




- @qq_54185421
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先收集非常多的人物肖像数据集,然后搭建两个神经网络,即引入了一个base网络,它可以在较低的分辨率下预测alpha matte和前景层,以及一个预测误差图,它指定了可能需要高分辨率精细化的区域。然后,使用一个refinement网络将低分辨率的结果和原始图像结合在一起,只在选定区域生成高分辨率的输出。最后达到了惊人的效果

首先收集非常多的人物肖像数据集,然后搭建两个神经网络,即引入了一个base网络,它可以在较低的分辨率下预测alpha matte和前景层,以及一个预测误差图,它指定了可能需要高分辨率精细化的区域。然后,使用一个refinement网络将低分辨率的结果和原始图像结合在一起,只在选定区域生成高分辨率的输出。最后达到了惊人的效果
Demo success 需要5步(1)opencv官网下载直达: https://sourceforge.net/projects/opencvlibrary/files/此处建议下载opencv-3.4.16-vc14_vc15.exe(因4.5版本可能会报错,如下图所示)(2)安装opencv,本人安装路径:G:\c++_machine_learning\(3)配置电脑系统环境:G:\c++
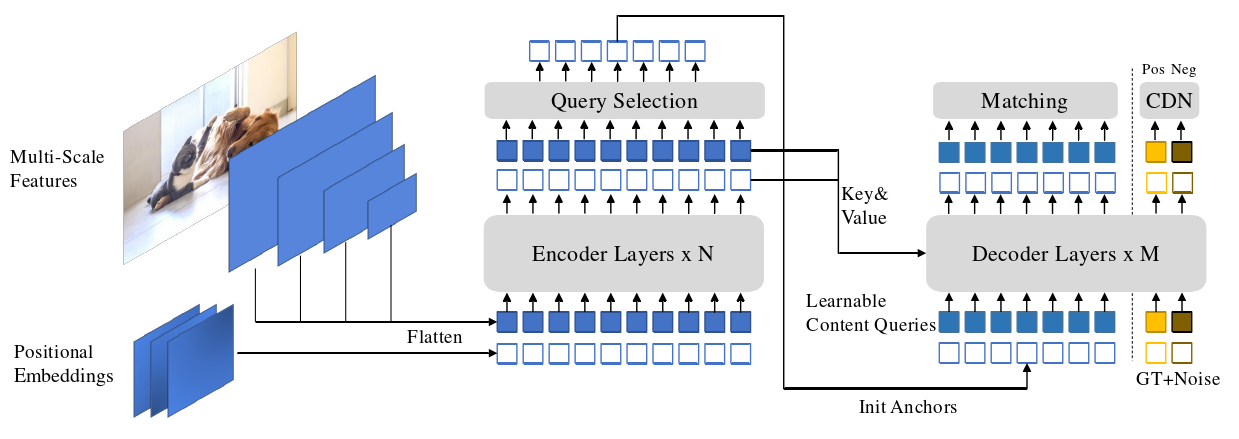
截止2022年7月25日,DINO是目标检测的SOTA。本人根据源码的复现感受和DINO论文的精读心得,撰写本篇博客,希望对你有所帮助。DINO(DETR with Improved deNoising anchOr boxes),一款最先进的端到端对象检测器。对比的去噪训练方式;用于锚点初始化的混合查询选择方法;用于框预测的向前两次方案;本文章会对以上三种创新方法逐点击破。使用ResNet-50
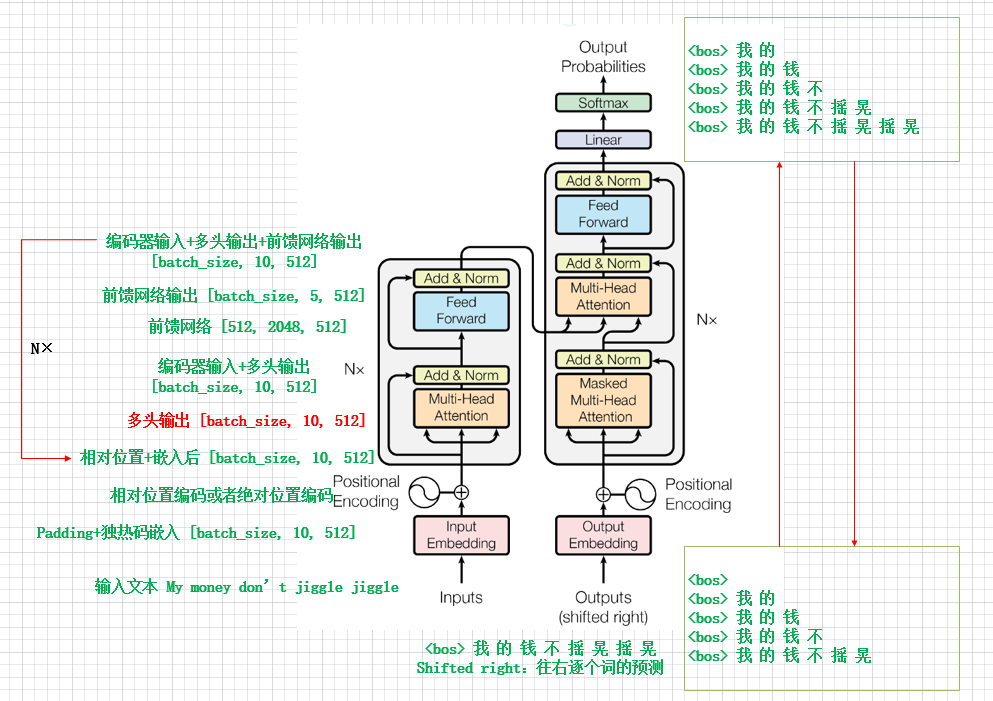
建议:结合《Attention Is All You Need》论文观看此文章。Transformer的模型结构如下图所示,通过把“My money don't jiggle jiggle”翻译成“我的钱不摇晃摇晃”来分析Transformer的工作过程。训练过程中,每一次解码器的输出与数据集中的翻译值通过交叉熵计算错误率(一次送入batch_size大小个token,计算错误率),从而对权重进行
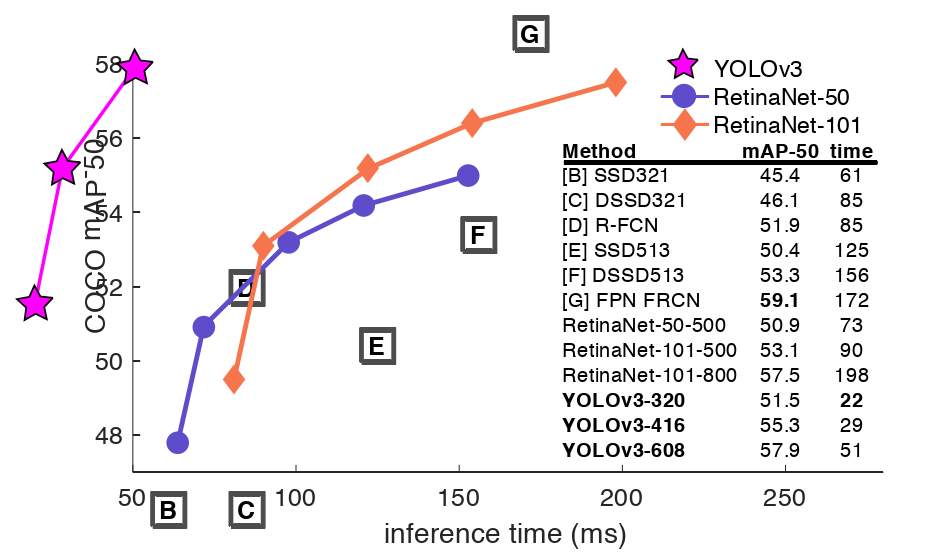
我们对YOLO做了一些更新!我们做了一堆小的设计变更,使其变得更好。我们还训练了这个非常庞大的新网络。它比上次大一点,但更准确。不过还是很快的,不用担心。在320 × 320时,YOLOv3在22 ms内以28.2 mAP运行,与SSD一样精确,但速度快3倍。当我们查看旧的0.5 IOU的mAP检测度量YOLOv3是相当不错的。在Titan X上,它在51ms内达到 57.9,而RetinaNet
首先看摘要和结论,然后分析核心思想,最后总结表格内容和实验细节。训练深度神经网络是一个复杂的事实,在训练过程中每一层的输入分布随着前一层的参数变化而变化。这就需要较低的学习速率和仔细的参数初始化来减缓训练速度,并且使得具有饱和非线性的模型的训练变得非常困难。我们将这一现象称为内部协变量偏移(internal covariateshift),并通过归一化层输入来解决这个问题。我们的方法从将规范化作为

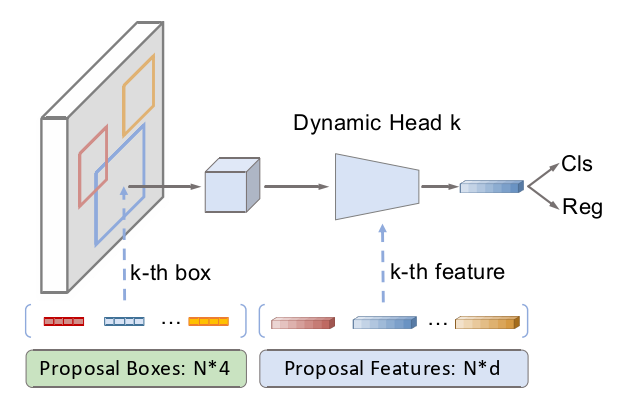
文章的创新点:首次提出动态实例交互头:在迭代结构中,结合线性投影、矩阵乘法、归一化和ReLU激活函数对输入的提议框和提议特征进行一系列操作,最终得到叠加的学习特征。剔除NMS,选用DETR中的匈牙利匹配优化Sparse:提议特征默认选用100个,比以往的传统CNN的手工预选框少了几十倍主要结合Fast R-CNN、DETR和Deformer DETR构造的框架...
图像序列中运动区域的实时分割是许多视觉系统的基本步骤,包括自动视觉监视、人机界面和低频电信号。一种典型的方法是背景减法(background subtraction)。问题:许多背景模型被引入来处理不同的问题。这些问题的成功解决方案之一是使用Grimson等人[1,2,3]提出的每像素多色背景模型。然而,该方法在开始时学习缓慢,尤其是在繁忙的环境中。此外,它无法区分移动阴影和移动对象。本文提出了一

Fall Detection for Shipboard Seafarers Based on Optimized BlazePose and LSTM本博客通过全文翻译和总结的方式对论文进行精读。读完此论文颇受启发,比如:视频中的时间序列问题,文章简单明了的整体脉络,数据集的制作方式和表格描述法,实验证明模型的广泛性,整篇文章一直在强调现如今存在的问题和相应的解决方案。本研究提出的BlazePo
