




- @sundehui01
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Ollama 是一个开源的本地大模型部署工具,旨在简化大型语言模型(LLM)的运行和管理。通过简单命令,用户可以在消费级设备上快速启动和运行开源模型(如 Llama、DeepSeek 等),无需复杂配置。它提供 OpenAI 兼容的 API,支持 GPU 加速,并允许自定义模型开发。

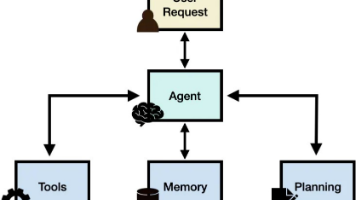
所有项目均支持「视觉识别 + ADB 操作」,核心差异在于是否依赖大模型、是否支持跨平台、稳定性 / 易用性 Trade-off。:如需 AI 驱动,集成 GPT-4o 到 Airtest/Appium,实现自然语言指令→脚本生成→执行;多模态大模型(GPT-4V/Qwen-VL)驱动,支持跨 App 复杂任务规划;纯视觉 + 控件双驱动,支持「录制操作→生成脚本」,开箱即用;
大模型对应的英文是Large Language Model(LLM),即大语言模型,简称大模型。技术层面讲,大模型是一种基于深度学习技术的机器学习模型。为什么叫大模型呢?它是相对于小模型而言的。传统的机器学习算法一般是解决某个特定领域的问题(例如文本分类),使用的训练数据集规模较小,参数也比较少。而大模型一般是基于互联网上的海量数据训练而成的,模型参数可达数十亿至数万亿。这些参数就像大脑中的神经元
随着数据中台越来越火,很多企业纷纷建起了自己的数据中台,数据中台一下子火爆起来,很多人就会存在疑问,数据中台到底是如何兴起的?数据中台演进的四个阶段:数据库阶段(OLTP联机事务处理)、数据仓库阶段(OLAP联机分析处理)、大数据平台阶段、数据中台阶段。数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。从数据角度,数据仓库更适合传统的数据库,离线采集,数据一般
其中,Transformer架构是当前大模型的主流基础架构,由Google于2017年提出,其核心是自注意力机制,能够动态关注输入序列中的不同部分,高效处理长距离依赖关系,同时支持高度并行化计算,为模型的规模化扩展奠定了关键基础。不同于传统AI模型依赖人工定义规则,大模型如同一个通过“阅读”海量数据成长的“超级学习者”,通过自主挖掘数据中的潜在模式与深层规律,实现从“机械执行”到“智能涌现”的跨越
不少用户从付费安装“龙虾”,到付费卸载“龙虾”,养“龙虾”正在成为一场智能体的狂欢。国家安全部专门发布《“龙虾”(OpenClaw)安全养殖手册》,提醒广大用户要理性辨别、规范使用,以积极的心态和慎重的执行拥抱人工智能时代,让“龙虾”成为遵规守纪、产能高效的“数字员工”。“龙虾”并非供人娱乐的数字宠物,而是能够自主执行任务、承担流程操作、持续学习成长的“数字员工”,养“虾”人应理性看待、规范使用,
AirtestIDE(可视化,新手首选)和Python 命令行版(适合独立运行脚本),核心依赖是 Python + Airtest/poco 库;核心使用流程:连接设备 → 录制 / 编写脚本 → 运行 / 调试,重点掌握clicktextswipewait等基础函数和Template图片定位;脚本稳定运行的关键:合理设置等待时间、提高图片识别阈值、避免硬编码,遇到问题优先查看 adb 连接和运行
所有项目均支持「视觉识别 + ADB 操作」,核心差异在于是否依赖大模型、是否支持跨平台、稳定性 / 易用性 Trade-off。:如需 AI 驱动,集成 GPT-4o 到 Airtest/Appium,实现自然语言指令→脚本生成→执行;多模态大模型(GPT-4V/Qwen-VL)驱动,支持跨 App 复杂任务规划;纯视觉 + 控件双驱动,支持「录制操作→生成脚本」,开箱即用;
目录1、项目中哪些业务场景使用了缓存2、为什么使用缓存?3、redis 和 memcached 有什么区别?redis 的线程模型是什么?为什么 redis 单线程却能支撑高并发?4、redis有哪些数据结构5、redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的?6、redis有哪些内存淘汰策略?7、redis内存过期策略?8、如何应对缓存雪崩、缓存穿
前面的章节,系统雏形已经初步形成,前端项目的展示数据为固定数据活mock数据,今天我们来一起完善后端项目架构。一、前后交互规范前后端通过RESTful接口规范进行交互,Swagger是规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。Swagger 让部署管理和使用功能强大的 API 。1、添加pom依赖<dependency><groupId