




- @try2find
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章摘要:本文探讨了对话系统中思考过程(tokenize)处理的优化方法。初始设计将思考过程(reason)错误地包含在指令(instruction)部分,导致其未被纳入训练目标。改进方案将思考过程作为助理(assistant)回复的一部分,包括在标签(labels)中以计算损失。修正后的代码结构分为三部分:1) 系统提示和用户问题(忽略损失);2) 助理完整回复(含思考过程和最终答案);3) E
挂载云硬盘fdisk-l列出所有盘mkfs.ext4/dev/vdb格式化mount/dev/vdb/data盘挂载好了以后,记得在启动文件/etc/fstab里面也要加启动挂载的选项,否则重启就没了查看已挂载盘符:显示所有盘:格式化;挂载盘符:配置启动挂载:
经过排除发现是软件自动升级了,导致启动不了。
1.安装NVIDIA容器工具包先验证NVIDIA驱动安装(nvidia-smi)使用更新后的方法安装工具包(避免弃用的apt-key)配置Docker使用NVIDIA运行时2.解决依赖冲突彻底卸载旧版本Docker和containerd清理残留配置文件使用--fix-broken修复依赖关系3.优化配置修改Docker存储目录位置正确设置容器资源限制(CPU/GPU内存)调整容器命名和管理方式
文章摘要:本文探讨了对话系统中思考过程(tokenize)处理的优化方法。初始设计将思考过程(reason)错误地包含在指令(instruction)部分,导致其未被纳入训练目标。改进方案将思考过程作为助理(assistant)回复的一部分,包括在标签(labels)中以计算损失。修正后的代码结构分为三部分:1) 系统提示和用户问题(忽略损失);2) 助理完整回复(含思考过程和最终答案);3) E
chatchat实现rag对话
这个错误表明你设置了 metric_for_best_model="eval_accuracy" ,但在评估过程中并没有计算 accuracy 指标。可用的评估指标只有: ['eval_loss', 'eval_runtime', 'eval_samples_per_second', 'eval_steps_per_second', 'epoch']。
方法 1:手动检查最新版本并下载 访问 Ollama 的 GitHub Releases 页面:打开方法 2:使用官方安装脚本(推荐该脚本会自动检测系统架构并下载最新版本 安装完成后,运行 ollama pull llama3 测试方法 3:使用 AppImage(免安装)如果仍然无法下载,可以直接使用安装完成后查看ollama版本。
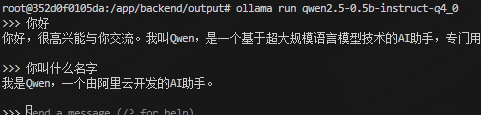
如果ollama服务中没有可用的模型,需要ollama run加载模型。
具体步骤如下:1、下载源码包,包名为:Qtlibraries 4.8.5 for Linux/X11 (230 MB),下载路径如下:http://qt-project.org/downloads2、解压将压缩包拷贝到 linux 系统中的任意目录下,然后进行解压,解压命令:tar -zxvf qt-ever