




- @qq_38929105
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第二篇:深度学习环境配置指南(Linux-ubuntu16.04)一、安装Anaconda:一、安装Anaconda:Anaconda的简介就不多说了,大家自行百度即可,这里说一下安装。首先下载Anaconda镜像,这里给出几个常用的镜像链接,大家对应着下载,查看。1、Anaconda官网(速度慢,不推荐)2、清华源镜像3、ubuntu系统内核下载(一般在误卸载ubuntu内核后才可能需要用到,血
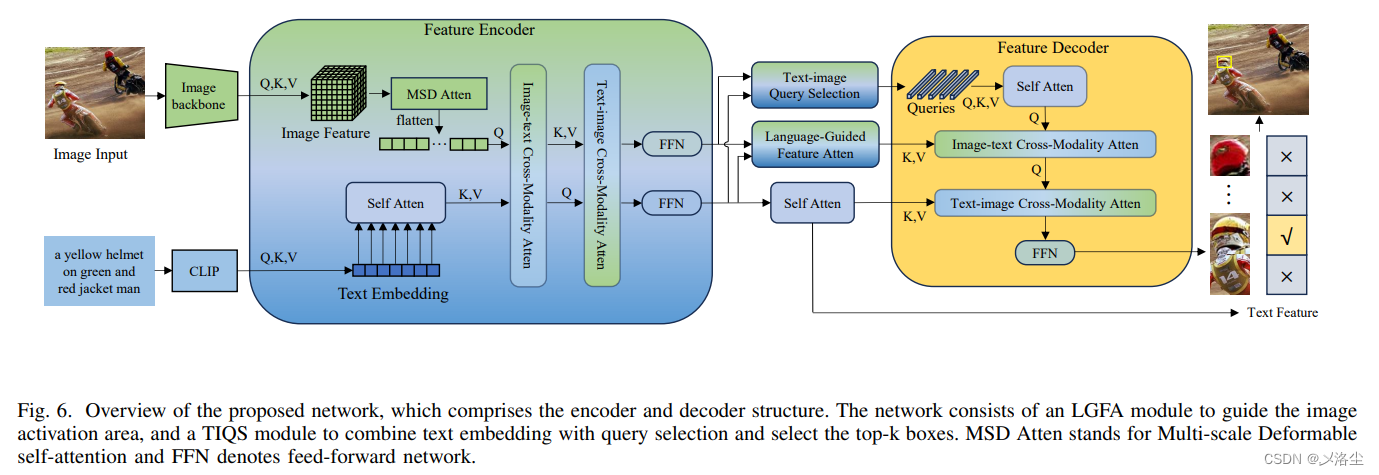
开放词汇检测旨在检测那些未出现在预定词汇中的目标,类似的任务有视觉定位 Visual Grounding (VG)。然而当前的基础模型虽然在很多视觉语言任务上表现很好,但是在开放视觉定位 open-vocabulary visual grounding (OV-VG) 上还没有拿得出手的工作。
重新训练一个参考表达式理解模型 referring expression comprehension (ReC) 以适应新的目标域需要收集参考表达式和相应的 bounding boxes(BBox)。虽然大规模预训练模型在其他的目标域上可能会有用,但是以 Zero-shot 的方式应用在 ReC 这类复杂任务上效果不太好。本文提出一种 Zero-shot 模型 ReCLIP 用于 ReC,其中包含

快速过一篇论文: ReSTR: Convolution-free Referring Image Segmentation Using Transformers,新颖的话也谈不上多新颖,目前的 Transformer 都快烂大街了,其中的一些结构可以借鉴下,说不定是涨点神器。

目标检测+实例分割+姿态估计三合一:LSNet: Location-Sensitive Visual Recognition with Cross-IOU Loss论文笔记一、Abstract二、引言三、相关工作四、方法描述1、Location Sensitive Visual Recognition2、LSNet: A Unified Framework3、Cross IOU Loss4、Pyr

Dealing with Missing Modalities in the Visual Question Answer-Difference Prediction Task through Knowledge Distillation 论文笔记一、Abstract二、引言三、相关工作1、Answer Difference in VQA Datasets2、Generalized Knowled
三行代码计算并输出模型参数量
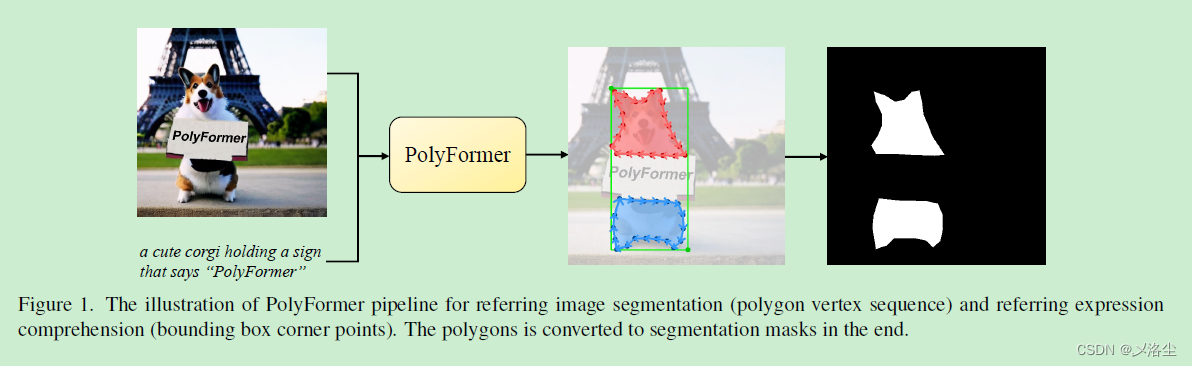
目前的参考图像分割一般不去直接预测目标的 mask,而是作为一个多边形序列生成任务。本文提出来一种能直接预测精确的几何位置坐标的基于回归的解码器,摒弃了之前那种需要将坐标量化到某个固定格子上的做法。不仅在常规的数据集上表现很好,而且泛化到参考视频图像分割上仍然牛皮。
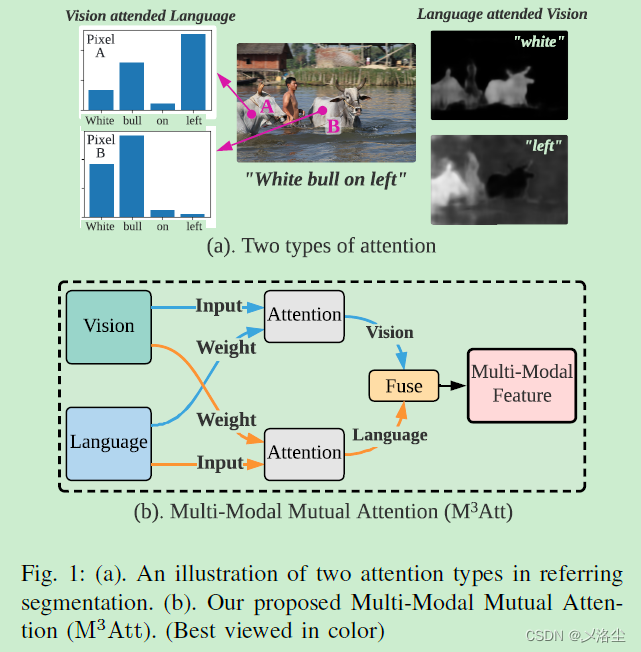
首先指出 Referring image segmentation(RIS)的定义,然后表明问题:最近的方法大量使用 Transformer,其中注意力机制仅采用语言输入作为注意力的权重计算方式,而输出的特征中却并未显式地融合语言特征。介于其输出主要由视觉信息主导,限制了模型全面理解多模态信息,从而导致后续 mask 解码的不确定性。于是本文提出 Multi-Modal Mutual Attent
本文探索基于 Transformer 的网络用于视觉定位。之前方法通常解决的是视觉定位中的核心问题 ,例如采用手工设计的机制进行多模态融合及推理,缺点是方法复杂且在特定数据分布上容易过拟合。于是本文首先提出 TransVG,通过 Transformer 建立起多模态间的关联,并直接通过定位到指代目标来回归出 Box 的坐标。实验表明复杂的融合模块能被堆叠的 Transformer 编码器层替代。
