




- @qq_46981910
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
传统模型:只有图像输入,使用Transformer架构和自监督学习方法。文本提示模型/视觉语言模型(VLMs):接受图像和文本输入,如OpenAI的CLIP和Flamingo模型。视觉提示模型:需要图像和视觉提示(如边界框或点)或文本提示,例如Segment Anything Model(SAM)。异构模型:可以接受多种类型输入并生成多种类型输出的模型。

传统模型:只有图像输入,使用Transformer架构和自监督学习方法。文本提示模型/视觉语言模型(VLMs):接受图像和文本输入,如OpenAI的CLIP和Flamingo模型。视觉提示模型:需要图像和视觉提示(如边界框或点)或文本提示,例如Segment Anything Model(SAM)。异构模型:可以接受多种类型输入并生成多种类型输出的模型。
传统模型:只有图像输入,使用Transformer架构和自监督学习方法。文本提示模型/视觉语言模型(VLMs):接受图像和文本输入,如OpenAI的CLIP和Flamingo模型。视觉提示模型:需要图像和视觉提示(如边界框或点)或文本提示,例如Segment Anything Model(SAM)。异构模型:可以接受多种类型输入并生成多种类型输出的模型。
论文提出了一种新的基于图的稀疏注意力机制,称为Sparse Vision Graph Attention (SVGA),专为在移动设备上运行的视觉图神经网络(ViGs)设计。此外,作者提出了首个用于移动设备上视觉任务的混合CNN-GNN架构,称为MobileViG,它使用了SVGA。

RNN循环神经网络(Recurrent Neural Networks,RNNs)是一类特别适用于处理序列数据的神经网络。与传统的前馈神经网络不同,RNNs具有循环连接,可以在序列的每个时间步之间传递信息,使其能够捕捉数据中的时间依赖性和动态行为。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但这对于需要用到前一个时间节点结果的问题是没有办法
论文针对的问题是类无关对象计数(class-agnostic object counting),即在没有特定类别对象的先验知识的情况下,对图像中任意类别的对象进行计数。现有的方法通常需要人类标注的示例,这在实际应用中往往不可行,尤其是在自动化系统中。提出了零样本对象计数(ZSC)的新设置,测试时只需要类别名称,不需要人类标注的示例。提出了一种两步方法:首先基于给定的类别名称构建类别原型,选择可能包

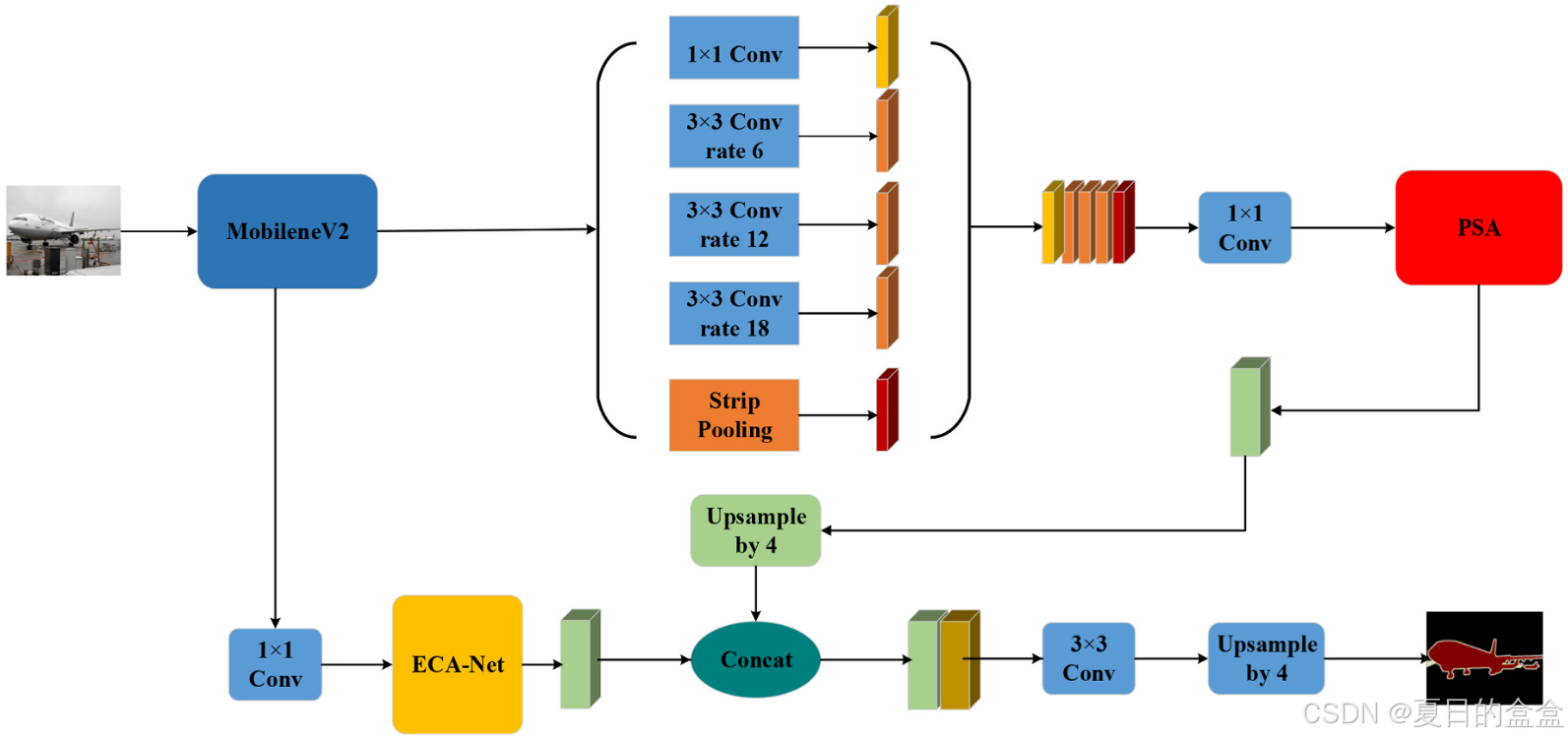
在提取图像特征信息时,Deeplabv3难以充分利用多尺度信息。这可能会导致细节信息的丢失,并损害分割精度。提出一种改进的基于DeepLabv3网络的图像语义分割方法,以轻量级的MobileNetv2作为模型的骨干。将ECAnet通道注意力机制应用于低层特征,降低计算复杂度,提高目标边界清晰度。在ASPP模块之后引入极化自注意力机制,以提高特征图的空间特征表示。在VOC2012数据集上进行验证,实
这篇论文介绍了一种名为Zero-TPrune的方法,旨在解决预训练Transformer模型在边缘设备部署时面临的挑战。这些挑战主要是由于模型大小和推理成本的指数级增长,特别是输入序列中的令牌数量导致的计算复杂度呈二次方增加。Zero-TPrune是一种零样本(zero-shot)令牌修剪方法,它利用预训练Transformer模型的注意力图来对令牌进行重要性排名,并移除信息量较少的令牌。这种方法

DINO 是一种先进的端到端目标检测器,通过使用对比性去噪训练、混合查询选择方法和双重前瞻方案来改进性能和效率。在 COCO 数据集上,使用 ResNet-50 作为主干网络和多尺度特征,DINO 在 12 轮训练中达到了 49.4AP,在 24 轮训练中达到了 51.3AP,与之前的最好模型 DN-DETR 相比分别提高了 6.0AP 和 2.7AP。DINO 在模型大小和数据大小方面都具有很好

这篇论文提出了一种名为Image Processing Graph Neural Networks (IPG) 的模型,旨在通过利用图的灵活性来突破超分辨率(Super-Resolution, SR)中的固有刚性问题。在现有的SR模型中,无论是基于卷积神经网络(CNNs)还是窗口注意力方法,每个像素都以固定的方式聚合相同数量的邻域像素,这限制了它们在SR任务中的有效性。IPG模型通过图的灵活性解决
