写文章




- @qq_44799766
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
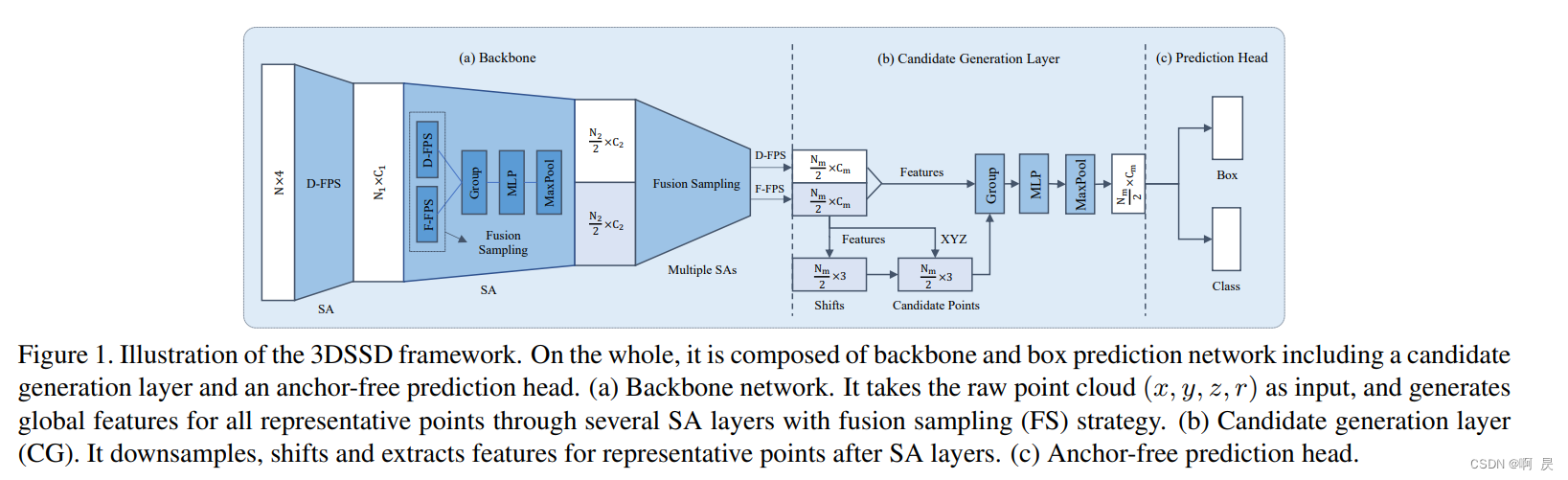
3D目标检测(基于点云)——3DSSD
3DSSD论文阅读及个人分析。
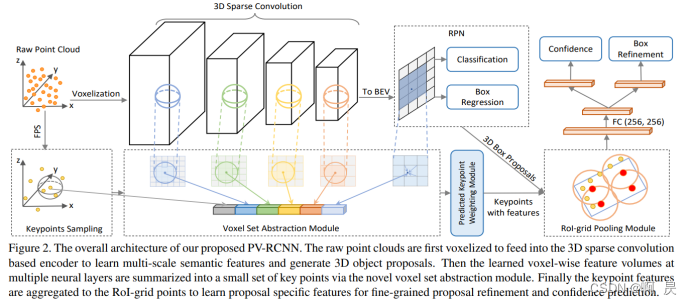
3D目标检测(点云+体素)——PV-RCNN
PV-RCNN论文阅读及个人分析。
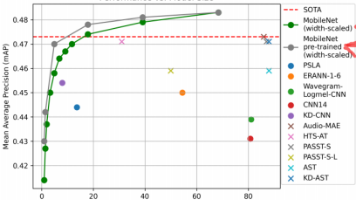
音频分类-----Efficient Pre-Trained CNNs for Audio Pattern Recognition (EfficientAT)复现及tensorflow架构下推理
本文介绍了作者在音频分类任务中的实践,重点关注环境声音分类的工程化实现。作者使用EfficientAT模型,通过知识蒸馏方法将Transformer模型的能力迁移到轻量级CNN上,并结合动态卷积技术提升性能。针对公司内部数据样本不均衡问题,采用自定义CBLoss损失函数进行优化。为实现TensorFlow架构下的部署,作者将PyTorch前处理代码复写成TensorFlow版本,并将训练好的模型转
简述YOLOv8与YOLOv5的区别
yolov7,yoloX相关论文还没细看,yolov8就出来了。太卷了!YOLOv5和YOLOv8的区别。
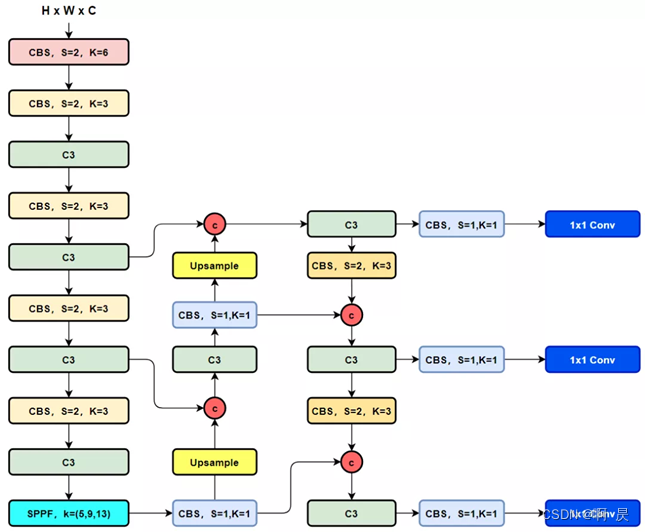
SiamFC代码讲解,推理测试讲解
以代码+注释的形式,详解siamfc的推理过程。后续会详解siamfc的训练过程。
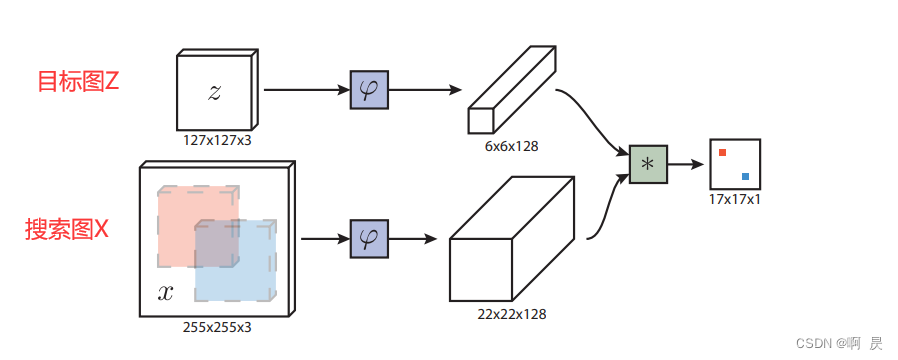
SiamRPN代码讲解,训练过程讲解
以代码+注释的形式,详解siamrpm的训练过程。
SiamFC代码讲解,训练过程讲解
以代码+注释的形式,详解siamfc的训练过程。
SiamRPN代码讲解,推理测试讲解
以代码+注释的形式,详解siamrpm的推理过程。后续会详解siamrpn的训练过程。
ViTAE论文阅读与官方代码讲解
论文部分片段阅读与官方代码讲解
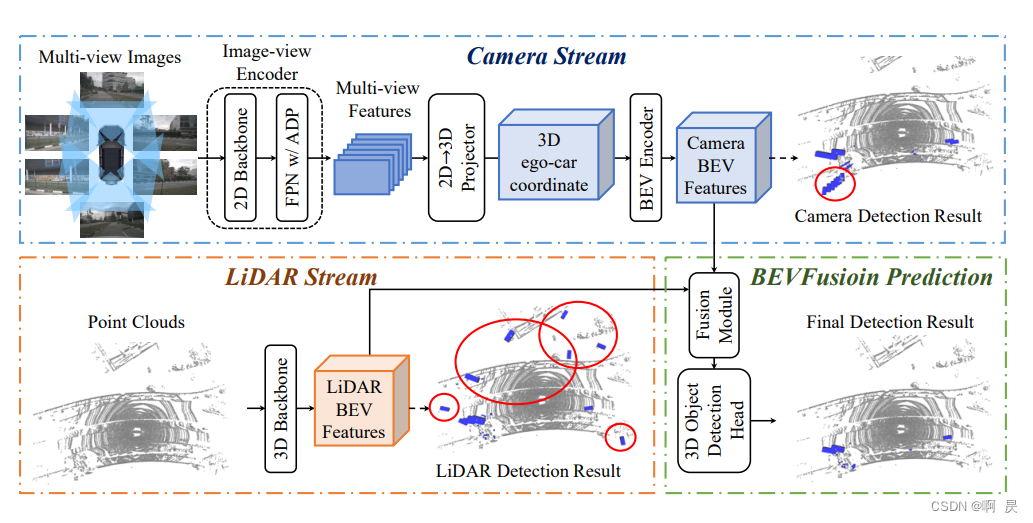
BEV感知---BevFusion详解
一种非常经典的多模态融合感知方案叫 BEVFusion。这是一种用于多任务多传感器 3D 感知的高效通用框架。BEVFusion 将相机和 LiDAR 功能统一在共享 BEV 空间中,完全保留几何和语义信息。相机和点云分支没有明显的主次关系,相互独立,结果上又相辅相成。高效、准确的多传感器感知对于自动驾驶汽车的安全至关重要。BEVFusion 将最先进的多传感器融合模型的计算成本降低了一半,并在小