




- @u013978512
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在看swagger的源码的时候,发现swagger大量使用了spring-plugin,这个组件在其他地方并不常见,看了其Github:https://github.com/spring-projects/spring-plugin。被称为世界上最小的插件系统,看源码结构,可以看到确实很小,只有那么几个类而已:下面用spring plugin写一个例子:@Configuration@EnableP
1、spring-boot项目中启动mybatismybatis在提供了mybatis-spring-boot-autoconfigure,用于spring-boot项目中自动加载注入mybatis类,这里采用了springboot指定SPI规范,SPI规范可参考https://blog.csdn.net/u013978512/article/details/111088250在mybatis-s

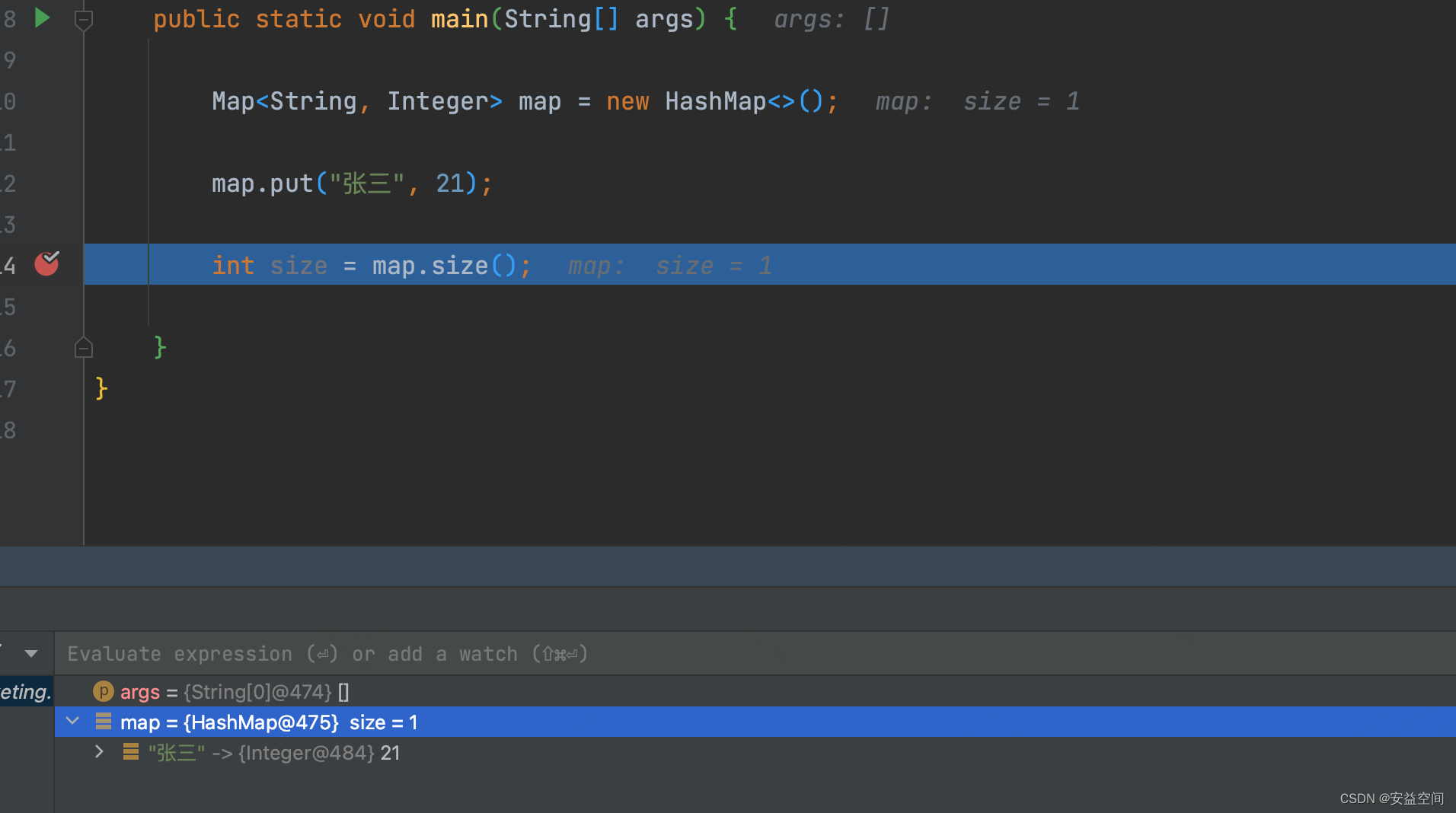
在用idea 进行 debug时,我们经常喜欢对某行代码打断点,然后对某个对象重新设置值,以快速地实现我们预期想覆盖的场景。通常的方式是用鼠标右键点击某个对象,然后选择。进行设置值,但是如果想在map中添加新的key value,这种方式就爱莫能助了,针对这个场景,我们可以采用Evaluate Expression实现。当然了,直接通过Evaluate Expression的图标直接进入Evalu
系列文章目录提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加例如:第一章 Python 机器学习入门之pandas的使用提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档日志初始化过程分析1、前言上一篇文章我们讲了日志的发展史,在日志组件发展的过程中,为了使得日志组件过多的耦合在业务中,所以,在组件迭代的过程中,通过面向门面编程的思想,逐渐形成了上层门面接口和下层业务
当做好图后,对需要修改的曲线双击,然后在droplines 里将skip points 数目增大即可。
二是在配置中心的使用过程中,用户可能随时新增配置监听,而在此之前,长轮询可能已经发出,新增的配置监听无法包含在旧的长轮询中,所以在配置中心的设计中,一般会在一次长轮询结束后,将新增的配置监听给捎带上,而如果长轮询没有超时时间,只要配置一直不发生变化,响应就无法返回,新增的配置也就没法设置监听了。在上面长轮询的图中我们看到,客户端侧标注了一个timeout时间90s,服务端最长的hold时间是80s
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。在讲全文
一、synchronized 的有序性Java 里的操作无序现象是什么?《深入理解 Java 虚拟机》- P374:如果在一个线程观察另一个线程,所有操作都是无序的指的是 “指令重排序” 和 “工作内存与主内存同步延迟” 现象。指令重排是JVM层面对程序进行的优化措施,如果不深入了解,则在并发编程时可能会发生难以发现的Bug。截止JDK1.8, Java 里只有 volatile 变量是能实现禁止
https://blog.csdn.net/qq_26323323/article/details/84938892这篇文章对spring-kafka消费端源码分析较为详细,可查看其customer初始化的过程。整个初始化的开始是从@EnableKafka开始讲起的初始化的工程归纳如下:得到一个含有KafkaListener基本信息的Endpoint,最后Endpoint被封装到KafkaList