- @robinfang2019
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
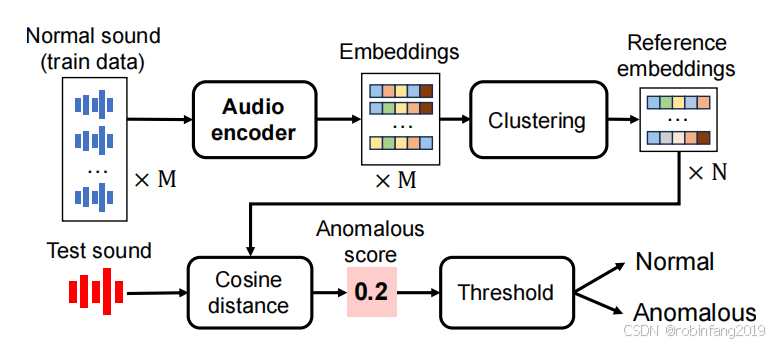
PPINtonus系统是专门为早期检测帕金森病(Parkinson’s Disease, PD)设计的,它利用深度学习音调分析和生物医学声音测量值(Biomedical Voice Measurements, BVMs)来评估声音样本。该系统与帕金森声音项目(Parkinson’s Voice Project, PVP)合作,并通过使用条件生成对抗网络(Conditional Generative

AE定义为检测由材料完整性的突然和永久性变化产生的瞬态弹性波引起的材料表面亚纳米级位移。使用AE的一个重大挑战是提取具有代表性的和鲁棒的特征,这对于状态监测至关重要。因此,本文旨在解决以下问题:哪些特征对于紧固程度分类最相关?这些特征如何通过几次测量活动泛化?
软件漏洞对日常软件系统的影响令人担忧。尽管已经提出了基于深度学习模型的漏洞检测方法,但这些模型的可靠性仍然是一个重大问题。先前的评估报告这些模型具有高达99%的召回率/F1分数,但研究发现,这些模型在实际应用场景下的表现并不佳,特别是在评估整个代码库而不仅仅是修复提交时,性能会显著下降。

小米Vela系统能够支持轻量化的端侧AI大模型,这意味着即使在资源受限的设备上也能运行复杂的AI模型。这主要得益于其对多种硬件规格的适配能力,包括最小系统仅需8KB内存,并且CPU主频不限,适配任意SoC多核架构。

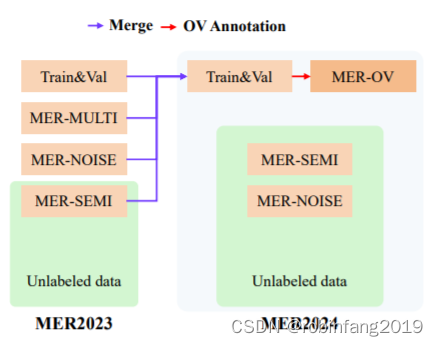
今年MER2024除了扩大数据集的大小,引入了一个新的开放式词汇情绪识别赛道MER-OV。这个赛道的主要考虑是现有数据集通常固定标签空间,并使用多数投票来增强注释者的一致性,但这个过程可能限制了模型描述微妙情绪的能力。在这个赛道中,我们鼓励参与者生成任意数量的标签,在任何类别中,目标是尽可能准确地描述情绪状态。
软件漏洞对日常软件系统的影响令人担忧。尽管已经提出了基于深度学习模型的漏洞检测方法,但这些模型的可靠性仍然是一个重大问题。先前的评估报告这些模型具有高达99%的召回率/F1分数,但研究发现,这些模型在实际应用场景下的表现并不佳,特别是在评估整个代码库而不仅仅是修复提交时,性能会显著下降。
2025 年中文大模型行业已从 "技术追逐" 进入 "生态竞争" 新阶段,海外模型仍在全局性能上保持领先,但国产模型通过开源生态建设、垂直领域突破、性价比优势,实现了从 "跟跑" 到 "并跑" 的关键跨越。未来,随着幻觉控制、复杂指令遵循等技术短板的补齐,以及智能体在更多产业场景的深度落地,中文大模型将迎来 "质效齐升" 的新发展周期。

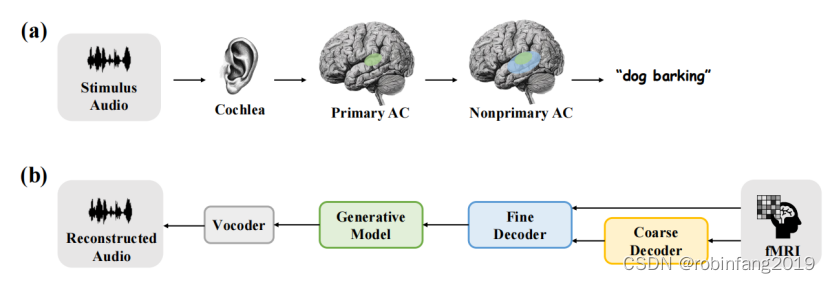
受到声学到语义流的启发,我们模拟了听觉处理路径的每个生理结构,并提出了一种相反的从粗到细的音频重建方法。我们使用非侵入性fMRI作为神经信号。首先,进行一个从粗到细的大脑解码过程。我们将fMRI数据解码到低维CLAP空间以获得粗粒度的语义特征,然后在这些语义特征的引导下,我们将fMRI数据解码到高维AudioMAE潜在空间以获得精细的声学特征。接下来,我们使用解码的精细神经特征作为条件,通过潜在扩
AE定义为检测由材料完整性的突然和永久性变化产生的瞬态弹性波引起的材料表面亚纳米级位移。使用AE的一个重大挑战是提取具有代表性的和鲁棒的特征,这对于状态监测至关重要。因此,本文旨在解决以下问题:哪些特征对于紧固程度分类最相关?这些特征如何通过几次测量活动泛化?
本文聚焦于机器状态监控领域的基于流的AL方法,因其相较于基于池的AL方法具有更优的响应速度。