- @vivo_tech
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍 vivo 线下门店「大头贴」拍照合成打印一体化桌面应用软件的技术方案。该项目基于 Tauri 2.0 + Rust + Vue 3 构建,实现了手机实时投屏、智能拍照、Live Photo 处理、模板合成、视频生成、跨平台打印等核心能力,为门店用户提供沉浸式拍照体验。
作者通过使用Vibe Coding和Claude Code等AI编程工具的实践经验,分享了与AI协作的方法和技巧。文章探讨了当前AI工具与理想中"贾维斯"智能助手的差距,包括缺少持续记忆、意图理解需反复对齐、决策点过于依赖人工等问题。作者提出了通过模板化常见场景、记录决策过程、优化沟通方式等方法来改进人机协作模式,并构想了一个包含记忆层、执行层、学习层的AI组织者系统,为实现更智能的人机协作提供了
MagicWorld 针对当前视频世界模型在长时间交互中易出现运动不合理与场景崩坏的问题,提出了一种面向长时稳定性的交互式建模框架。该方法通过引入基于光流的运动约束提升动态真实性,利用历史检索机制增强跨时间一致性,并通过多步聚合的训练策略优化整体交互序列质量,从而有效缓解误差累积问题。整体上,MagicWorld 实现了在长时间交互下更加稳定、一致的世界生成能力。
我们团队提出了 LiveMoments,这是首个专门针对 Live Photo 重选封面帧画质修复的解决方案,已被 ICLR 2026 录用。针对用户重选封面时面临的画质降级痛点,我们利用 Live Photo 自带的原始高清封面作为参考,构建了一个包含运动对齐模块的参考引导扩散模型。该方法有效解决了两帧之间因时间偏移产生的运动错位问题,成功将低质的重选帧修复至高清水平,让用户捕捉的每一瞬间都能拥
最近在做知识库问答输入框的 @文档 能力,表面上是“输入 @ 后选一个文档”的小需求,实操后发现核心难点在于编辑器稳定性。本文按真实心路历程展开:先讲最直觉的 DOM 方案与踩坑,再讲为什么转向 ProseMirror,并给出 @文档 的落地实现。
本文介绍AI导购技术在 vivo 官网 APP 的落地实践,通过定义解决问题的边界能力、搭建多层架构方案、方案落地这三大块内容逐步递进地展开 AI 导购在为用户服务的应用过程。
本文介绍AI导购技术在 vivo 官网 APP 的落地实践,通过定义解决问题的边界能力、搭建多层架构方案、方案落地这三大块内容逐步递进地展开 AI 导购在为用户服务的应用过程。
我们围绕三大业务场景(笔记、知识库、项目管理)统一了一套可组合的 AI Agent 能力。本文聚焦一期「Chat 模式」落地:强调 Runtime Adapter 的“协议无关、面向任意后端流”特性——只要后端能够以流式输出事件,前端即可通过统一的 Adapter 转为标准消息模型进行渲染与编排。我们以“统一消息模型 + Runtime Adapter + 前端编排”的方式,将工具调用、Agent
我们围绕三大业务场景(笔记、知识库、项目管理)统一了一套可组合的 AI Agent 能力。本文聚焦一期「Chat 模式」落地:强调 Runtime Adapter 的“协议无关、面向任意后端流”特性——只要后端能够以流式输出事件,前端即可通过统一的 Adapter 转为标准消息模型进行渲染与编排。我们以“统一消息模型 + Runtime Adapter + 前端编排”的方式,将工具调用、Agent
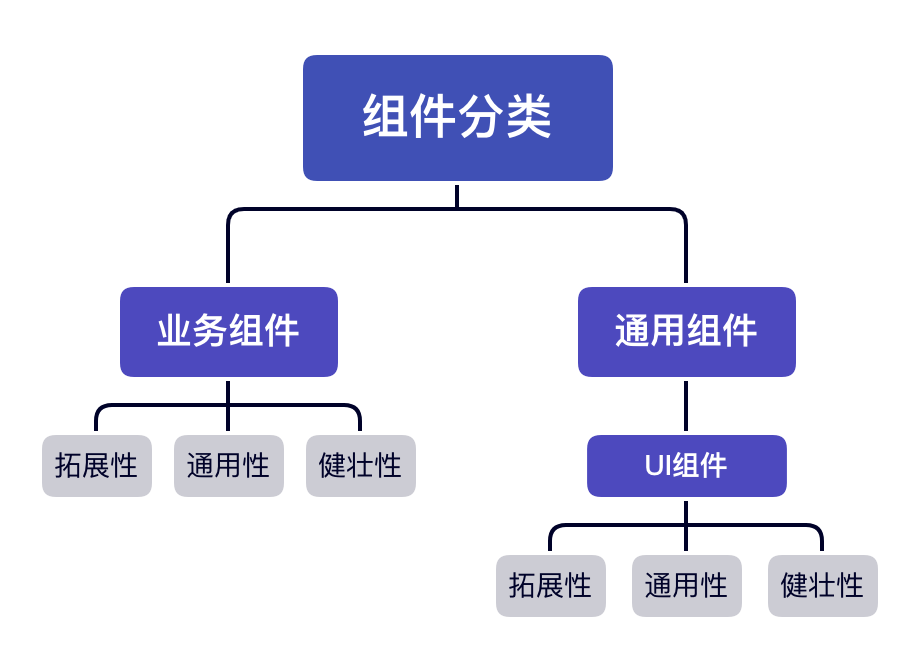
本文主要介绍了BI数据可视化平台建设中比较核心的筛选器组件, 涉及组件分类、组件库开发等升级实践经验,通过分享一些对交互和业务耦合度高的组件开发迭代的思考,希望可以给正在做组件重构解耦的读者带来启发。