- @qq_34160248
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
是时候准备面试和实习了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。智能体评估主要是测试你的 LLM 应用,以确保其性能保持一致。这不是最令人兴奋的话题,但越来越多的公司开始关注它。因此,值得深入研究应该追踪哪些指标来实际衡量这种性能。在推送任何更改
最近春招开始了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新人如何快速入门算法岗、如何准备面试攻略、面试常考点、大模型项目落地经验分享等热门话题进行了深入的讨论。总结链接:近日,OpenClaw 全网爆火,可能也刷爆了各位的朋友圈。OpenClaw 简单来说就是一个可以帮你自动操作电脑的 AI Agent,你能用电脑干什么他就能帮你做什么。: 它能直接调用 Shell
打开页面、识别按钮、自动填表、翻页抓数据,你只要告诉它目标,剩下的它自己搞定。登录状态还能保存,下次继续用。触发方式很自然,直接跟它说"记住Alice负责这个项目",或者"显示项目X的所有成员",它就知道该怎么存、怎么查。它会主动记住你交代过的背景,预判你下一步要干什么,就算上下文快满了,它也会自动把关键信息存下来,重启会话还能恢复状态。电脑没毛病,是你没开游戏,OpenClaw真正的玩法,在Sk

最近春招开始了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新人如何快速入门算法岗、如何准备面试攻略、面试常考点、大模型项目落地经验分享等热门话题进行了深入的讨论。

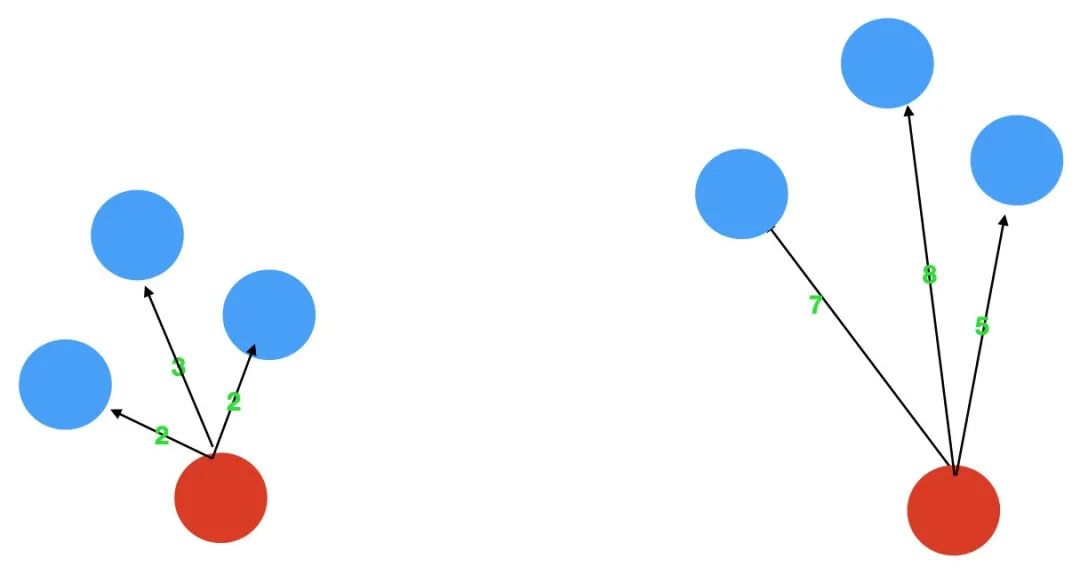
大家好,我们知道 sklearn 库里的 KNN 并没有直接用于异常检测,但是包含了距离计算的函数,所以我们应用PyOD中KNN库进行异常检测,里面基本上也是调用sklearn的函数进行计算,并进行了一些加工。喜欢本文记得收藏、关注、点赞。【注】完整代码、数据、技术交流文末获取。一、图解KNN异常检算法KNN怎么进行无监督检测呢,其实也是很简单的,异常点是指远离大部分正常点的样本点,再直白点说,异
在银行要判断一个"新客户是否会违约",通常不违约的人VS违约的人会是99:1的比例,真正违约的人 其实是非常少的。这种分类状况下,即便模型什么也不做,全把所有人都当成不会违约的人,正确率也能有99%, 这使得模型评估指标变得毫无意义,根本无法达到我们的"要识别出会违约的人"的建模目的。在处理样本不均衡的任务中,使用常规方法并不能达到实际业务需求,正确且尽可能多捕获少数类样本。因为样本不均衡会使得分

相信对于不少的数据分析从业者来说呢,用的比较多的是Pandas以及SQL这两种工具,Pandas不但能够对数据集进行清理与分析,并且还能够绘制各种各样的炫酷的图表,但是遇到数据集很大的时候要是还使用Pandas来处理显然有点力不从心。今天我就来介绍另外一个数据处理与分析工具,叫做Polars,它在数据处理的速度上更快,当然里面还包括两种API,一种是Eager API,另一种则是Lazy API,

今天给大家介绍一款十分强大的数据集探索性分析插件,D-Tale,供我们分析和了解数据集的基本情况,并且支持对数据进行进一步的可视化分析,首先我们先要安装好该模块记得收藏、关注、点赞。注:完整代码、数据、技术交流,文末获取pip install dtale用D-Tale插件打开数据集我们在D-Tale中打开数据集,代码如下import dtaleimport pandas as pddf = pd.

大家好,在机器学习中,很多算法都需要我们对分类特征进行转换(编码)。为了方便讲解,下面创建示例DataFrame数值型数据让我们先来讨论连续型数据的转换,也就是根据Score列的值,来新增一列标签,即如果分数大于90,则标记为A,分数在80-90标记为B,以此类推。自定义函数 + 循环遍历首先当然是最简单,最笨的方法,自己写一个函数,并用循环遍历,那肯定就是一个def加一个fordf1 = df.

大家好,一般在建立时,当我们进行特征工程的工作经常需要对连续型变量进行离散化的处理,也就是将连续型字段转成离散型字段。离散化的过程中,连续型变量重新进行了编码。特征离散化后,模型会更稳定,降低了模型过拟合的风险。本文主要介绍3种常见的特征分箱方法,...