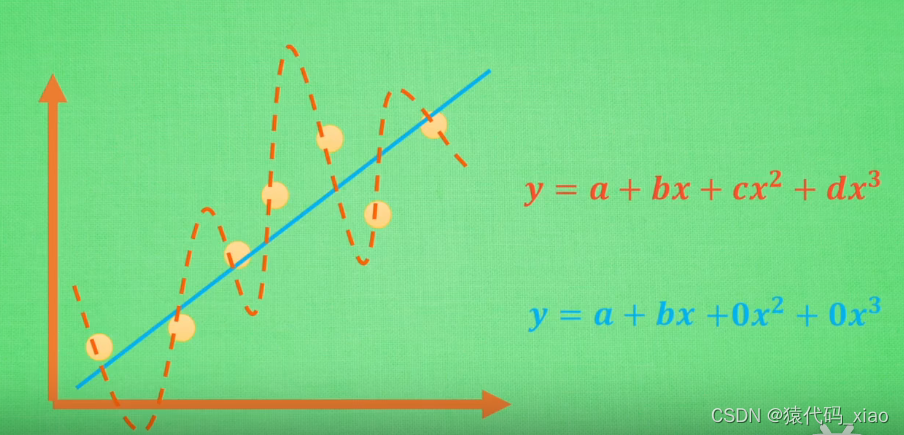- @qq_41318914
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
计算机科学与技术、网络空间安全、电子信息初试及复试科目如下:由于学校的调整,最终的招生计划、一志愿复试人数、复试最低分如下:招生计划、一志愿复试人数、复试最低分:
很多系统在刚开始都把docker安装在系统盘,但是随着镜像越来越多,数据就可能存不下,所以就需要扩充容量,比如加一个磁盘这种。关于Ubuntu20.04如何挂载4T数据盘,可以参考前面发的文章:https://blog.csdn.net/qq_41318914/article/details/1236237611.首先,默认情况下docker的镜像和容器都是保存在/var/lib/docker下面

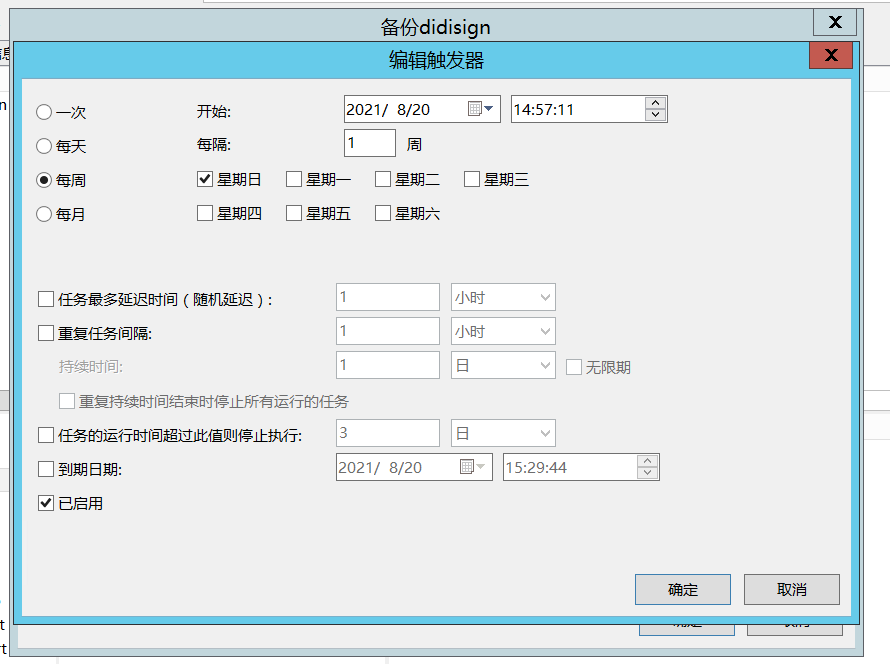
最近的几个项目接二连三遭到一些黑客组织的攻击,虽然项目才刚刚上线,没有什么特别重要的数据,但还是造成了不小的麻烦。在去检查项目漏洞的同时,想到了可不可以定时备份数据库,就像windows里的批处理一样,定时的执行某个任务。1.打开navicat客户端,连上mysql后,双击左边你想要备份的数据库。点击“自动运行”,再点击“新建批处理作业”。2.点击下面的“备份”,然后选择需要备份的数据库,然后双击
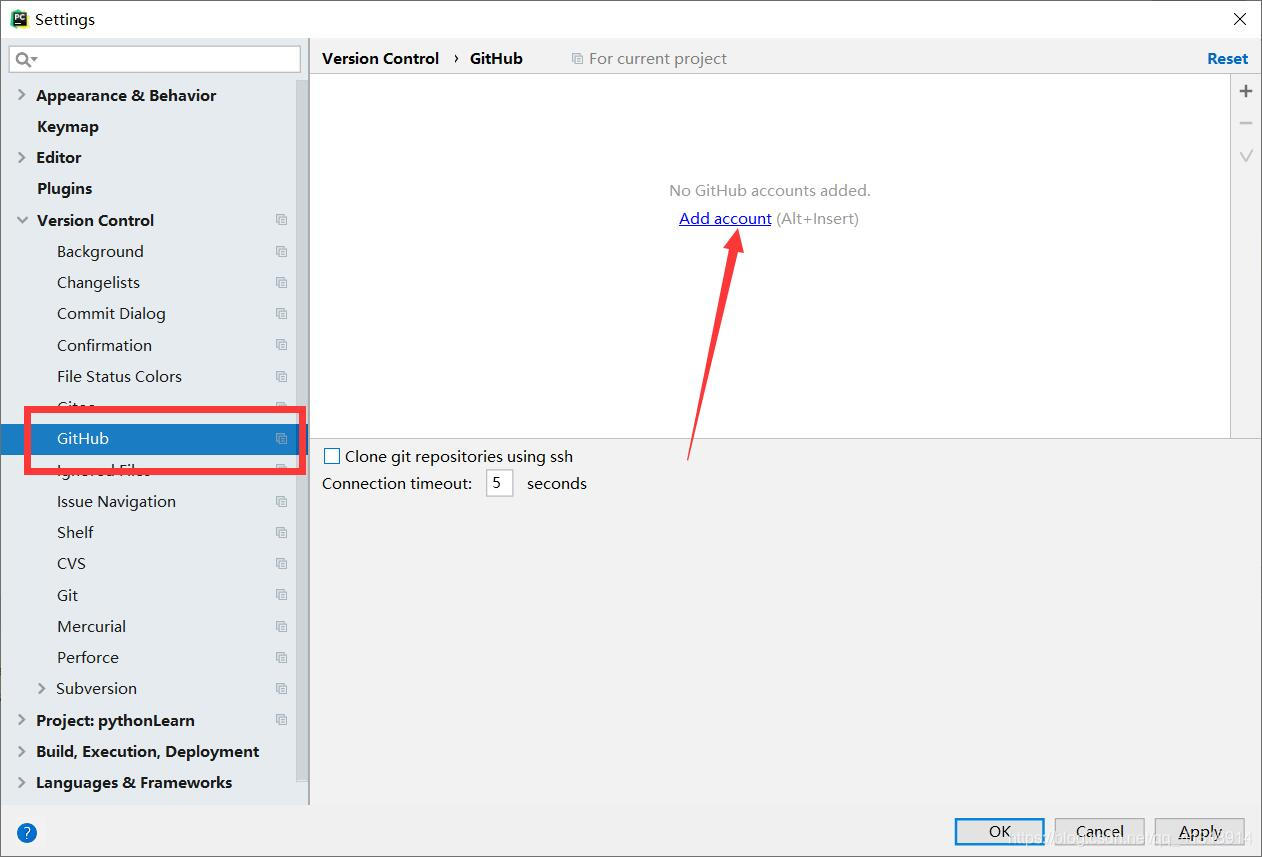
什么是 Github?github是一个基于git的代码托管平台,付费用户可以建私人仓库,我们一般的免费用户只能使用公共仓库,也就是代码要公开。Github 由Chris Wanstrath, PJ Hyett 与Tom Preston-Werner三位开发者在2008年4月创办。迄今拥有59名全职员工,主要提供基于git的版本托管服务。今天,GitHub已是:(1)一个拥有143万开发者的社区。
计算机科学与技术、网络空间安全、电子信息初试及复试科目如下:由于学校的调整,最终的招生计划、一志愿复试人数、复试最低分如下:招生计划、一志愿复试人数、复试最低分:
一.基础知识在理解各种损失函数的选择原理之前,先回顾一下损失函数、模型训练、训练方法的相关基本概念损失函数(Loss Function):用来估量模型的预测值 f(x)与真实值 y的偏离程度,以下是选择损失函数的基本要求与高级要求:基本要求:用来衡量模型输出分布和样本标签分布之间的接近程度,高级要求:在样本分布不均匀地情况下,精确地描述模型输出分布和样本标签之间的接近程度模型训练(Training

一.基础知识在理解各种损失函数的选择原理之前,先回顾一下损失函数、模型训练、训练方法的相关基本概念损失函数(Loss Function):用来估量模型的预测值 f(x)与真实值 y的偏离程度,以下是选择损失函数的基本要求与高级要求:基本要求:用来衡量模型输出分布和样本标签分布之间的接近程度,高级要求:在样本分布不均匀地情况下,精确地描述模型输出分布和样本标签之间的接近程度模型训练(Training
1.L1和L2的区别在机器学习中:- L1 normalization是指向量中各个元素绝对值之和,通常表述为,线性回归中使用L1正则的模型也叫Lasso regularization- L2 normalization指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为,线性回归中使用L2正则的模型又叫岭回归(Ringe regulariza