




- @qq_45368632
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
图像本身的变化将有助于模型对未见数据的泛化,从而不会对数据进行过拟合。以上整理的都是我们常见的数据增强技术,torchvision中还包含了很多方法,可以在他的文档中找到:https://pytorch.org/vision/stable/transforms.html。
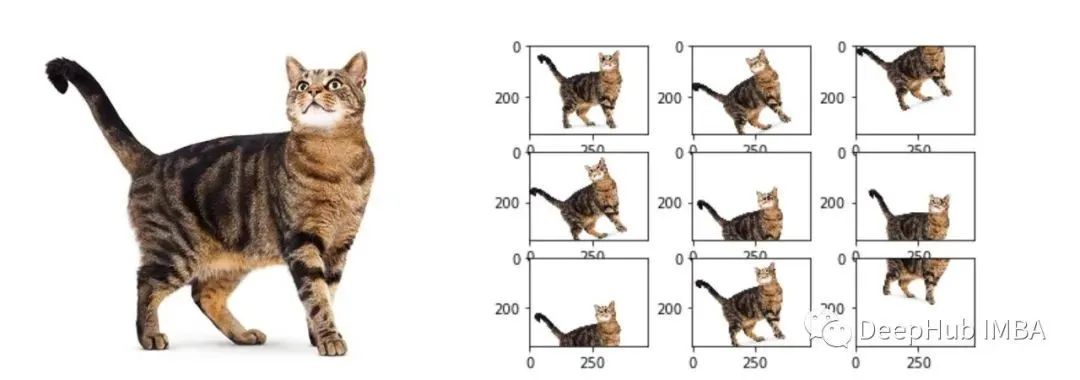
本文汇总了医学图像、卫星图像、语义分割、自动驾驶、图像分类、人脸、农业、打架识别等多个方向的数据集资源,均附有下载链接。

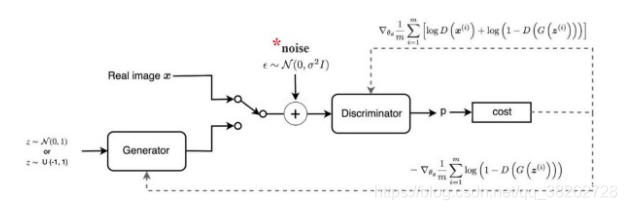
文章目录1 什么是GAN?2 GAN存在的问题3 训练的经验3.1 不要纠结于损失函数的选择3.2 关于增加模型的容量3.3 尝试改变标签3.4 尝试使用 batch normalization3.5 尝试分次训练3.6 最好不要提早结束3.7 关于k的选择3.8 关于学习率3.9 增加噪声3.10 不要使用性能太好的判别器3.10 可以尝试最新的multi-scale gradient方法3.1
记得刚开始研究深度学习时,做过两个小例子。一个是用tensorflow构建了一个十分简单的只有一个输入层和一个softmax输出层的Mnist手写识别网络,第一次我对权重矩阵W和偏置b采用的是正态分布初始化,一共迭代了20个epoch,当迭代完第一个epoch时,预测的准确度只有10%左右(和随机猜一样,Mnist是一个十分类问题),当迭代完二十个epoch,精度也仅仅达到了60%的样子。然后我仅

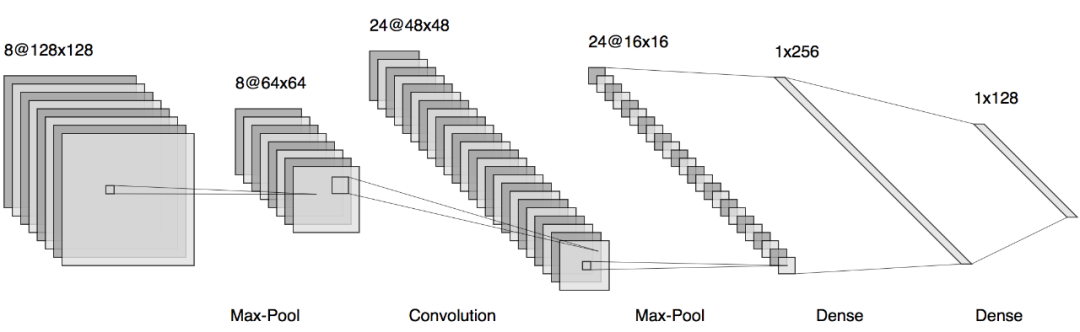
使用Keras.js,可以轻松地生成神经网络模型的摘要。摘要提供了模型的层级结构、层级名称、输出形状和可训练参数数量等信息。这有助于用户快速了解模型的组成和规模。
课程,可以说是机器学习入门的第一课和最热门课程,作者在github开源了吴恩达机器学习个人笔记,用python复现了课程作业,成为热门项目,star数达到11671+。由于某种原因,国内用户访问github非常慢,下载资源经常失败,于是,为方便读者,我们把github内容做成镜像文件予以发布,针对非会员无法一次性保存大量文件,我把所有文件压缩成一个iso文件,转存即可,只需5秒即可保存!密码1fi
一、GIT原理【这部分也挺简单,可以看看,如果没时间可以直接跳到第二部分】一、GIT原理【这部分也挺简单,可以看看,如果没时间可以直接跳到第二部分】Git 是一种分布式版本控制系统,用于管理软件项目的源代码。它是由 Linux 之父 Linus Torvalds 开发的,并已经成为了现代软件开发领域中最流行的版本控制系统之一。使用 Git 可以追踪代码的历史修改记录,方便团队协作、代码共享和代码重

WINDOWS系统查看nvidia显卡和CUDA的版本号Win+r+cmd后输入nvidia-smi主要是看Driver Version462.31这个值。2.根据Driver Version的值,对照一下https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html的表,确定你的电脑硬件支持的最高CUDA版本(本电脑Drive
使用Keras.js,可以轻松地生成神经网络模型的摘要。摘要提供了模型的层级结构、层级名称、输出形状和可训练参数数量等信息。这有助于用户快速了解模型的组成和规模。
图像本身的变化将有助于模型对未见数据的泛化,从而不会对数据进行过拟合。以上整理的都是我们常见的数据增强技术,torchvision中还包含了很多方法,可以在他的文档中找到:https://pytorch.org/vision/stable/transforms.html。