




- @qq_51118755
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
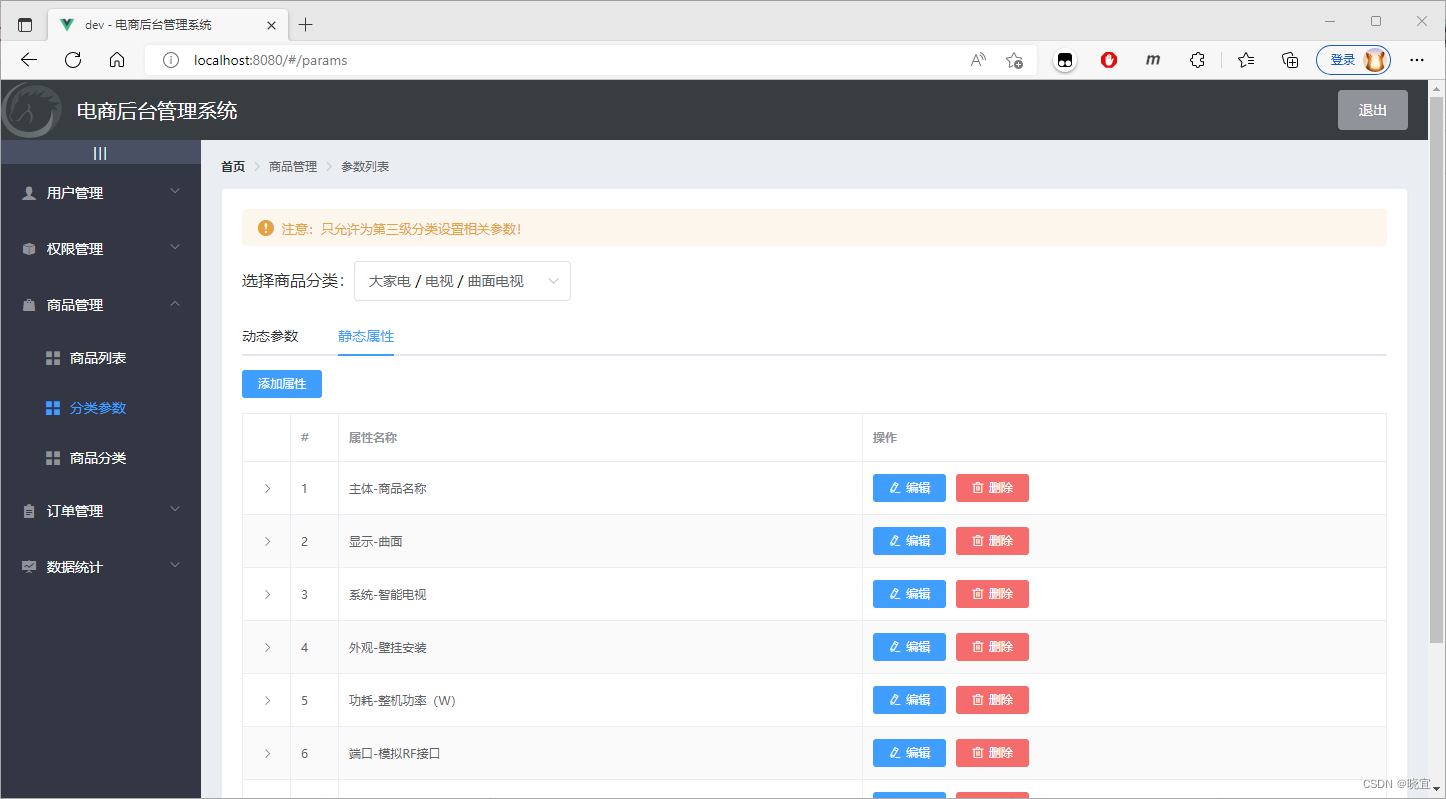
该项目为电商后台的管理系统。设计了登录页面。管理人员需要通过输入正确的用户名和密码才能登录。登陆成功之后进入管理页面:管理页面由五个子模块组成:用户管理,权限管理,商品管理,订单管理,数据统计;每个子模块有若干子模块组成,用户管理下->用户列表,权限管理->角色列表,权限管理,商品管理->商品列表,分类参数,商品分配,订单管理->订单列表,数据统计->数据报表。
ERC1967标准实现智能合约可升级性 摘要: ERC1967是以太坊代理合约标准(EIP-1967),通过定义固定存储槽解决智能合约升级时的存储冲突问题。标准规定三个关键存储槽:实现合约地址(IMPLEMENTATION_SLOT)、管理员地址(_ADMIN_SLOT)和Beacon地址(_BEACON_SLOT)。实践采用UUPS升级模式,通过代理合约指向逻辑合约,当需要升级时部署新逻辑合约并

今天在push代码到github的时候遇到了错误:fatal: unable to access 'https://github.com/ShangyiAlone/FacemaskDetection.git/': Failure when receiving data from the peer网上搜了下教程,是开启梯子的时候代理服务器的问题,开启梯子的时候电脑设置中也开启了代理服务器,如果git

合肥工业大学计算机网络课堂测试总结,期末复习资料

SBTI的爆火再次证明:一个有趣的想法,用极简的技术快速实现,就能获得不错的传播效果。技术本身没有高低之分,关键在于能否快速把想法落地。看到好玩的项目,不妨拆一拆、复刻一下,再加上自己的理解和改进——这或许就是程序员的乐趣之一。你测SBTI了吗?结果是什么?欢迎在评论区分享你的测试结果,或者说说你最近有做过什么有趣的小项目。

现在 offer 的情况是怎么样的?现在已经进入实习的尾声了,看你 offer 不是很多,是因为开始的比较晚吗?主要负责集团中间件的开发,比如数据库的中间件等等,能学习到中间件的相关知识。当你接受一个新的任务时,你会先做什么再做什么,你处理工作的思路是什么(逻辑顺序)string的split要正则表达式,我不会还是面试官教我的。携程英语测评的作文部分在之前的文章里,感兴趣的同学可以去看看。看你简历

读取二级文件目录下的xlsx表格并将需要的信息存储在一张表格里。记录一下代码,方便以后复用。

搜索是人工智能中的一个基本问题,并与推理密切相关。搜索策略的优劣,将直接影响到智能系统的性能与推理效率。什么是搜索根据问题的实际情况不断寻找可利用的知识,构造出一条代价较少的推理路线,使问题得到圆满解决的过程称为搜索包括两个方面:找到从初始事实到问题最终答案的一条推理路径找到的这条路径在时间和空间上复杂度最小搜索的分类按是否使用启发信息(1)盲目搜索(Uninformed search)盲目搜索按
目录总线的基本概念:总线的分类:片内总线:系统总线:通信总线:常见的控制信号:总线的性能指标:名词解释:总线判优总线控制:总线周期:总线通信方式:同步通信:异步通信:异步通信:半同步通信:分离式通信总线的基本概念:总线是连接多个部件的信息传输线,是各部件共享的传输介质总线的分类:片内总线:片内总线是指芯片内部的总线系统总线:系统总线是指CPU,主存,I/O设备(通过I/O接口)各大部件之间的信息传

原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
