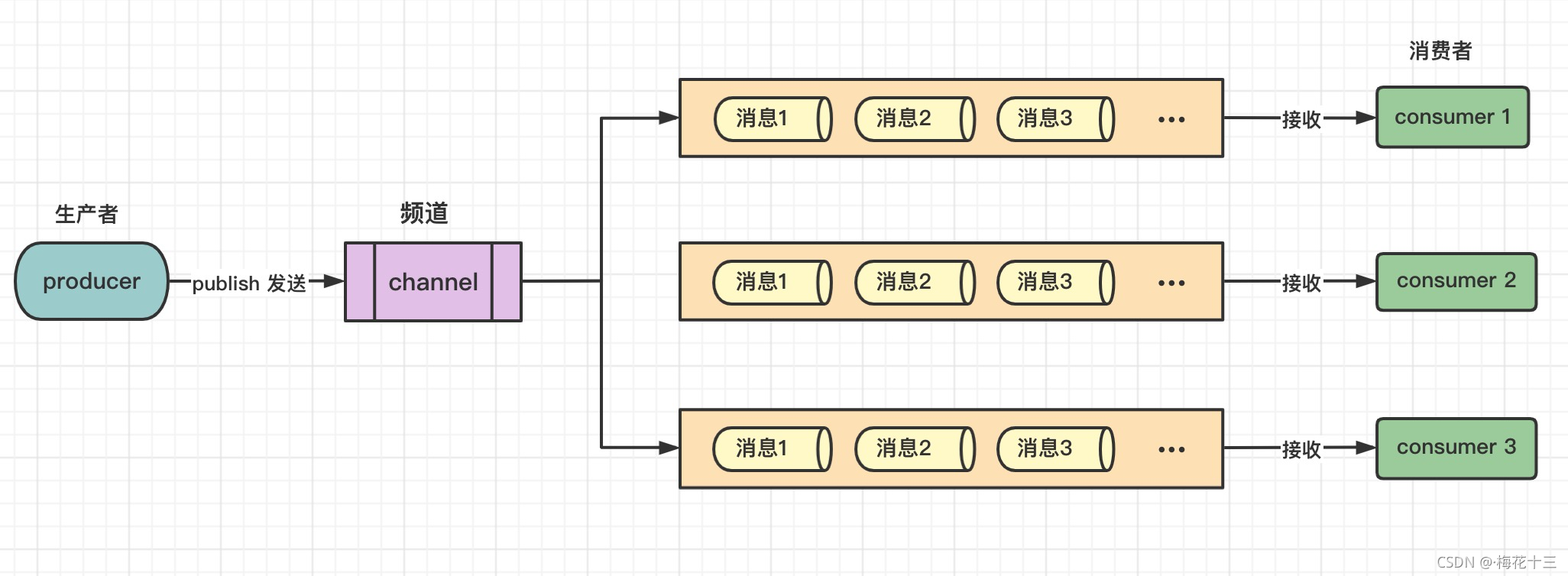
什么是发布订阅?Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 的 subscribe命令可以让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就会被发送给所有订阅指定频道的客户端。☛ 下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 cli