




- @stone1290
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
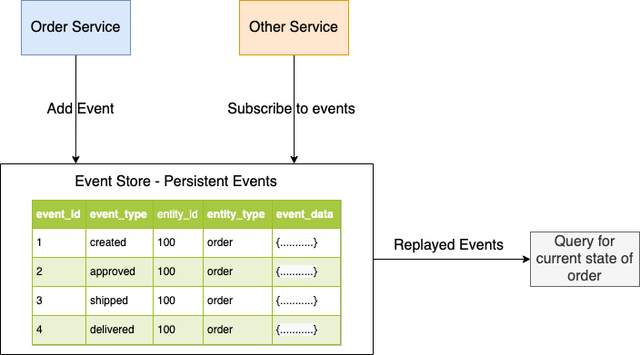
最近参与公司项目研发,在其中发现对于数据的管理存在一些小问题,根据以往经验,在这里记录下微服务数据设计模式。微服务架构中的服务是松耦合的,可以独立开发、部署和扩展。每个微服务都需要不同类型的数据和存储方式,也因为这样每个微服务都有自己的数据库。...
推荐引擎是根据用户过去的行为和偏好向用户提供个性化推荐的一系列算法。这些引擎通常被在线购物、音乐流媒体平台、在线约会、新闻媒体、视频游戏平台、旅游预订网站、社交媒体平台和其他行业使用。他们使用有关用户及其与产品或内容的交互的数据来建议用户可能感兴趣的项目。推荐引擎用于通过提供个性化的推荐来改善用户体验。
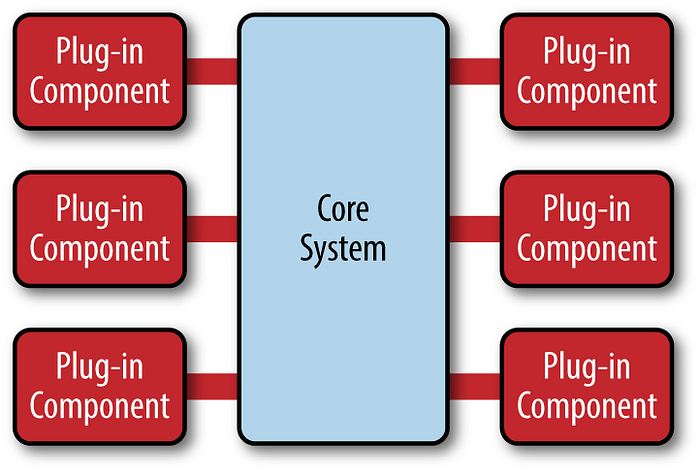
内核模式也被称为插件架构模式。将附加应用程序功能作为插件添加到核心应用程序,以提供可扩展性以及功能分离和隔离。这种模式由两种类型的架构组件组成:一个核心系统和插件模块。应用程序逻辑分布在独立的插件模块和基础核心系统之间,提供应用程序特性和定制处理逻辑的可扩展性、灵活性和隔离性。从业务应用的角度看,核心系统通常被定义为没有特殊情况、特殊规则或复杂条件处理的定制代码的通用业务逻辑。
Java 是当今最流行的编程语言之一,常年位居最受欢迎编程语言排行榜前三。一个优秀的java程序员,在研发时离不开对测试框架的了解,从而开发出更安全和更高效的代码。使用这些测试框架的其中一个最重要的原因是减少出错的可能性,提高开发效率,并降低研发成本。在本文中,我们将介绍用于 Java 测试的最常见的测试框架。...

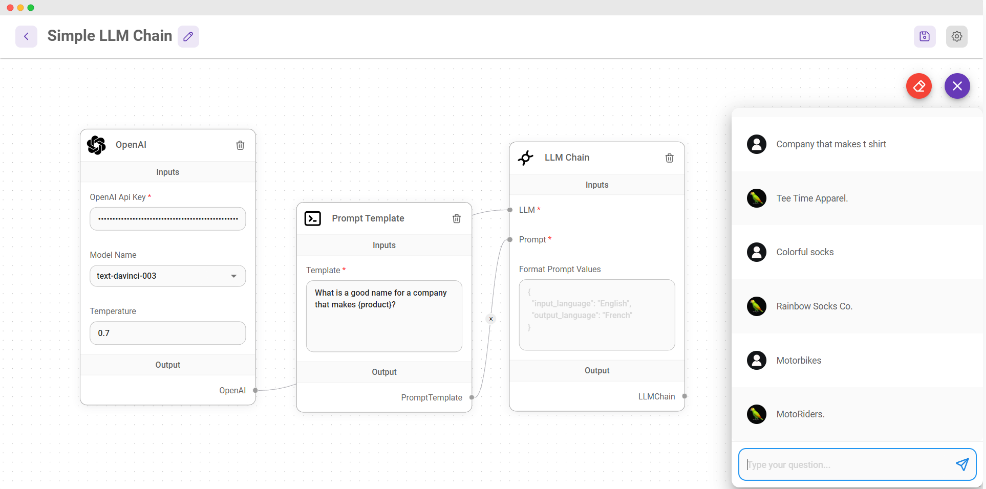
随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个N
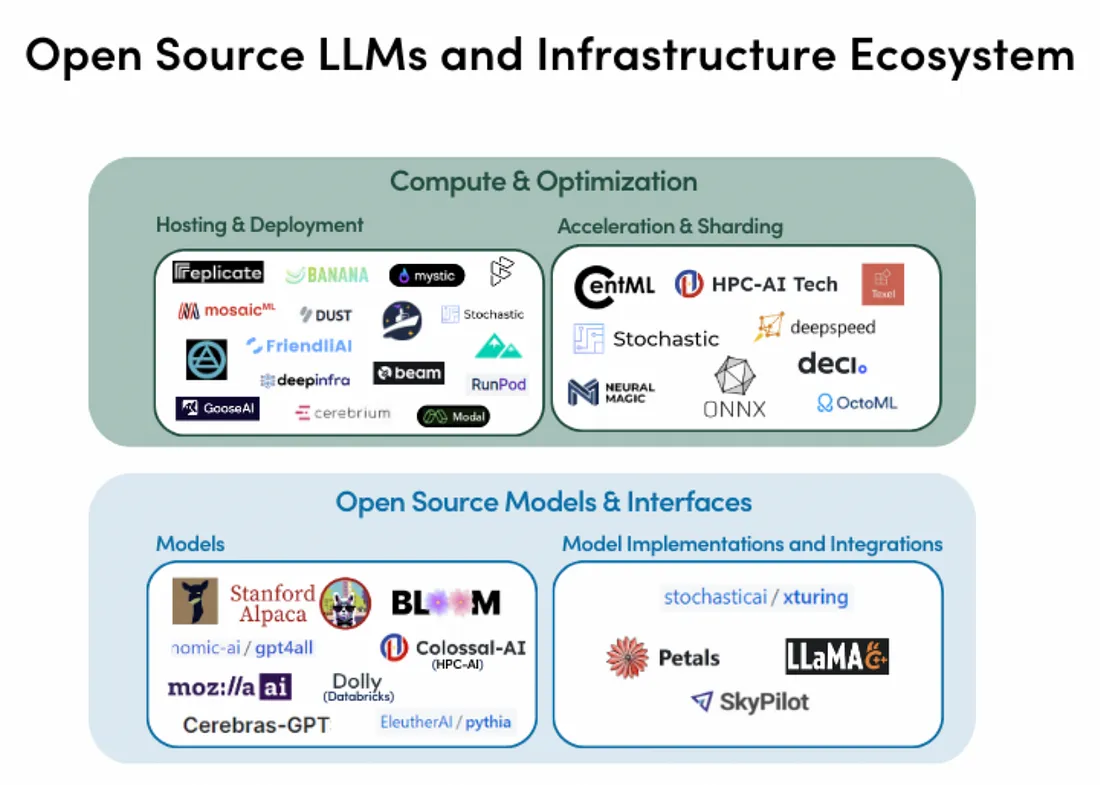
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量
当网络犯罪分子认为新的攻击媒介在经济上可行时,他们会瞄准新的攻击媒介,尤其是在没有强有力的安全措施的情况下。攻击面向未经授权的移动应用程序后端服务转移,例如用户配置文件信息和数据。网络犯罪分子通过扫描目标应用程序功能列表来获取访问权限,同时收集 API 密钥或业务逻辑来设计程序化攻击。以下是网络犯罪分子针对的五种移动端途径,另外基于这五种途径,我们提供了如何提高网络安全的建议

多年来,端到端加密 (E2EE) 一直是 WhatsApp、微信 和 QQ 等社交软件消息是传递不可或缺的一部分。在过去一年中,Zoom等视频会议 已将安全措施添加到其视频会议平台中,随后微软将其添加到 Teams 中——这突显了 E2EE 作为一种强大的安全选项,对于已将云计算作为标准商业模式的企业来说越来越受欢迎。

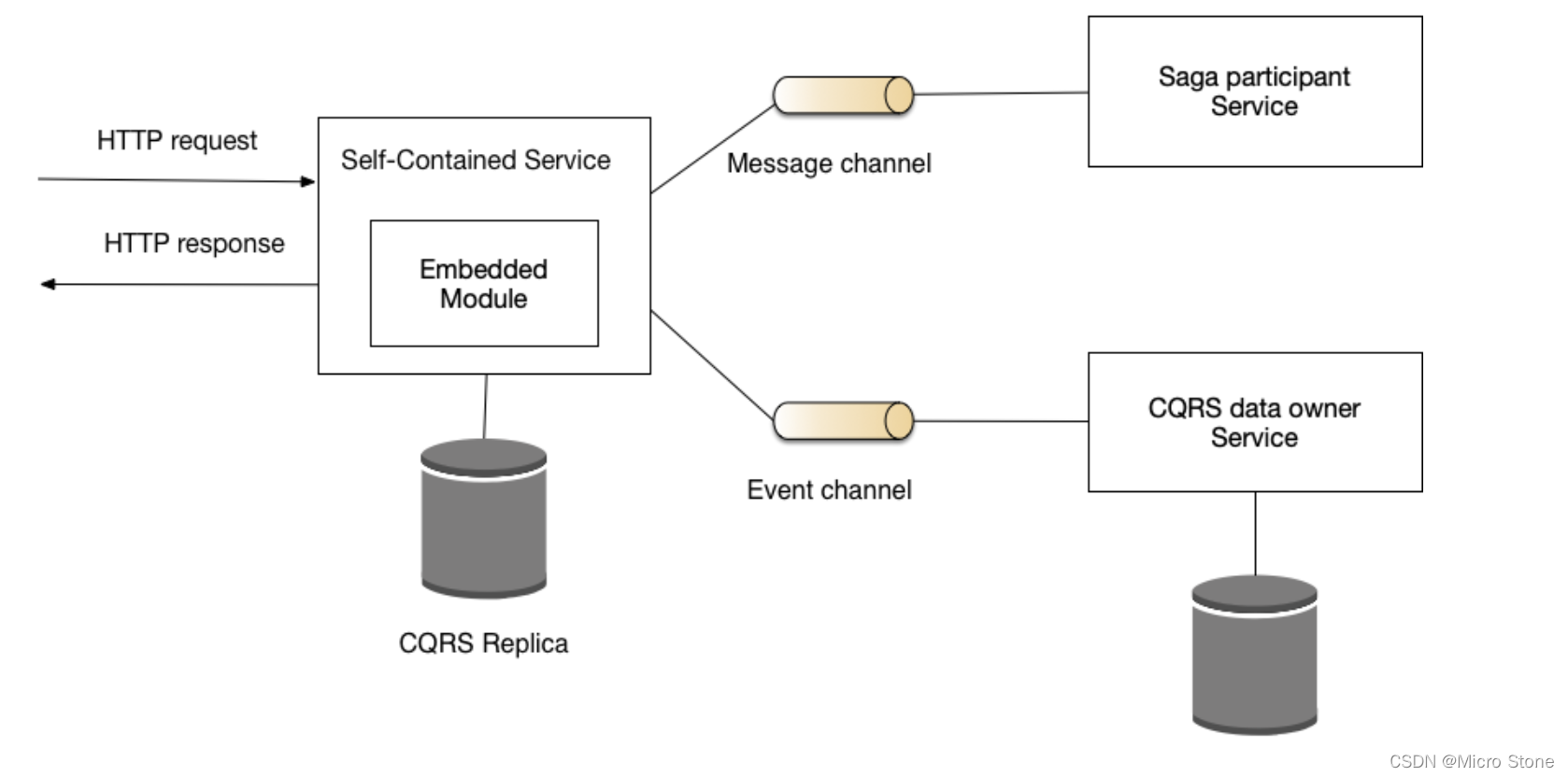
这种模式有以下好处:提高可用性和响应时间这种模式有以下缺点:使用 CQRS 的成本和复杂性增加增加使用 sagas 的复杂性使用 sagas 时不太直接的 API由于在服务中实现功能而不是作为单独的服务实现更大的服务
本文讨论了各种自然语言处理(NLP)技术的实际应用和实现方式,其中包括情感分析、命名实体识别(NER)、文本分类、机器翻译、文本摘要生成、信息提取、文本生成、语音识别以及文本到语音(TTS)等。这些技术广泛应用于电子商务、社交媒体、客户服务、国际商务、政府、金融、医疗和内容创作等行业。本文通过详细示例,介绍了如何使用Python的各种库,包括nltk、spacy、scikit-learn、Open
