- @steelbar
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Transformers初期是为NLP量身定做的一款开源,后来随着大数据的发展和大语言模型的构建,在原有基础上,增加了对大语言模型的支持
摘要 向量数据库是AI时代的新型数据管理系统,专为处理高维向量数据而设计。它通过嵌入技术将非结构化数据转化为向量表示,支持高效的相似性搜索和多模态数据融合。
摘要: RAG(检索增强生成)技术通过结合信息检索与文本生成,提升大模型回答专业问题的准确性和可靠性,尤其适用于私域数据场景。其核心流程包括语义搜索和生成输出,利用向量数据库(如Faiss、Chroma)检索相关文档,再交由大模型生成答案。
本文介绍了构建AI知识库的三种主要方式:提示词工程、微调和嵌入(Embedding),其中嵌入结合检索增强生成(RAG)是目前主流方法。
训练器为Transformers框架下的PyTorch预训练模型提供完整的训练和评估功能。其主要步骤包括计算损失、梯度更新权重、循环训练至指定epoch数。支持多GPU/TPU分布式训练和混合精度训练,通过TrainingArguments类实现高度定制化。
本文介绍了如何在不使用Trainer类的情况下实现BERT模型在MRPC数据集上的完整训练流程。主要内容包括:数据预处理(tokenize、移除冗余列、重命名标签列);数据加载器设置;模型初始化;优化器(AdamW)和学习率调度器配置;训练循环实现(包括GPU设备设置和进度条);评估循环实现(使用evaluate库计算准确率和F1分数)。最后简要提及了使用accelerate库进行分布式训练的可行
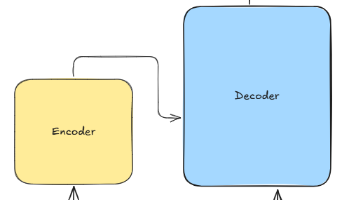
Transformers开源库已成为机器学习领域的重要工具。该库基于PyTorch、TensorFlow和JAX框架,提供Transformer模型的核心实现(如Self-Attention、Encoder/Decoder)和丰富的预训练模型(BERT、GPT等)。主要特点包括:简化模型推理的Pipeline接口、支持分布式训练的Trainer工具、高效文本生成功能。Transformers库覆盖
FastAPI基于Starlette和Pydantic,支持异步编程,自动生成API文档,开发效率高。安装需Python3.8+,通过uvicorn启动服务。示例演示了创建简单API的流程,访问根路径返回JSON响应。建议Python专注后端开发,通过RESTful API提供AI服务,前端使用Vue/React等框架。

以前的文章中介绍了如何安装了Python,到此,如果你对Python特别熟悉,可以不依赖于开发额外的开发IDE,直接使用包/环境管理工具和文本编辑器就可以开发Python工程项目。但是开发IDE在开发过程会提供更多便捷方式如管理工具集成、代码高亮、代码提示等,方便开发人员开发、管理、编译、发布项目。因此,一般的,我们会使用第三方开发环境来完成代码开发工作。目前,行业内使用的开发IDE层出不穷,在A