




- @qq_42066648
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
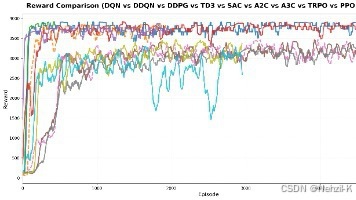
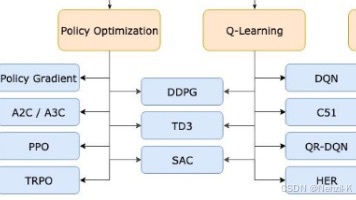
本文介绍了一个基于深度强化学习的车辆横向控制项目RL-DQN-Vehicle。该项目实现了完整的车辆控制系统,支持10种强化学习算法(DQN、DDQN、DDPG等)和4种赛道类型(圆形、正弦等),提供从训练到评估的全流程功能。系统基于自行车运动学模型,具有模块化设计、详细注释和可视化功能,适用于教学、研究和工程应用。项目支持离散/连续动作空间,提供训练曲线、轨迹动画和性能指标等可视化输出。环境要求
模型预测轮廓控制(MPCC)在车辆极限避障中的应用 摘要 本文提出一种基于非线性单轨车辆模型的模型预测轮廓控制(MPCC)方法,用于解决自动驾驶车辆在极限工况下的避障控制问题。该方法创新性地将运动规划、路径跟踪和车辆稳定性控制集成到统一框架中,采用笛卡尔坐标系和轮廓误差概念克服了传统Frenet坐标系的距离高估问题。控制器使用非线性单轨车辆模型结合Fiala轮胎模型精确描述极限工况下的车辆动力学,
CILQR算法摘要(≤150字): CILQR是一种约束优化算法,结合iLQR高效性和约束处理能力,适用于自动驾驶轨迹规划。算法核心为:1)采用运动学自行车模型描述车辆状态演化;2)构建包含轨迹跟踪、控制平滑和约束满足的代价函数;3)通过迭代线性化求解,每次迭代计算状态/控制雅可比矩阵,执行后向传播获得反馈增益,前向传播更新轨迹,辅以线搜索确保收敛。算法优势在于高效处理多种约束(道路边界、障碍物等
提出首个深度学习模型,能通过强化学习直接从 原始像素 成功学习控制策略。模型为 卷积神经网络 + Q学习变体,输入像素,输出估计未来奖励的值函数。该方法在7款雅达利2600游戏上 无架构/超参改动 即可复用,在6款游戏上超越既有方法、3款游戏 超越人类专家。🚀
本文将深度Q学习的思想扩展至 连续动作领域,提出一种 基于确定性策略梯度的无模型演员-评论家算法,可在连续动作空间上运行。依托统一的 学习算法/网络架构/超参数,算法稳健解决 20+ 模拟物理任务,并找到可与 完全访问动力学的规划器 相媲美的策略。同时验证了多类任务可实现 端到端像素输入学习。🚀核心改进 🔑:通过 经验回放 + 软目标网络 稳定训练,结合 OU 探索噪声、批归一化 与统一超参/
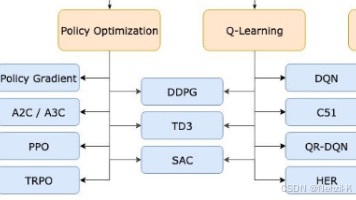
摘要: 相对策略优化算法(GRPO)是面向大型语言模型(RLHF)的高效强化学习改进方法。该算法通过移除价值网络,改用组内平均奖励作为基线,显著降低50%的训练资源消耗(显存与计算成本)。核心创新包括:1)组内相对基线——对同一问题采样多组输出,以组内平均奖励替代价值网络;2)独立KL正则化——将KL散度惩罚从奖励函数分离,提升调参直观性;3)裁剪机制——继承PPO的梯度约束策略。在数学推理任务(
置信域策略优化(TRPO)是一种强化学习算法,旨在通过引入单调改进保证来稳定策略优化过程。该算法通过以下关键创新实现高效训练: 理论保证:通过替代目标函数和KL散度约束,确保每次策略更新都能带来性能提升或至少不降低性能。 实用算法: 使用共轭梯度法高效求解自然梯度方向 引入线搜索机制确保约束满足 提供单路径(无模型)和藤蔓(仿真环境)两种采样方法 应用效果:TRPO能够直接训练大规模神经网络策略,
计算机网路第一章基本知识总结