




- @u013010473
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入剖析 OpenClaw 的 Embedding 引擎层。系统支持 OpenAI、Gemini、Voyage、Mistral、Ollama、Local 六大提供商,通过 auto 模式自动选择最佳提供商,并具备 Fallback 降级回退能力。

Claude Code 19 工具按 6 类分;工具注册表把权限收敛是企业 AI 平台最高杠杆。深入三层权限管线(auto / classifier-prompt / approval,分类器不看模型自言自语以防注入)、6 种 permission_mode,叠加 OpenDev 5 层纵深防御。结论:reasoning 与 enforcement 分两条 code path,jailbreak

系列终篇。先回顾前 6 篇,再切两栏:已成熟 5 条(loop、CLAUDE.md、subagent 隔离、auto-compact、3 层权限)vs 6 个开放问题(HaaS、自适应 harness、NLAH、形式化与 benchmark、共训练、长期人类能力)。一句话收尾:harness engineering 是 LLM 时代的 systems engineering,不会消失,只会变形。

把 harness engineering 当工程学科:5 大配置面(CLAUDE.md / 命令 / hooks / MCP / skills)+ 12 条实战(Ratchet、start-minimal、删多余 server、人手写、明示禁忌、A/B test、CLI 比 MCP 轻、随模型 prune 等)+ 4 案例(Manus 5 次重写、Vercel 删 80% 工具、LangChai

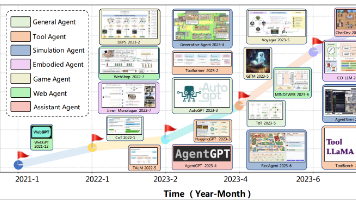
本文系统性地介绍了AI Agent(人工智能代理)的发展现状与核心技术架构。文章首先阐述了AI Agent的概念定义,指出其相比传统LLM实现了从"知道如何做"到"能够去做"的质变飞跃,具备自主性、反应性、主动性和社交能力等核心特征。然后详细剖析了AI Agent的五层核心架构:大脑(LLM作为控制器)、感知模块(多模态信息接收)、规划模块(任务分解与决策)
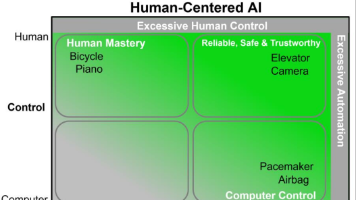
本文探讨了人机协作(Human-Agent Collaboration)的理论与实践,重点分析了Human-in-the-Loop(HITL)系统的设计理念与应用场景。文章从工具到伙伴的范式转变出发,系统阐述了HITL在教育、医疗和创意领域的实践案例,包括AI学习伙伴、医疗诊断辅助和创意协作等应用。同时深入探讨了人机协作中的信任机制、控制权分配等核心问题,提出了协作层级架构和自适应机制的设计方案。
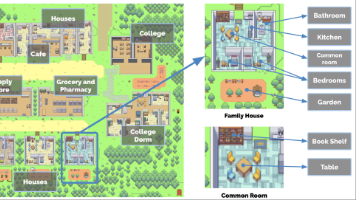
本文系统探讨了AI Agent社会模拟的前沿研究,聚焦于如何让多个智能体在虚拟环境中涌现类人社会行为。文章从斯坦福小镇实验出发,介绍了生成式智能体的核心架构设计,包括记忆流、反思机制和行为规划系统。同时深入探讨了可扩展的社会模拟框架AgentSims,以及认知建模、情感模拟、人格特质等关键技术。研究揭示了AI如何通过模块化心智架构模拟人类社会复杂动态,包括群体行为、信息传播和社会网络形成。最后提供
本文是系列完结篇,聚焦记忆系统的"动态"部分。详细分析了基于 chokidar 的文件监听与 1500ms 防抖策略、基于 hash 比对的增量同步引擎、从 JSONL 对话历史中自动提取记忆的会话记忆系统(实验性)、SQLite 只读自动恢复机制,以及 memory_search/memory_get 工具的安全路径验证实现。最后提供完整的配置优化实践指南,并总结 OpenClaw 记忆系统在隐

本文从设计哲学、整体架构和核心模块三个层面,系统拆解 OpenClaw 记忆系统的全貌。OpenClaw 以"文件即记忆"为核心理念,采用 Markdown 文件作为记忆载体,SQLite + sqlite-vec + FTS5 构建全本地化存储栈,实现人机协同的透明记忆管理。文章详细分析了三层继承的管理器架构(Sync → Embedding → Index)、渐进增强的三级能力模型(FTS-o

本文深入剖析 OpenClaw 的 Embedding 引擎层。系统支持 OpenAI、Gemini、Voyage、Mistral、Ollama、Local 六大提供商,通过 auto 模式自动选择最佳提供商,并具备 Fallback 降级回退能力。