




- @qq_62827972
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。在下面的几个章节中,我们将介绍一些常用于设计深层神经网络的启发式概念。与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。使用块的想法首先出现在牛津大学的视觉几何组(v

在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。与卷积层一样,汇聚层也可以改变输出形状。下面,我们用深度学习框架中内置的二维最大汇聚层,来演示汇聚层中填充和步幅的使用。这意味着汇聚层的输出通道数与输入通道数相同。与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据

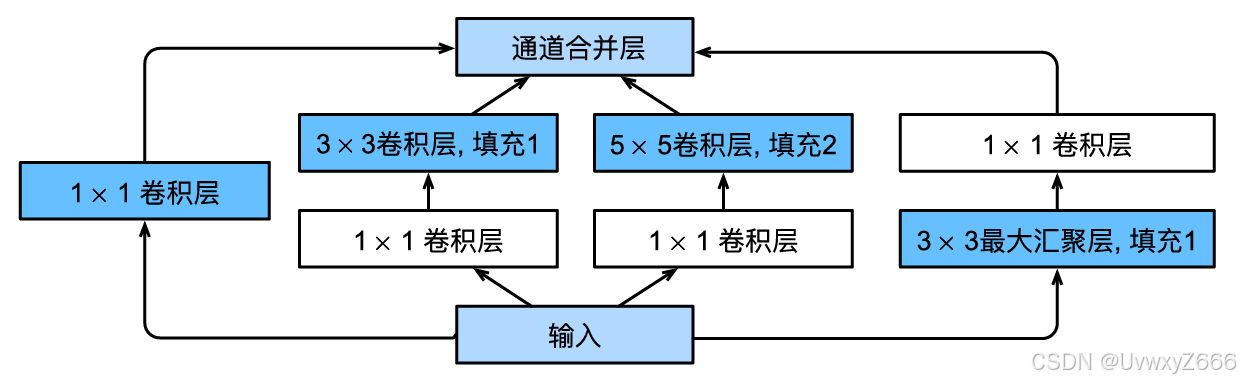
在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet的网络架构大放异彩。
注意,尽管索引 'b' 存在,但在数据集中并没有索引为 ('b', 2) 的元素,因此在输出结果中没有显示。这里的操作是选择所有第一级索引(即大写字母 'a', 'b', 'c', 'd')下,第二级索引为 2 的所有数据。:这个操作是使用索引的切片功能,选择了从'b'到'c'(包含'b'和'c')的所有元素。输出结果展示了索引在'b'和'c'之间的所有Series元素。人们经常想要将DataFr

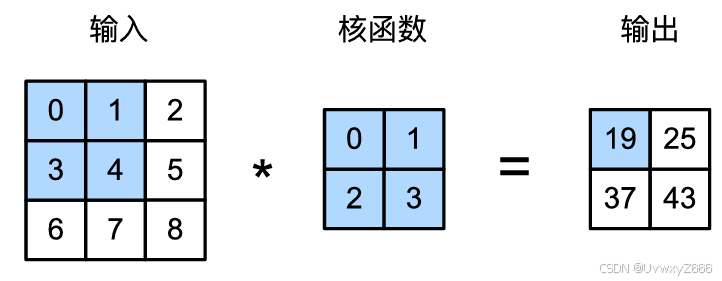
彩色图像具有标准的RGB通道来代表红、绿和蓝,需要三个通道表示,故而只有单输入单输出是不够的。对于单个输入和单个输出通道的简化例子,可以将输入、卷积核和输出看作二维张量。当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有3×ℎ×𝑤的形状。我们将这个大小为3的轴称为通道。我们可以构造与上图中的值相对应的输入张量X和核张量K,以验证互相关运算的输出。

原文地址:Meanshift 和 Camshift这篇文章是小白的笔记,仅做记录,不适合学习,误入。

训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手。本节将介绍批量规范化(batch normalization),这是一种流行且有效的技术,可持续加速深层网络的收敛速度。

在上我们,我们给出了卷积核,一个很容易想到的问题是给定XY能否学习出卷积核,答案是肯定的。在10次迭代之后,误差已经降到足够低。现在我们来看看我们[可以发现,1表示由1到0的边缘,0表示有0到1 的边缘。中间四列为黑色(0),其余像素为白色(1)。可以看到,与之间我们设置的结果很接近。实在是行云流水般丝滑)
Classify Leaves | Kaggle上面是数据集将标签转成类别自定义数据集准备工作画图、计算loss、累加器函数等,再之前文章中已经介绍过的,不必一句一句弄明白模型构建或载入如果是第一次训练则可以下载再ImageNet上预训练好的resnet18或者更大的模型,如果之前已经训练有保存好的模型则可以接着训练模型训练控制一批的训练多个epochtransfroms和dataloader训练

李沐老师的《动手学深度学习》中很喜欢将一些要重复使用的函数放在一个叫d2l的包内,在一个记事本内定义了就存好,等下一个记事本内要用了直接调用。无奈本人有段时间内一直弄好导致函数存不了,只能每一次使用都去前面的记事本找要什么函数,这种复杂的依赖关系让我头疼不已。于是便有了这边博客,用来记录d2l包内存着的函数,这样下次就可以直接到这里来找了,很方便。这些函数和深度学习密切相关,有很多通用的函数,可以