- @tianhai12
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
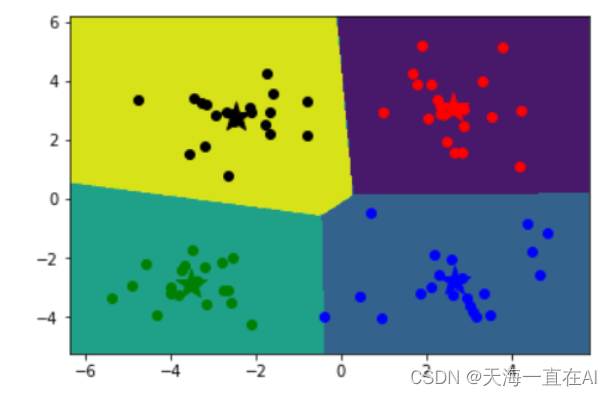
演示图片如图,又是机甲“小花”!这次使用PCA把他降维!

TF-IDF模型:基于结巴分词和wordcloud进行疫情文本数据分析
单模态学习简单易懂,适用于单一类别数据,减少人工标注成本,但数据特征提取能力有限。与多模态学习相比,单模态学习的数据丰富度和多样性较低,对数据的理解及抽象能力较弱,且无法在模态数据缺失时互相补充,导致下游任务表现不佳。自然界中真实数据多为多模态形式。
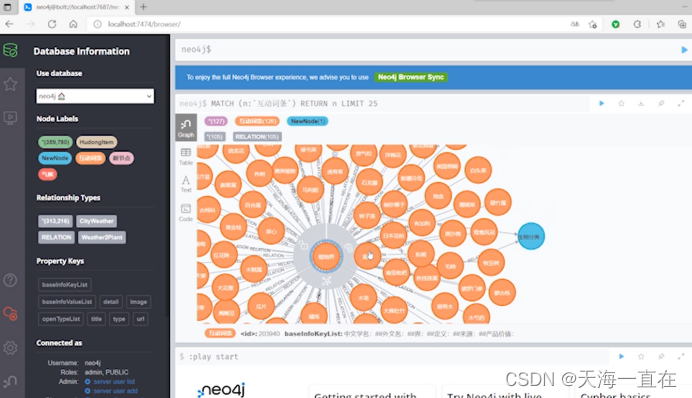
知识表示与知识图谱的概述
segment-anything的简介和grounded-segment-anything在线使用教程

python代码如下from sklearn.feature_extraction import DictVectorizerfrom sklearn import treefrom sklearn import preprocessingimport csvimport graphvizDtree = open('西瓜数据集3.0.csv', 'r')reader = csv.reader(Dt
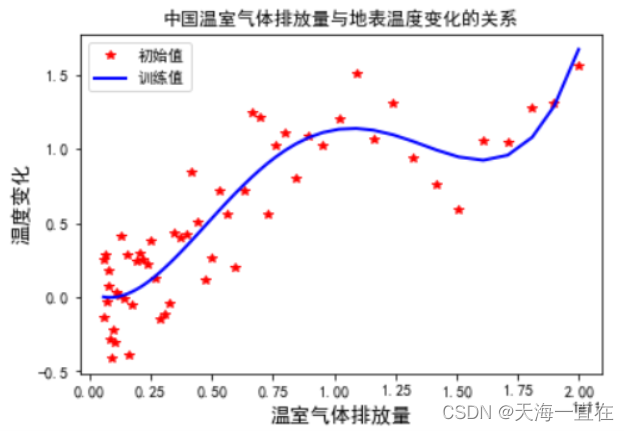
通过基于线性回归模型对1960-2010年的年份对全球气温以及二氧化碳排放量的线性关系进行建模以及探索,一共51个数数据点,通过对这51个样本的分析得出两者的线性关系预测。

使用多项式回归进行时序数据分析,还包括xlrd的使用以及plt中汉字的显示方法。
之前做了个一元的线性回归预测,机器学习:利用sklearn方法的一元线性回归模型(通过成绩预测绩点)_tianhai12的博客-CSDN博客其实拟合度不高,因为毕竟学生都有偏科现象~~所以,通过将各科成绩都作为特征向量来进行预测才会更加精确的预测绩点这里就分享一下多元线性回归模型,这里是在数学成绩后面又加了一列英语成绩二元的代码和演示效果如下import numpy as npfrom sklea
kmeans算法使用代价函数进行优化简单例子