




- @qq_53256193
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
admin.register(LoginUser)#注册方式2#自定义列表页#注册方式1展示多对多则不是如此应当然后在admin.py将这个改为中文user_name=models.CharField('用户名',max_length=20)desc=models.CharField('描述',max_length=20)age=models.CharField('年龄',max_length=2

return HttpResponse("这是一道白切鸡!!!!!!!!")index.html<head></head><body><h1 style="background-color:greenyellow">这是一道白切鸡!!!!

1.是一个高效的网页解析库,可以从HTML或XML文件中提取数据2.支持不同的解析器,比如,对HTML解析,对XML解析,对HTML5解析3.就是一个非常强大的工具,爬虫利器4.一个灵感又方便的网页解析库,处理高效,支持多种解析器5.利用它就不用编写正则表达式也能方便的实现网页信息的抓取。

wb = workbook.Workbook()# 创建Excel对象。ws.append(['职称', '链接', '时间', '公司名称'])print("第{}页已经保存完毕!my_list = [z,l,s,g]# 以列表形式写入。4.保存数据:txt文本形式和excel文件两种形式。——异步(查看xhr)wb.save('腾讯社招.xlsx')4.删除不必要的,找到正确的(可删可不删)5
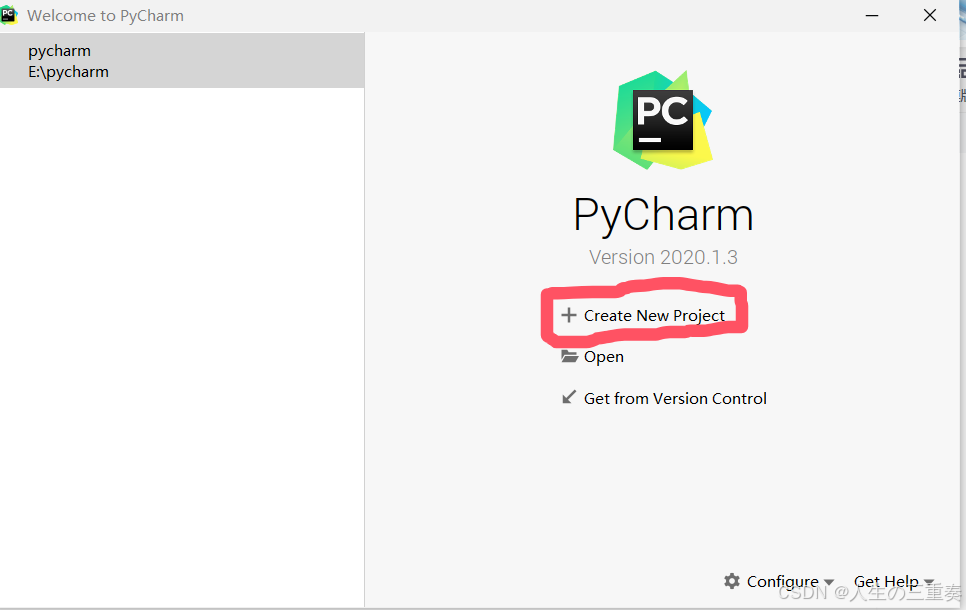
4.第三步选择我们安装的解释器位置,如果不清楚,就win+r输入cmd进入终端,然后输入“where python”5.将上述位置可以选择复制后者根据位置目录去寻找,然后依次点击ok确认即可。1.安装完pycharm后,打开出现下面这个界面,选择新建项目。7.检验是否成功,创建一个.py文件即可。6.显示以下内容则表示配置成功7。2.进入如下界面,选择第二个。
【代码】pandas——数据结构。

return HttpResponse("这是一道白切鸡!!!!!!!!")index.html<head></head><body><h1 style="background-color:greenyellow">这是一道白切鸡!!!!
定义一个管道类重写管道类的process_item方法process_item方法处理完item之后必须返回给引擎# 爬虫文件中提取数据的方法每yield一次item,就会运行一次# 该方法为固定名称函数# 参数item默认是一个 <class 'mySpider.items.MyspiderItem'>类信息,需要处理成字典# 将返回的字典数据转为JSON数据# 写入JSON数据# 参数item
从以上结果可以看出,此链接不可直接点击,缺少https://www.hifini.com/这一部分。1.发请求,获得网页源码 #1.和2是在一步的 发请求成功了之后就能直接获得网页源码。print("歌曲播放资源链接",song_link)第三步:再次像歌曲播放资源链接发请求 获得二进制数据,进行保存。print('歌名:',song_name)os.makedirs("歌曲")2.创建文件流,将
