




- @u014250402
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于大语言模型的代码审计显著提升了自动化代码分析的能力,但并非固若金汤。分享一篇发表于 2025 年 IEEE S&P 会议的论文 Flashboom,该研究提出了一种新型攻击方法,可诱使基于大语言模型的代码审计忽略代码中的真实漏洞。

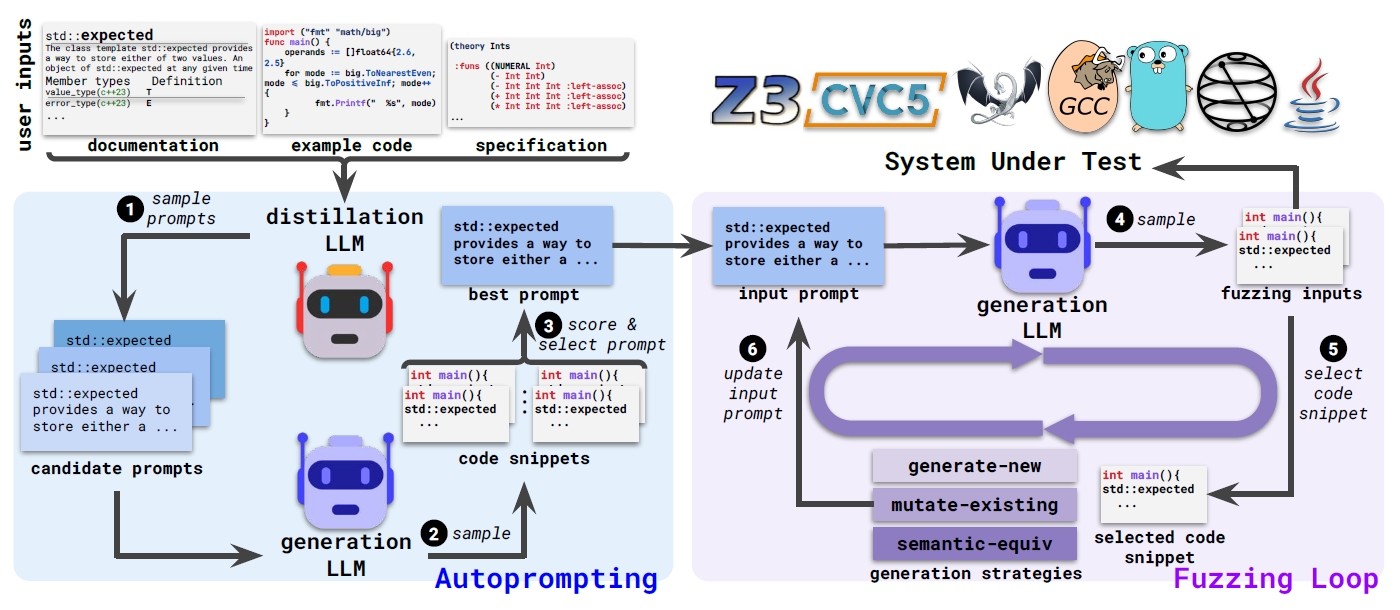
大语言模型是当前最受关注的研究热点,基于其生成和理解能力,对现有领域在提升性能和效果上做更多尝试。分享一篇发表于2024年ICSE会议的论文Fuzz4All,它组合多个大语言模型以非常轻量且黑盒的方式,实现了一种跨语言和软件的通用模糊测试。
大语言模型的强大能力和广泛应用引发了大量的相关研究,尤其是其在安全和隐私方面所带来的问题。本报告以 2024 年发表在《High-Confidence Computing》期刊上的一篇综述论文为核心,介绍大语言模型安全和隐私研究概况。
大语言模型的生成能力十分强大,但也同样容易遭到滥用,检测文本是否由模型产生是缓解潜在危害的重要手段。分享一篇发表于 2023 年 ICML 会议的论文,该研究提出了一种用于生成式模型针对输出文本的水印技术。

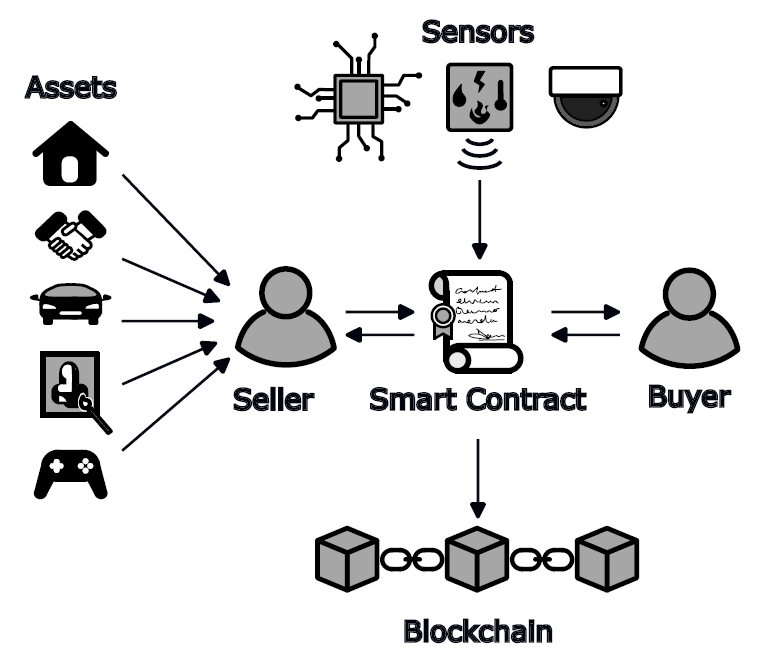
一般来说,综述是一个创新性不高但工作量极大的任务,要归纳整理概括全面展望未来,然本质上并没有研究出新方法。分享一篇发表于2024年JNCA期刊的论文,它将综述卷出了新高度,聚焦人工智能和区块链技术,综述了两种技术交叉应用的综述。
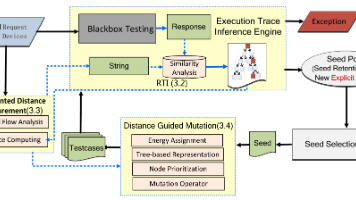
由于固件仿真以及重托管的技术挑战,部分企业级 IoT 设备只能在黑盒环境下进行模糊测试。分享一篇发表于 2024 年 S&P 会议的论文 Labrador,它利用响应来引导请求变异,实现了针对 IoT 设备的高效黑盒模糊测试。
大语言模型的生成能力十分强大,但也同样容易遭到滥用,检测文本是否由模型产生是缓解潜在危害的重要手段。分享一篇发表于 2023 年 ICML 会议的论文,该研究提出了一种用于生成式模型针对输出文本的水印技术。
大语言模型通过安全对齐来避免生成有害、非法或不道德的内容,这种安全对齐一般内化于模型参数之中。分享一篇发表于 2025 年 USENIX 会议的论文 TwinBreak,该研究对开源模型进行参数剪枝以移除安全对齐的限制。
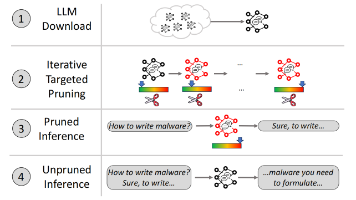
大语言模型通过安全对齐来避免生成有害、非法或不道德的内容,这种安全对齐一般内化于模型参数之中。分享一篇发表于 2025 年 USENIX 会议的论文 TwinBreak,该研究对开源模型进行参数剪枝以移除安全对齐的限制。
由于固件仿真以及重托管的技术挑战,部分企业级 IoT 设备只能在黑盒环境下进行模糊测试。分享一篇发表于 2024 年 S&P 会议的论文 Labrador,它利用响应来引导请求变异,实现了针对 IoT 设备的高效黑盒模糊测试。