- @qq_43170312
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
达梦数据库踩坑合集
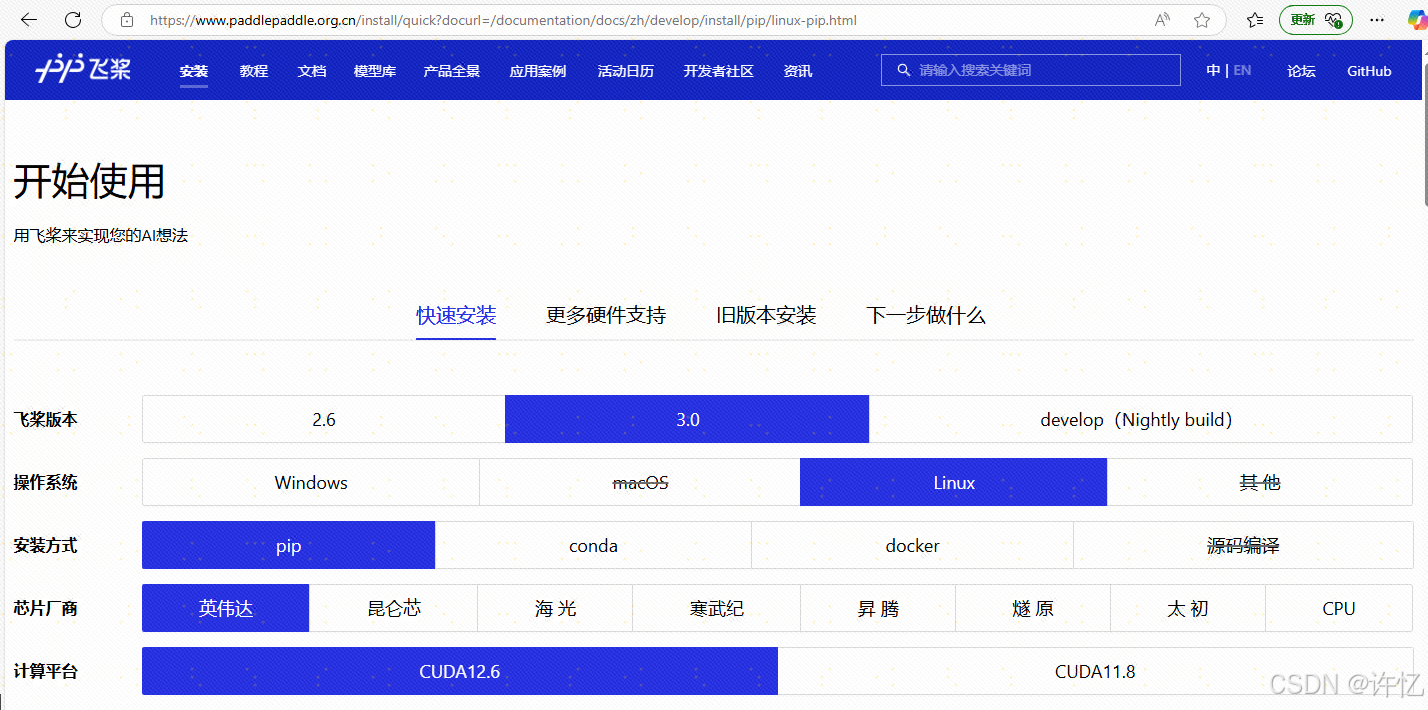
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。如果你的设备是 GPU,请使用以下命令安装 PaddleX 的 GPU 版本。使用 PaddleX 官方 Docker 镜像,创建一个名为 paddlex 的容器,并将当前工作目录映射到容器内的 /paddle 目
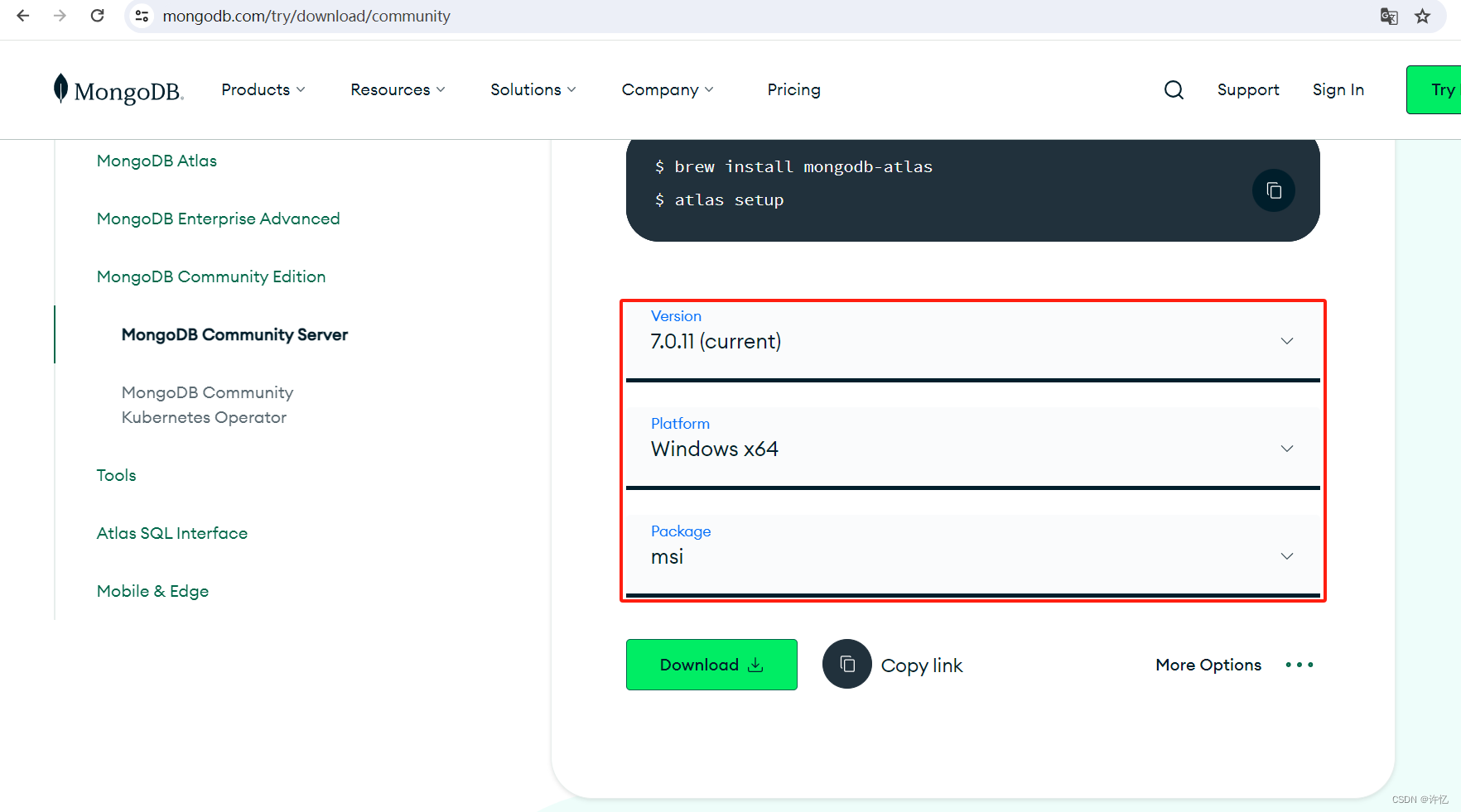
安装时需要勾选Install MongoDB Compass,安装图形化界面。选择需要的版本进行安装。点击下载下来的msi文件,根据指引默认安装。在application.properties中配置。如果想要更便捷,可以使用docker下载安装。在已有的Spring boot的项目中添加依赖。,在上面的msi包安装过程中选择就会安装。在Navicat中创建MongoDB连接。新建查询,选择使用的d
Java统计年月日的数据量(使用MYSQL)
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。如果你的设备是 GPU,请使用以下命令安装 PaddleX 的 GPU 版本。使用 PaddleX 官方 Docker 镜像,创建一个名为 paddlex 的容器,并将当前工作目录映射到容器内的 /paddle 目
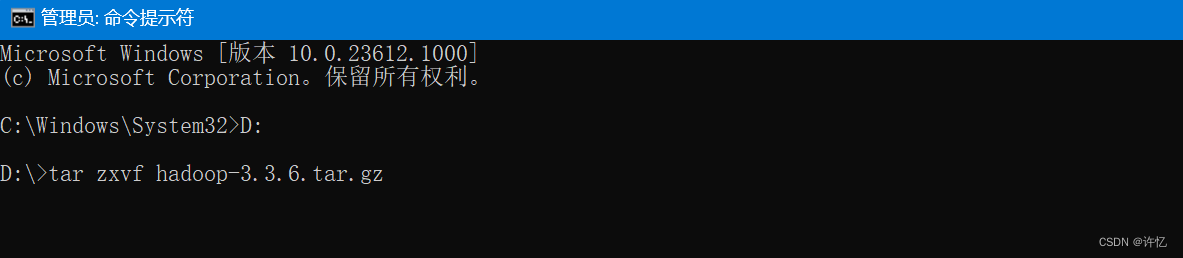
Apache官网:https://spark.apache.org/将下载好的hadoop-3.3.6.tar.gz包,放到想要安装的目录,我这里是放在D盘(D:\hadoop-3.3.6.tar.gz)解压hadoop-3.3.6.tar.gz文件【注意:需要在cmd中以管理员身份运行】进入文件目录等待执行结束配置HADOOP_HOME环境变量,进入 此电脑 -> 右键 -> 属性 -> 高级系