




- @qq_41094332
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出WritingBench,是面向大语言模型生成式写作的综合评测基准,覆盖6 大核心领域、100 个子领域共1000 条查询(中445/英555),创新采用查询依赖式评估框架,搭配微调的评判模型实现84% 人类对齐率,并通过该框架筛选高质量写作数据训练小模型(Qwen2.5-7B),使其写作能力超越GPT-4o,同时开源基准、评估工具与框架组件以推动 LLM 写作能力研究。
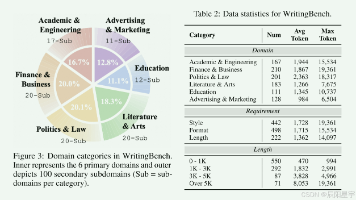
本文提出WritingBench,是面向大语言模型生成式写作的综合评测基准,覆盖6 大核心领域、100 个子领域共1000 条查询(中445/英555),创新采用查询依赖式评估框架,搭配微调的评判模型实现84% 人类对齐率,并通过该框架筛选高质量写作数据训练小模型(Qwen2.5-7B),使其写作能力超越GPT-4o,同时开源基准、评估工具与框架组件以推动 LLM 写作能力研究。
模型应该输出一些与用户查询相关的函数调用(一个或多个),我们不检查此类别中函数调用的正确性(例如,正确的参数值)。● function relevance detection:在函数相关性检测中,设计的场景中所提供的工具都与query不相关,不应该被调用。● Irrelevance detection:在函数相关性检测中,设计的场景中所提供的工具都与query不相关,不应该被调用。● 评估有关预填
LLM中强化学习 RLHF部分学习

softmax函数给出了一个向量yy,我们可以将其视为“对给定任意输入x\mathbf{x}x的每个类的条件概率”。例如,y1\hat{y}_1y1Py猫∣xP(y=\text{猫} \mid \mathbf{x})Py猫∣x。假设整个数据集XYXY具有nnn个样本,其中索引iii的样本由特征向量xixi和独热标签向量yiyi组成。
【代码】基于LangGraph的react_agent的源码解析。
算法介绍Floyd算法用来解决多源最短路径,即可得到图中任意两个结点之间的最短路径。该算法基于动态规划的思想。假设有n个节点,目标是求节点i到达节点j的最短路径。每次求的时候,都将节点i到节点j经过k个节点到达最短路径状态记录下来,即d[k][i][j],意为在状态k下,从节点i经过编号为1、2…k到节点j时路径最短。当要找下一个节点的最短路径时,使用之前已经记录的状态进行对比,可得到新的状态转移
Unsupervised Learning1. Clustering(1)Unsupervised learning introduction无监督学习是针对一组无标签数据集,用算法找到一些隐含在数据中的结构。图中显示出,我们可以用算法找出两簇数据。这些簇的算法也称为聚类算法。(2)K-means algorithm在聚类算法中,我们会给定一组未加标签的数据集。同时,我们也希望能够自动地将这些数据
通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。此外,
其余参考文档:https://www.runoob.com/docker/centos-docker-install.html