




- @u012848304
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
容器化部署似乎成了当前一个非常主流的趋势,无论是前端还是后端,流行的操作就是给你一个镜像地址,让你自己去拉取镜像并运行镜像。这似乎是运维的工作,但是在没有专有运维的情况下,不得不自己先了解一下。docker相对来说还是比较麻烦的,需要对服务器有一定的了解,还要对Linux命令比较熟练,然而我对这两个都不熟悉,摸索了一段时间,记录一下自己打包docker镜像的完整过程。

写在前面这应该是本年度的最后一篇技术博客了,今年在CSDN上总共发表了20篇博客,除掉几篇LeetCode的博客,都是个人工作的总结,总体来说,收获不少,随手记录的习惯也养成了。希望来年持之以恒。这篇博客主要介绍的是百度AI开放平台的OCR识别,包括文字识别和车型识别,个人感受是功能强大,但也还有提升的空间。语言环境:Python3.7编译工具:Spyder相关接口和秘钥申请首先上两个接口的地址:
记录一下开源大模型的后端调用接口过程。

记录一下开源大模型的后端调用接口过程。
随着高考分数公布,填报大学和专业成了各位家长最重要的事情,这两天有好几位亲戚朋友咨询专业填报的事情,发现了一个网站内容不错,提供了各个学校各个专业的最低分数线和最低录取名次,网站链接在这里,这个就是计算机类专业在浙江招生的情况,专业可以换掉。这个页面的内容还是很简单的,但是他的分页(不同年份)通过get请求没法体现,应该是用前后端分离的模式开发的,所以通过网页请求来爬虫可能不太容易实现,所以使用了
记录一下开源大模型的后端调用接口过程。
记录一下开源大模型的后端调用接口过程。
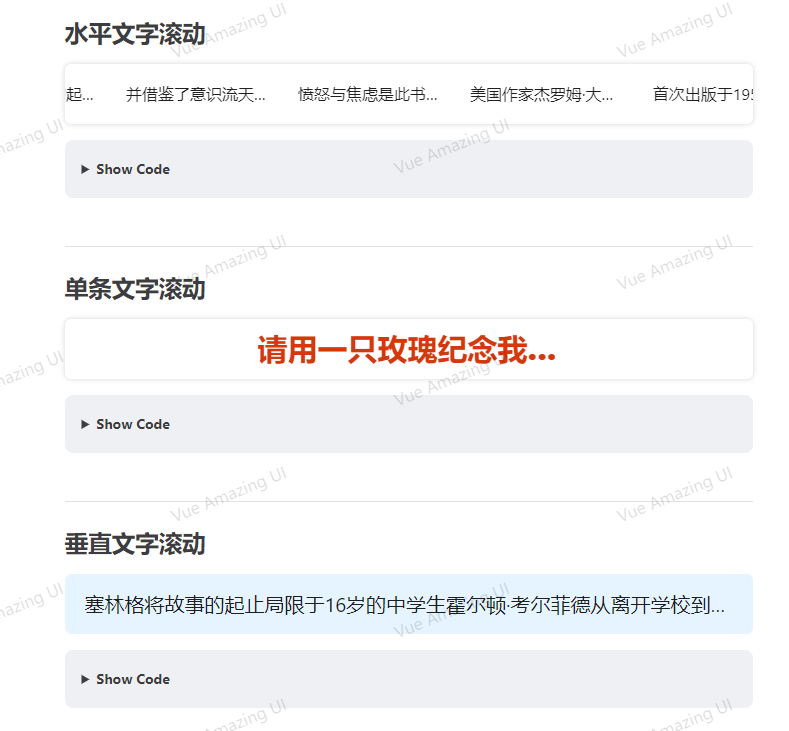
之前UI框架一直使用的elementPlus,有个需求,需要在页面上写个滚动播放新闻的功能,发现UI框架居然没有这个组件。花了一下午,在ChatGPT的帮助下,总算写成功了,先看最终展示效果web页面滚动播放文字视频被压缩的稀烂了,GIF又没法上传,截个图看看吧直接上代码:
引言pyecharts作为Python的数据可视化包,其强大的功能不言而喻,Python + Echart,想想就觉得牛叉。目前pyecharts有两个大的版本,一个是0.5.x版本的,一个是1.0以后版本,而且这两个版本差别很大。如果是有的选,肯定优先选择1.0版本的,功能要比0.5.x版本的强大得多,而且支持链式调用。但是肯定也有不少用不惯1.0及后续版本的同仁。博主因为之前一直用的是0...
记录一下开源大模型的后端调用接口过程。