




- @qq_55736201
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
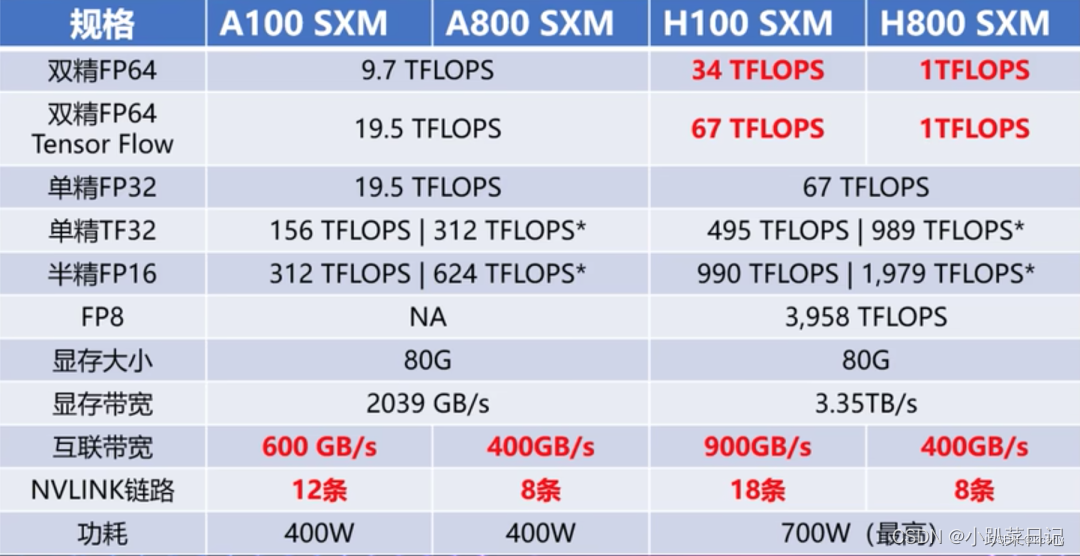
TFLOPS:指的是每秒钟可以执行的浮点运算次数,它代表着计算机在处理科学计算、机器学习等任务时的处理能力。TFLOPS的单位是万亿次每秒(trillion floating point operations per second)。一般是指单精度性能FP32。TOPS:指的是每秒钟可以执行的整数运算次数,它代表着计算机在处理图像、音频等任务时的处理能力。TOPS的单位是万亿次每秒(trillio
问题:向量化允许您在L层神经网络中计算前向传播时,不需要在层l = 1, 2, …, L间显式的使用for循环(或任何其他显式迭代循环),正确吗?ps:在层间计算中,我们不能避免for循环迭代。向量化可以去掉外层循环(即遍历样本)

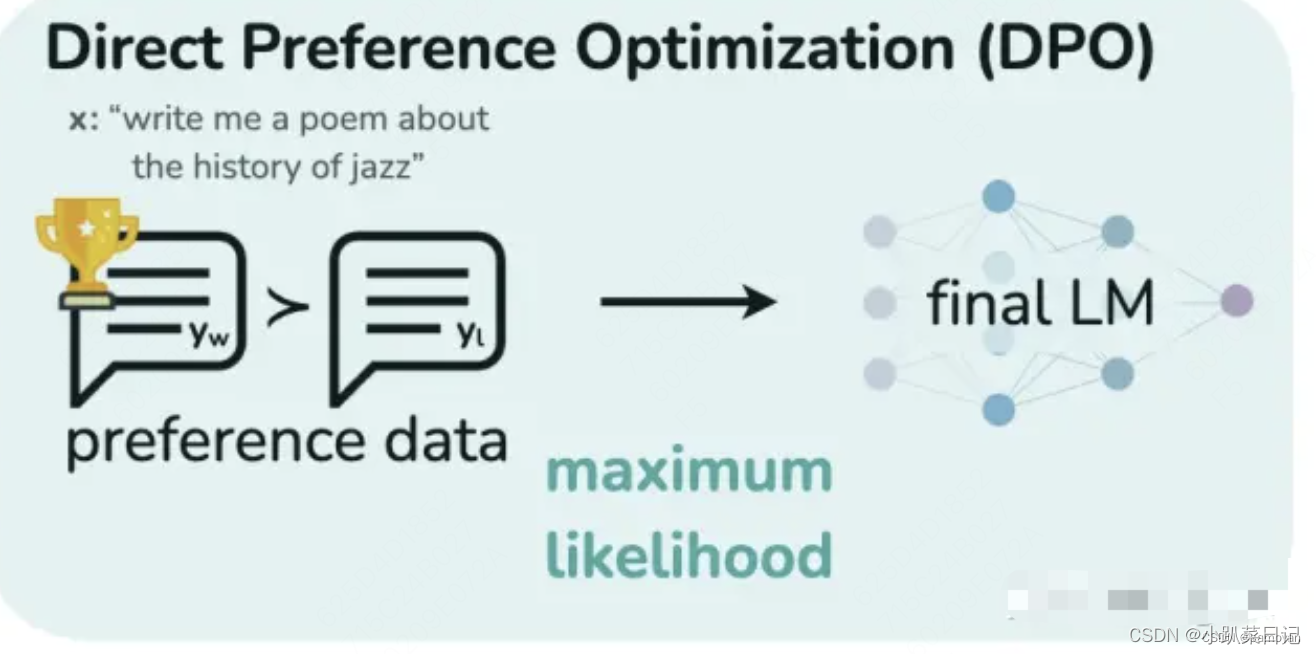
DPO(直接偏好优化)简化了RLHF流程。它的工作原理是创建人类偏好对的数据集,每个偏好对都包含一个提示和两种可能的完成方式——一种是首选,一种是不受欢迎。然后对LLM进行微调,以最大限度地提高生成首选完成的可能性,并最大限度地减少生成不受欢迎的完成的可能性。与传统的微调方法相比,DPO 绕过了建模奖励函数这一步,设计一种包含正负样本对比的损失函数,通过直接在偏好数据上优化模型来提高性能。(即不训
1. Freeze 方法,即参数冻结,对原始模型部分参数进行冻结操作;2. P-Tuning 方法,参考 ChatGLM 官方代码 ,是针对于大模型的 soft-prompt 方法;3. LoRA 方法,的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练;4. AdaLoRA 方法是对 LoRA 的一种改进,并根据重要性评分动态分配参数预算给权重矩阵;


【代码】报错ImportError: cannot import name ‘StaticCache‘ from ‘transformers.cache_utils。
机器学习中一个常见的预处理步骤是将数据集居中并标准化,这意味着你从每个例子中减去整个numpy数组的平均值,然后用整个numpy阵列的标准差除以每个例子。但对于图片数据集,只需将数据集的每一行除以255(像素通道的最大值),就更简单、更方便,效果也几乎一样好。.reshape(())函数,注意中间还有个括号()!

GPT-2 模型由多层单向transformer的解码器部分构成,本质上是自回归模型,1.模型架构上变得更大,参数量达到了1.5B,数据集改为百万级别的WebText,,Bert当时最大的参数数量为0.34B,但是作者发现模型架构与数据集都扩大的情况下,2.gpt2 pre-training方法与gpt1一致,但在做下游任务时,不再进行微调,零次学习),成品模型对于训练集中没有出现过的类别,能自动

一开始安装deepspeed不可以使用pip直接进行安装。这时我们需要利用进入到deepspeed的安装目录下激活你的环境安装deepspeed。
