




- @qq_45041871
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在这项工作中,我们只通过在ImageNet上训练产生具有竞争力的无卷积的transformer模型。我们只用了不到三天的时间在一台电脑上训练他们。在没有外部数据的情况下,我们的vision transformer(86M参数)在ImageNet上达到了83.1%(单一模型)的top-1精度。我们提出了一种基于token的蒸馏方式,极大的提升了模型的性能。

python3安装mmseg库常见安装方法(错误的)正确的方法常见安装方法(错误的)pip install mmseg结果会出现问题,一直提示报错。具体报错示例如下图所示,网上很难找到有效地解决方法。可能不同的环境会有不同的报错信息。网上一个python内置库下载,发现只有python2版本的,链接后面所示python库下载地址正确的方法其实mmseg库是缩写,要安装时必须写明全称mmsegmen
本文通过回顾最先进的方法,特别是基于深度学习模型的通用领域事件抽取,填补了综述类文献空白据任务定义,本文为当前通用领域事件抽取研究的引入了一种新的文献分类。然后,我们总结了事件抽取方法的范式和模型,然后详细讨论了每一种方法。作为一个重要方面,本文总结了支持预测和评估指标测试的基准。还对不同方法进行了全面比较。最后,总结了该研究领域未来的研究方向。

以往的研究大多致力于从单个句子中抽取事件,而文档级别的事件抽取仍未得到充分的研究。在本文中,我们专注于从整个文档中抽取事件论元,主要面临两个关键问题:1)触发词与语句论元之间的长距离依赖关系;B)文件中一个事件的分散在上下文中。为了解决这些问题,我们提出了一个TSAR。TSAR通过双流编码模块从不同角度对文档进行编码,以利用本地和全局信息,并降低分散在上下文的影响。此外,TSAR还引入了基于局部和
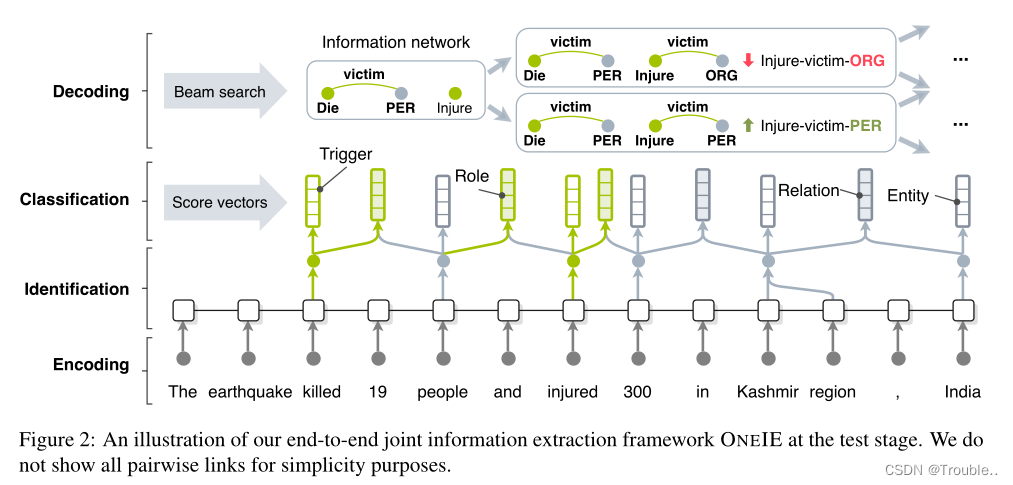
A Joint Neural Model for Information Extraction with Global Features论文解读,一种新型的联合实体、关系、事件抽取模型
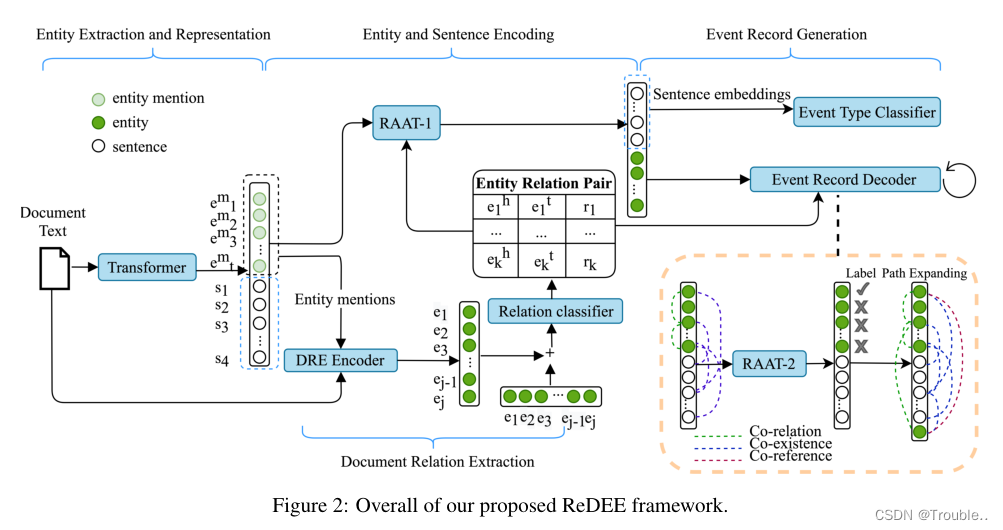
在文档级事件提取(DEE)任务中,事件论元总是分散在句子之间(跨句子问题),多个事件可能位于一个文档中(多事件问题)。在本文中,我们认为事件论元的关系信息对于解决上述两个问题具有重要意义,并提出了一个新的DEE框架,该框架可以对关系依赖进行建模,称为关系增强文档级事件提取(ReDEE)。更具体地说,这个框架的特点是一个新颖的、量身定制的transformer,称为关系增强注意transformer
Is attention better than matrix decomposition论文解读,阐述了一种新的attention机制,这种机制效果非常明显,在22年的语义分割上已经的得到证明,已经刷新的语义分割的sota

python3安装mmseg库常见安装方法(错误的)正确的方法常见安装方法(错误的)pip install mmseg结果会出现问题,一直提示报错。具体报错示例如下图所示,网上很难找到有效地解决方法。可能不同的环境会有不同的报错信息。网上一个python内置库下载,发现只有python2版本的,链接后面所示python库下载地址正确的方法其实mmseg库是缩写,要安装时必须写明全称mmsegmen
YAKE!无监督关键字抽取算法
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为p和1−p,此时表达式为( 的log底数是eLN1i∑LiN1i∑−yi⋅logpi1−yi⋅log1−pi)]yiipii由于二分类交叉熵很容易理解,在此就不做举例了。
