




- @tilblackout
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
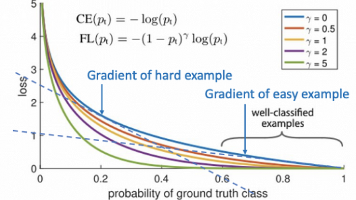
针对类别不平衡问题,Focal Loss通过引入调制因子γ和类别权重α改进传统交叉熵损失。γ降低易分类样本的损失权重,使模型聚焦困难样本;α调整不同类别的重要性。实验表明,Focal Loss能有效抑制大量简单负样本的干扰,提升模型对少数类和困难样本的学习能力,在目标检测等不平衡任务中表现优异。(144字)
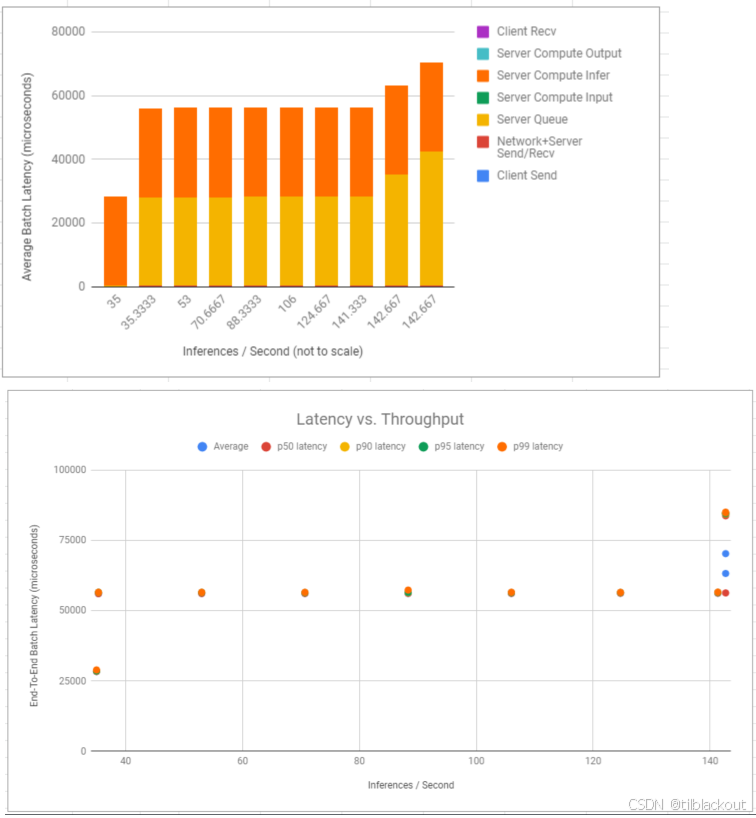
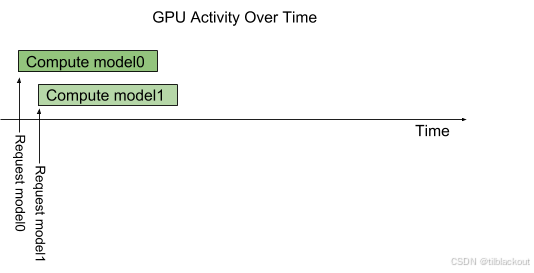
本文通过实测与分析,系统评估了Triton推理服务器的三项关键优化技术:并发执行、动态批处理与TensorRT加速。我们对比了启用与未启用优化功能的模型性能差异,发现优化后的模型在吞吐量和延迟上均有显著提升。随后,我们介绍了推理服务在生产环境中的部署架构,以及如何利用Kubernetes和Prometheus实现服务的自动扩缩容与性能监控。下一篇文章,我们将学习如何构建利用 Triton 功能的自
本项目探索了利用 BERT 模型进行作者归属识别的可行性,验证了语言模型在识别写作风格差异方面的潜力。通过构建分类模型对《联邦党人文集》中的争议文章进行分析,展示了深度学习方法在文本风格识别任务中的实际应用能力。

本文系统介绍了如何通过并发模型执行、调度策略和动态批处理来优化的推理性能。在实验中,我们观察了 GPU 利用率的变化,理解了单实例与多实例、静态批处理与动态批处理之间的差异和优势。高并发 + 小批量请求在单实例下可能导致资源瓶颈,而增加实例数量可以提升吞吐;动态批处理能有效整合多个小请求,进一步提升性能,同时减少内存开销;针对不同模型结构(有状态/无状态、单模型/集成模型),选择合适的调度方式是优
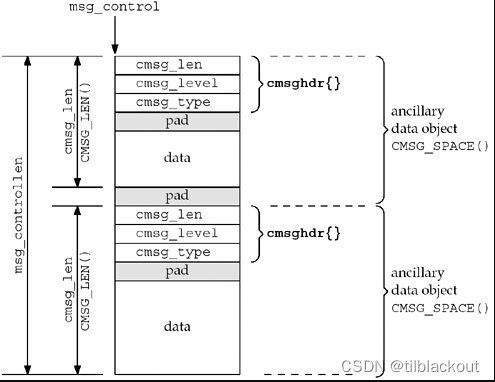
在上一篇文章中,我们对Unix套接字编程有一个基本的了解。socketpairsendmsg和recvmsg,它们为实现本地进程间通信提供了便捷的方式。
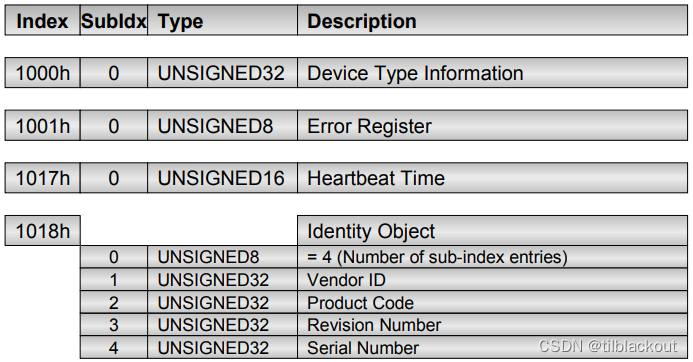
上一节,我们了解了CANopen和CAN学习(1):嵌入式网络通用术语,本节,我们将介绍CANopen协议的主要功能,以及它如何满足嵌入式网络的要求。任何 CANopen 节点的核心是对象字典(,),它是一个由位索引和位子索引组成的查找表。这允许在每个索引下最多有个子条目,每个条目可以包含一个任意类型和长度的变量。对象字典不仅提供了一种将变量与索引和子索引值关联的方法,还指定了数据类型定义表。从索
从本篇开始,我将深入学习CANopen和CAN相关知识。但在这之前,本篇文章先来了解一下嵌入式网络相关的通用术语。

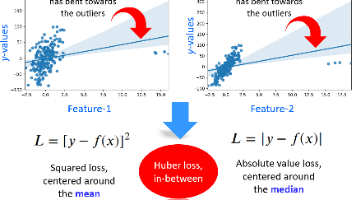
Huber回归通过结合平方损失和绝对值损失的优势,有效提升模型在离群值干扰下的鲁棒性。其损失函数以阈值δ控制误差处理方式:小误差时保持平方损失的高精度,大误差时切换为线性损失以降低离群点影响。实验对比显示,相较于传统线性回归,Huber回归在合成数据中更准确拟合真实趋势(如预测值806.72 vs 87.38)。实际应用中需平衡δ的选择,并可通过Scikit-learn快速实现。该方法的灵活性使其
架构处理器家族芯片型号(三星)ARMv3ARM6、ARM7S3C44B0ARMv4StrongARM、ARM7TDMI、ARM9TDMIS3C2440/S3C2410ARMv5ARM7EJ、ARM9E、ARM10E、XScaleARMv6ARM11、Cotex-MS3C6440ARMv7Cortex-M、Cortex-A、Cortex-RARMv8Corte..
前两节介绍了STL中的和,本节来介绍一下无序容器。无序容器与关联容器类似,但是关联容器是顺序排序的,而无序容器实现了未排序(哈希)的数据结构。
