




- @qq_62954485
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Yolo v8 通过deepseek指导,逐模块学习
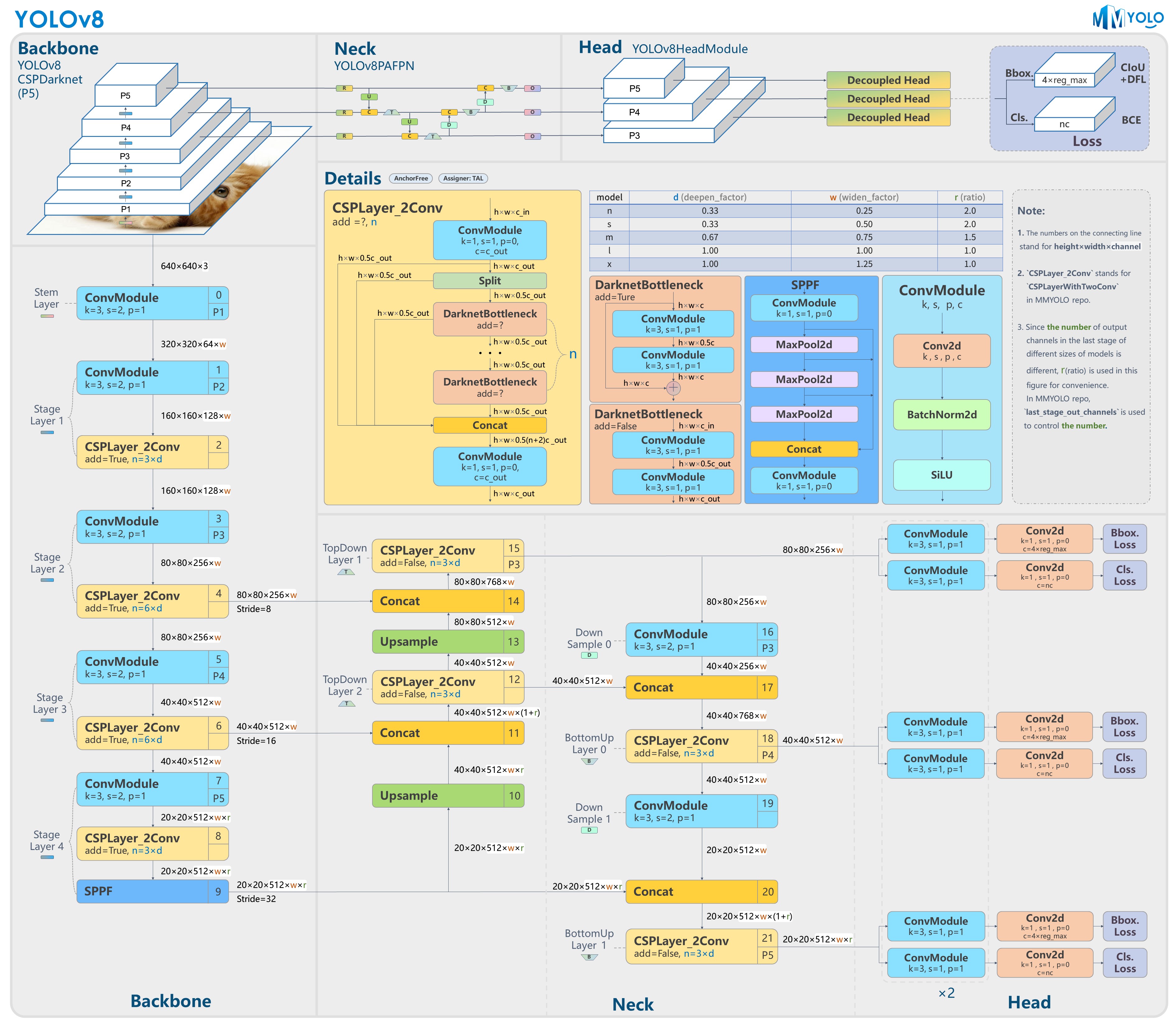
Yolo v8 通过deepseek指导,逐模块学习
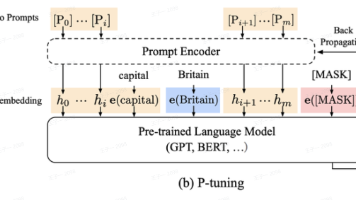
P-tuning系列方法通过将离散提示转化为连续可优化的向量,显著提升了提示工程的效率。P-tuning v1引入Prompt Encoder生成伪提示,实现参数高效微调;P-tuning v2进一步提出深度提示优化,在Transformer每一层添加可训练前缀,增强模型表达能力。
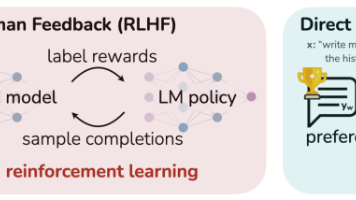
DPO(直接偏好优化)简化了传统RLHF流程,绕过显式奖励模型训练,直接利用偏好数据优化语言模型。其核心思想是将RLHF的奖励建模和强化学习合并为一个分类损失函数.
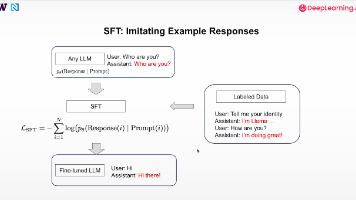
本文介绍了大语言模型(LLM)训练的两个关键阶段:预训练和后训练/微调,重点讲解了监督微调(SFT)方法。SFT通过"提示-回答"对数据训练模型,使其能够遵循指令执行特定任务。文章详细阐述了SFT的关键点,包括数据质量要求、与其他后训练方法的区别,并提供了基于Qwen3-0.6B-Base模型的实践代码示例,包含模型加载、推理生成和测试评估等完整流程。代码部分展示了如何构建对话
Yolo v8 通过deepseek指导,逐模块学习
本文介绍了大语言模型(LLM)训练的两个关键阶段:预训练和后训练/微调,重点讲解了监督微调(SFT)方法。SFT通过"提示-回答"对数据训练模型,使其能够遵循指令执行特定任务。文章详细阐述了SFT的关键点,包括数据质量要求、与其他后训练方法的区别,并提供了基于Qwen3-0.6B-Base模型的实践代码示例,包含模型加载、推理生成和测试评估等完整流程。代码部分展示了如何构建对话
P-tuning系列方法通过将离散提示转化为连续可优化的向量,显著提升了提示工程的效率。P-tuning v1引入Prompt Encoder生成伪提示,实现参数高效微调;P-tuning v2进一步提出深度提示优化,在Transformer每一层添加可训练前缀,增强模型表达能力。
笔记目录:统计学习方法(李航) 第一章 绪论统计学习方法(李航)第二章 感知机统计学习方法(李航)第三章 k近邻统计学习方法(李航) 第四章 贝叶斯统计学习方法(李航) 第五章 决策树决策树是一种树形结构的分类或回归模型,通过一系列 if-then 规则对数据进行决策示例:对于数据集 {(x1,y1),(x2,y2),…,(xn,yn)}\{ (x_1, y_1), (x_2, y_2), \do
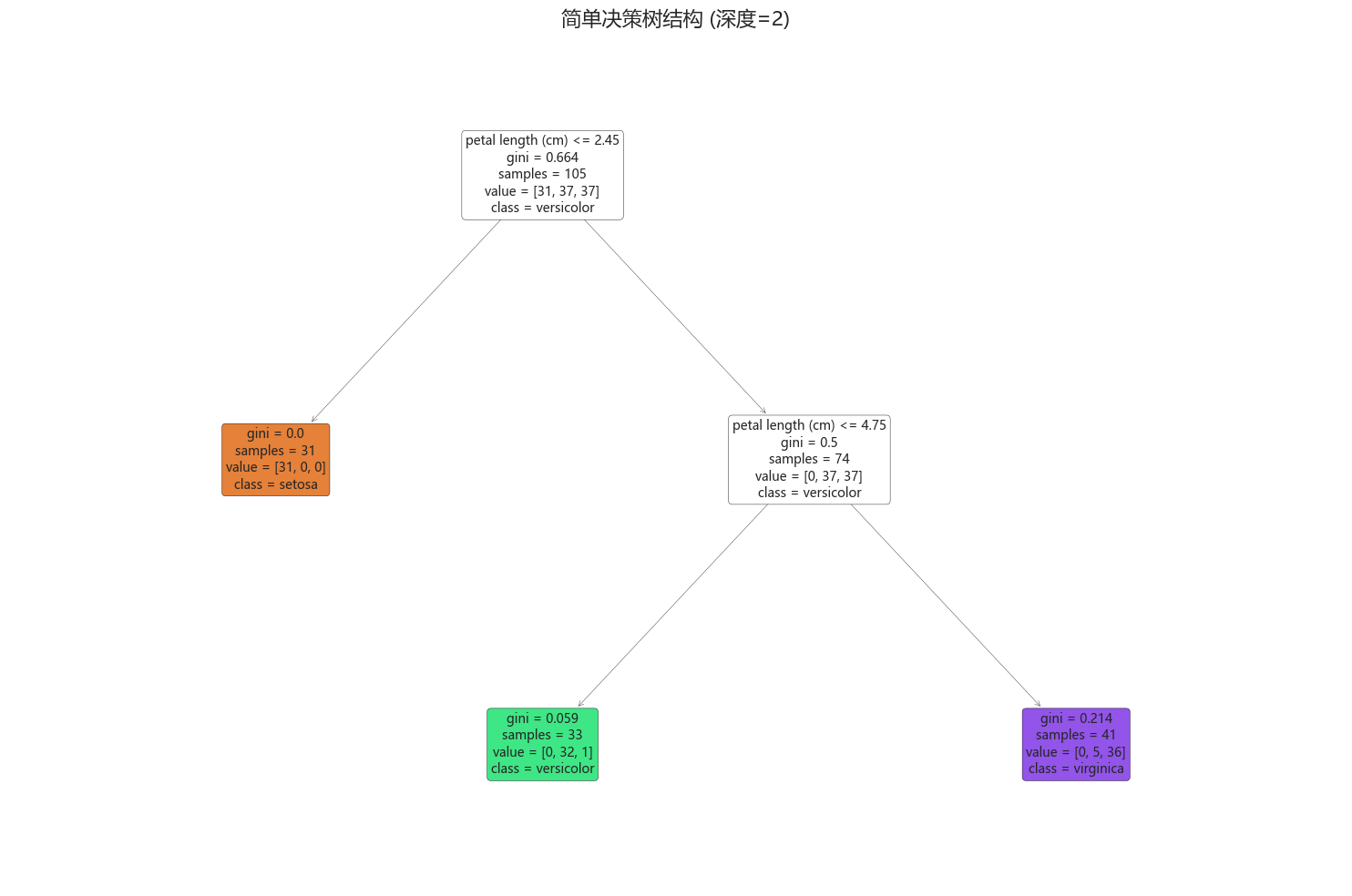
笔记目录:统计学习方法(李航) 第一章 绪论统计学习方法(李航)第二章 感知机统计学习方法(李航)第三章 k近邻贝叶斯定理:已知: 存在 KKK 类 c1,c2,...,cKc_1,c_2,...,c_Kc1,c2,...,cK, 给定一个新的实例x=(x(1),x(2),...,x(n))x=(x^{(1)},x^{(2)},...,x^{(n)})x=(x(1),x(2),...,x(n
