




- @qq_34184505
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
用户请求接口 /analyze,传入一个文本;FastAPI 处理后,用 Celery 异步任务 模拟调用大模型进行文本分析;分析完成后,调用用户提供的回调地址(比如 /callback)并把分析结果发回去。

注意:事项上面代码在训练完成后没有额外将训练好的模型保存到指定文件夹,模型自动将模型保存在了"/autodl-fs/data/wzs/trained_model/Qwen2.5-VL-3B-Instruct/checkpoint-124",其中尾号。data2csv.py:使用modelscope下载coco_2014_caption数据集,并将其转化为.csv文件。csv2json.py:将得到
【代码】langchain调用多模态大模型。

提问:在我们计算某些数据标准差(或者方差)的时候,会发现有些公式分母是n,而有些公式的分母却是(n-1),那么到底哪个公式才是正确的呢?答案如果是算总体的标准偏差,分母就用n,这就是真实的标准偏差,属于描述统计。如果是算样本的标准偏差,无偏估计是n-1,有偏估计是n。毕竟样本只是用来估量总体的情况,属于推论统计,所以利用样本计算总体个体差异性时候通常会保守估计,除以n-1得出来的标准偏差会比除以n
from PIL import Imageimport osinput_train_path = r"E:\test\BelgiumTSC_Training\Training"output_train_path = r"E:\BelgiumTSC_JPG\Train_data"input_test_path = r"E:\test\BelgiumTSC_Testing\Testing"output
常见的数据类型载体listnp.arraytf.tensorlist: 可以存储不同数据类型,缺点不适合存储较大的数据,如图片np.array: 解决同类型大数据数据的载体,方便数据运算,缺点是在深度学习之前就设计好的,不支持GPUtf.tensor:更适合深度学习,支持GPUTensor是什么scalar: 1.1vector:[1.1] ,[1.1,2.2,……]matrix:[[1,2,3,
其实不然,一个销售区域包含多个省份,每个省份人口基数,人口密度,经济实力,医疗条件都不一样,每个省份对我司产品的贡献值也是不一样的,并且疫情从爆发到现在我国防疫能力,防疫政策都是一个动态变化的过程,像国外的疫情已经是躺平政策,官方已经不在统计疫情相关数据。这个东西是很难被量化的。这并不意味着算法与业务是对立关系,恰恰相反,在“需求预测”不断完善的过程中,二者是相互合作,相互依赖的关系,最终还是服务
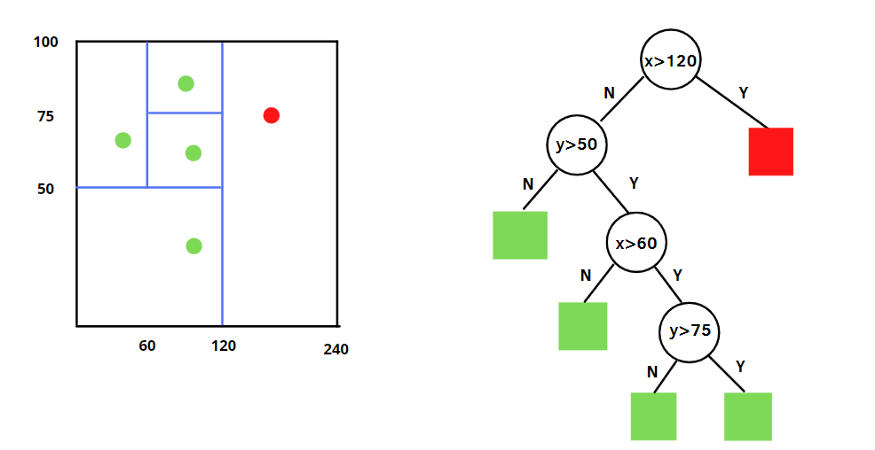
孤立森林(Isolation Forest)是一种基于异常检测的机器学习算法,用于识别数据集中的异常点。孤立森林算法在异常检测、网络入侵检测、金融欺诈检测等领域有广泛应用,并且在处理大规模数据和高维数据时表现出色。孤立森林的基本思想的前提是,将异常点定义为那些。可以理解为分布稀疏,且距离高密度群体较远的点。从统计学来看,在数据空间里,若一个区域内只有分布稀疏的点,表示数据点落在此区域的概率很低,因
上一篇文章介绍了基于卷积神经网络的交通标志分类识别Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow),并且最后实现了一个pyqt5的GUI界面,并且还制作了一个简单的Falsk前端网页实现了前后端的一个简单交互,只能实现单张交通标志图像的分类,没有位置检测功能,并且不支持视频的实时检测识别,总体上来讲较为简单。本文介绍一个交通标志识别的进阶项目–基于Yolov5的交通标志

