- @u010026928
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 本文探讨了AI Agent从问答系统向执行系统的演进,提出了面向智能体时代的本地化安全评估框架ASDL(Agent Security Development Lifecycle)。随着AI Agent在生产环境中执行复杂任务(如调用工具、触发支付等),传统模型安全已无法覆盖“做错事”的风险。文章分析了核心攻击面(如Prompt Injection升级为工具误用、MCP工具链污染),并基于O
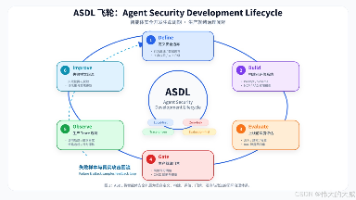
摘要: 本文探讨了AI Agent从问答系统向执行系统的演进,提出了面向智能体时代的本地化安全评估框架ASDL(Agent Security Development Lifecycle)。随着AI Agent在生产环境中执行复杂任务(如调用工具、触发支付等),传统模型安全已无法覆盖“做错事”的风险。文章分析了核心攻击面(如Prompt Injection升级为工具误用、MCP工具链污染),并基于O
摘要: 本文探讨了AI Agent从问答系统向执行系统的演进,提出了面向智能体时代的本地化安全评估框架ASDL(Agent Security Development Lifecycle)。随着AI Agent在生产环境中执行复杂任务(如调用工具、触发支付等),传统模型安全已无法覆盖“做错事”的风险。文章分析了核心攻击面(如Prompt Injection升级为工具误用、MCP工具链污染),并基于O
本文介绍了一套无人值守的自动化测试系统,通过AI Agent技术解决现有测试套件的运维痛点。系统采用分层架构:确定性脚本层负责测试执行(Playwright)、质量门校验和结果处理;推理层(Claude Code)仅在需要判断时介入,如用例生成、失败分诊等;控制层(Hermes)负责调度和通知。关键创新点包括:测试期望值源自PRD而非代码实现、大模型不进热路径以控制成本、完善的失败处理流程(自动区
把 Claude Code 跑在自己的 Mac / 服务器上,然后用iPhone 随时随地远程操控,是很多人想要的工作流。开源项目正好干这件事:它给 Claude Code 套了一层端到端加密的中转通道,手机当远程终端。官方有云端中转,但国内网络 + 隐私 + 用 API Key / Bedrock的同学,更适合自托管。我在一台 AWS ARM 服务器上把这套完整跑通,中间踩了一堆坑(401、令牌
本文详细记录了在 NVIDIA Grace (ARM64) 架构服务器上,不使用 Docker 容器,而是直接通过 Python 环境源码运行 vLLM 来部署 BGE-M3 Embedding 服务的全过程。该方案解决了 ARM 架构下 HuggingFace TEI (Text Embeddings Inference) 官方镜像不兼容的问题,并实现了极低的显存占用。
Fastgpt部署和模型接入
本文提供了LangChain与Ollama集成的完整环境配置指南,包含Python虚拟环境创建、依赖安装(Ollama相关组件)、Ollama服务部署(含模型下载)等步骤。重点演示了三个基础使用场景:通过ChatOllama实现简单对话交互、利用提示模板生成烹饪指导、以及构建多轮对话系统。示例代码展示了如何初始化模型、设计提示模板并处理响应,其中红烧肉案例详细解析了思考过程和烹饪步骤,体现了模型的

本文介绍了一套无人值守的自动化测试系统,通过AI Agent技术解决现有测试套件的运维痛点。系统采用分层架构:确定性脚本层负责测试执行(Playwright)、质量门校验和结果处理;推理层(Claude Code)仅在需要判断时介入,如用例生成、失败分诊等;控制层(Hermes)负责调度和通知。关键创新点包括:测试期望值源自PRD而非代码实现、大模型不进热路径以控制成本、完善的失败处理流程(自动区
随着大型语言模型 (LLM) 的普及,隐私保护和长期记忆能力成为个人 AI 助理(Personal Agent)发展的关键瓶颈。如果将所有对话历史和私有文档都通过 API 上传给云端模型,不仅存在隐私风险,还会带来高昂的 API 调用成本。本文将分享一套零隐私泄漏、全链路本地化推理与存储的 AI Agent 架构最佳实践。