




- @qq_44386182
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
输入timeColSer销售时间这一列,Series数据类型,例‘2018-01-01星期五’输出分割后的时间,返回Series数据类型,例‘2018-01-01’统计月均消费次数(同一天一个人的所有消费算作一次消费)转换日期过程中不符合日期格式的数值会被转换为空值。其中,商品编码就是商品名称这两列数据重复。将'销售数量'这一列小于0的数据排除掉。以下可知购药时间和社保卡号存在缺失值。定义函数分割

案例主要用来熟悉pandas库和与mysql的连接知识1首先建立连接导入MySQL中的数据 代码如下2将我们需要分析的列的数据 对列重命名改成中文名打印结果(中文名字就是我们要分析的数据列)计算收入打印结果如下查看下单时间这一列结果获取八月的天数量度和星期量度打印结果weekday_name为订单所处在星期几,0代表星期一,以此类推计算最小销售额的日期为16日最小销售额为4447销售额随时间天数日

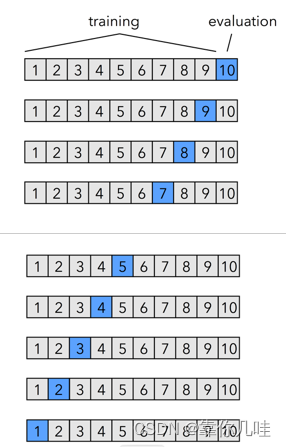
简单交叉验证方法:将原始数据集随机划分成训练集和验证集两部分。比如,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。缺点:(1)数据都只被所用了一次,没有被充分利用(2)在验证集上计算出来的最后的评估指标与原始分组有很大关系。代码k折交叉验证 为了解决简单交叉验证的不足,提出k-fold交叉验证。1、首先,将全部样本训练集划分成k个大小相等的样本子集;
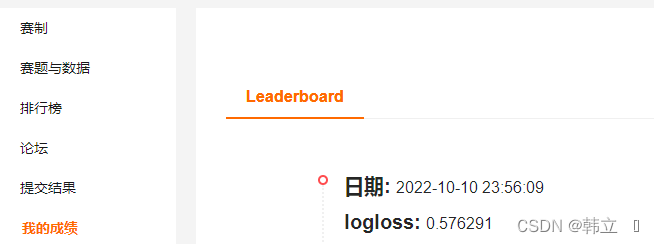
注:对训练集和测试集中api种类统计发现不完全重合(有很大交集),因此,删除训练集中独有的三种api信息。并特征选取时采用训练集特征构建测试集的c和d类特征(这样对数据有一定的浪费)c:对api调用tid的次数统计形成特征(采用pd.pivot_table)2:采用的算法:LGB(其它算法未怎么尝试,先练练手,熟悉流程)b:对数值字段采用mean,max,min等函数生成数值特征。后续可改进的地方
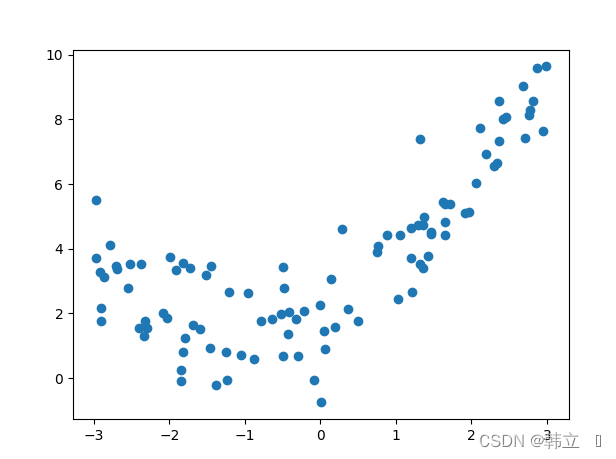
3:采用二次多项式拟合(原理见本人博客应用统计学) (pipeline封装注释里有说明解释)并查看R2分数。注:以上案例只是测试了一元回归在训练集上的线性回归效果以及多项式回归效果,其中用到了管道封装原理。注:至于为什么误差满足高斯分布这是数学家的问题,作为技术人员,只要知道会用即可。6:评价模型拟合好不好的方法:R平方:其实就是相关系数的平方:取值在0到1之间。注:1:梯度概念:对各个自变量的偏
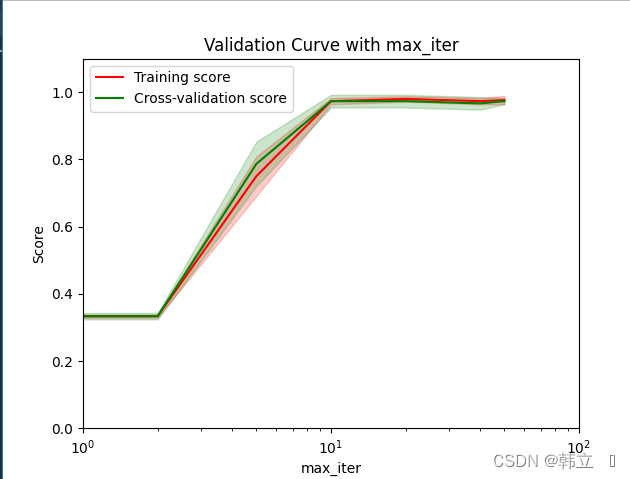
需要注意的是如果我们使用验证分数来优化超参数,那么该验证分数是有偏差的,它无法再代表模型的泛化能力,我们就需要使用其他测试集来重新评估模型的泛化能力。验证曲线和学习曲线的区别是,横轴为某个超参数的一系列值,由此来看不同参数设置下模型的准确率(评价标准),而不是不同训练集大小下的准确率。从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的设置,来提高模
先给出结论:利用信息增益的目的是为了生成最优决策树,方便在测试集预测首先给出书上信息熵的数学定义:举一个通俗例子理解这个公式 接下来理解信息增益书上公式光看公式很难理解 但是其实并没有新的数学概念知识(理解公式的目的是获取其现实意义和其现实逻辑)先给出结论:信息增益其实就是系统经过特征选择后(比如该例选择色泽为特征),过度为下个子系统,子系统与上一个系统的信息熵差值的一个量度,当然越大,说明系统不

4:假如从2010 1.1 开始, 每月第一个交易日买入一手股票,每年最后一个交易日卖出所有股票, 到今天为止,我们受益如何?4:假如从2010 1.1 开始, 每月第一个交易日买入一手股票,每年最后一个交易日卖出所有股票, 到今天为止,我们受益如何?其次,读取k线数据,并保存下来,然后重新读取并完成目标2。3:输出该股票所有开盘比前日收盘跌幅超过2%的日期。3:输出该股票所有开盘比前日收盘跌幅超
输入timeColSer销售时间这一列,Series数据类型,例‘2018-01-01星期五’输出分割后的时间,返回Series数据类型,例‘2018-01-01’统计月均消费次数(同一天一个人的所有消费算作一次消费)转换日期过程中不符合日期格式的数值会被转换为空值。其中,商品编码就是商品名称这两列数据重复。将'销售数量'这一列小于0的数据排除掉。以下可知购药时间和社保卡号存在缺失值。定义函数分割
简单交叉验证方法:将原始数据集随机划分成训练集和验证集两部分。比如,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。缺点:(1)数据都只被所用了一次,没有被充分利用(2)在验证集上计算出来的最后的评估指标与原始分组有很大关系。代码k折交叉验证 为了解决简单交叉验证的不足,提出k-fold交叉验证。1、首先,将全部样本训练集划分成k个大小相等的样本子集;